SE464: Software testing and Quality Assurance
Useless class that we have to take. No midterm. Taken with Wei Yi Shang.
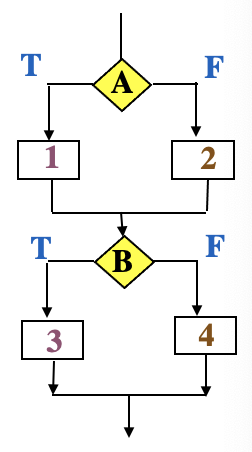
Topic 1: Working with existing tests
- How much does your test cover the code
- How good is existing test?
Topic 2: Writing new tests
- How to write good new test?
- Different types of tests to write beyond Junit
Topic 3: Testing practice during development
- Testing in a release pipeline
- Adapting tests for ever evolving code
Topic 4: Testing in the field
- Logging, A/B testing, Fuzzing, chaos testing
Concepts
- JUnit
- Software Errors
- Software Testing
- Software Quality
- Software Quality Assurance
- Control Flow Graph
- Code Coverage
- Data Flow Graph
- Mutation Testing
- Mocking
- User Interface Testing
Week 11: refactoring, before logging
Assignments
- A3 Mock
- A4 User Interface Testing
- A5 Fuzzing
- A6 Release Pipeline
- A7 Automated Testing Results Analysis
- A8 Load Testing - Performance
Final
Mostly consisted of MCQ and T/F Questions. Had 4 long answer questions that wasn’t worth a lot of marks.
Study using his review slides and consult Patrick’s repo: https://github.com/patricklam/stqam-2019/tree/master for practice.
Week 2
Control Flow
Program Graph
- Given a program written in an imperative programming language, its program graph is a directed graph in which nodes are statement fragments, and edges represent flow of control.
- A complete statement is also considered a statement fragment.
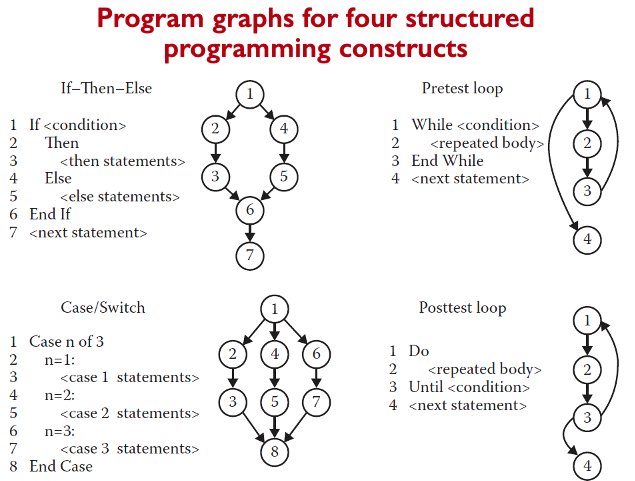
- Each circle is called a node, it corresponds to a statement fragment.
Control Flow Graphs (CFGs)
- A CFG models all executions of a method by describing control structures
- Nodes:
- Statements or sequences of statements (basic blocks)
- Edges:
- Transfers of control. an edge (s1, s2) indicates that s1 may be followed by s2 in an execution.
- Basic Block:
- A sequence of statements such that if the first statement is executed, all statements will be (no branches)
- Intermediate:
- Statements in a sequence of statements are not shown, as a simplification, as long as there is not more than one exiting edge and not more than one entering edge.
CFGs are sometimes annotated with extra information: branch predicates, defs, uses.
CFG Example:
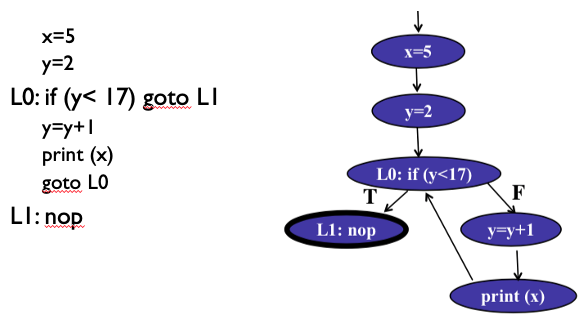 I understand this example.
I understand this example.
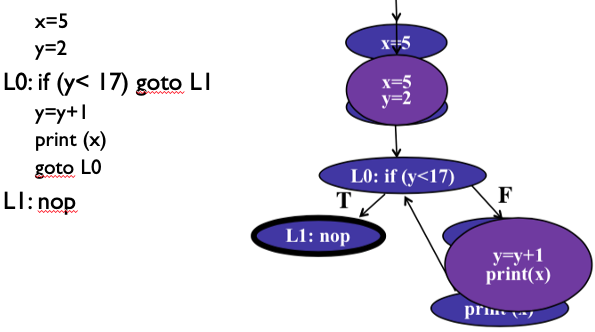
Basic Block
- We can simply a CFG by grouping together statements which always execute together (in sequential programs)
- A basic block has one entry point and one exit point.
CFG Example (continued with basic block):
CFG: The if Statement
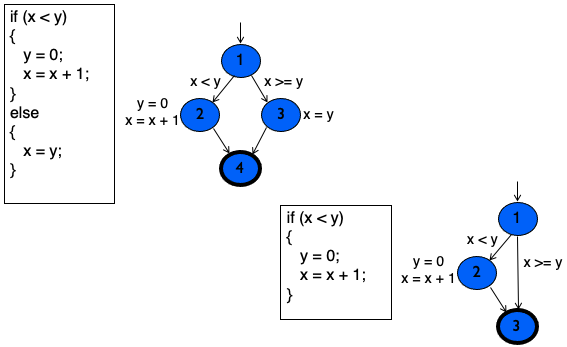
-
Notice, we label the edges to be the conditions, and next to the nodes, we write what it’s executed.
-
From source code to control flow graph - issue about branching
-
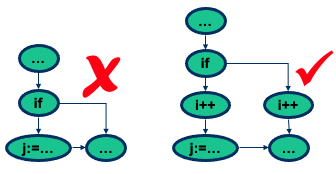
In a control flow graph, nodes corresponding to branching (if, while, …) should not contain any assignments
-
This paramount for the identification of data flow information
CFG: The if-Return Statement
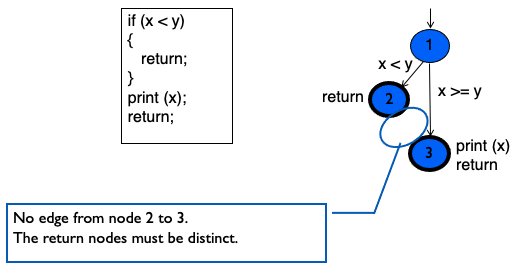
Makes sense, when you return, you do not execute what it is outside of the if() condition if it’s true and went inside.
CFG: while and for Loops
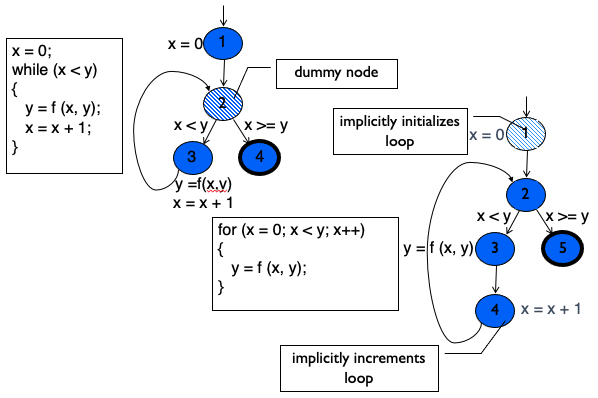
Notice:
For the for loops, there is a node that implicitly initializes the loop and implicitly increments the loop.
CFG: do Loop, break and continue
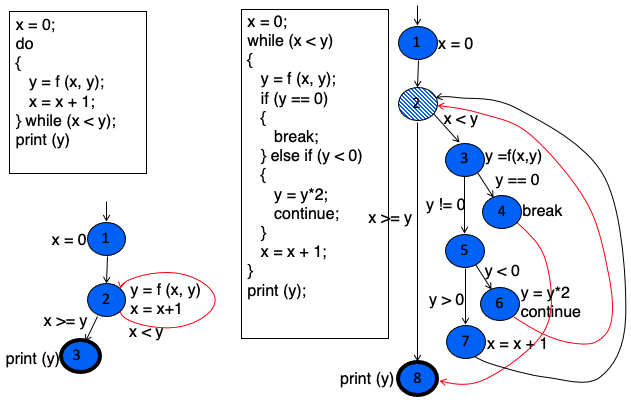
CFG: The case (switch) Structure
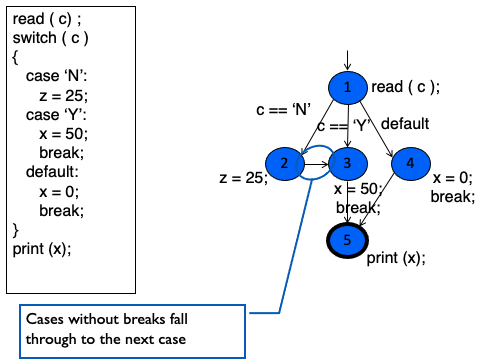
Notice
Cases without breaks fall through the next case.
CFG: Exceptions (try-catch)
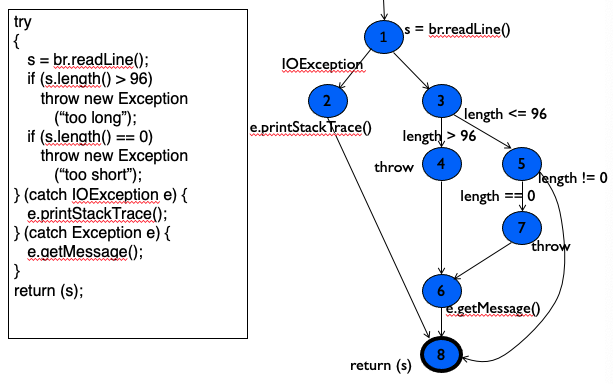
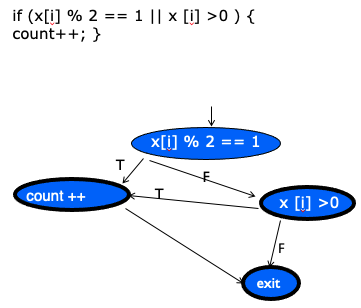
Why is there no line between nodes 1 and 3?
What does the arrow from node 1 to 2 mean? And when would it follow this path?
I don’t understand the flow of this diagram…to-understand
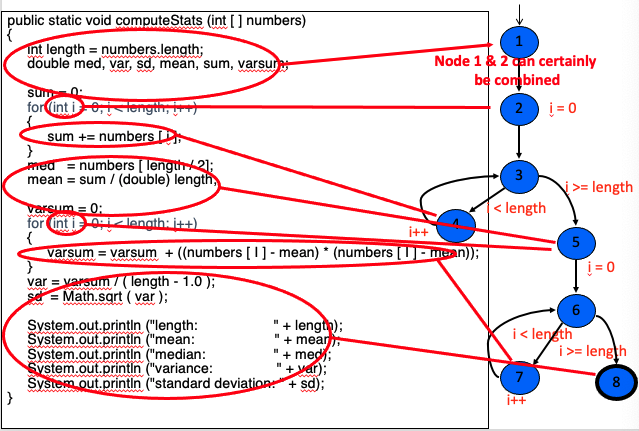
Example Control Flow Stats. Draw it out.
Nodes 1 and 2 could certainly be combined. We just separated them to emphasize two points:
- Initializations have to be included in the graph. They are also defs in data flow. In java, primitive types get default values, so even declarations have implicit definitions.
- The for loop control variable (i) is initialized before the test!

Short circuit
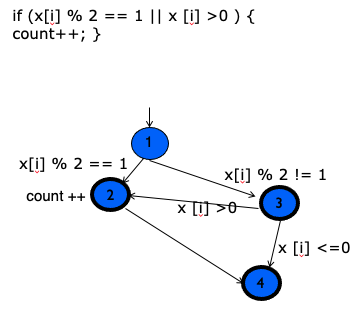
Oh I understand, there is a path that satisfies the first condition in the if statement (1→2). Then we have (1→3) that doesn’t satisfy the first statement, so we have to check the if it satisfies the second statement.
CFG can also be drawn as:

- What’s the purpose of this slide????to-understand
Code Coverage
Code Coverage models
- Statement Coverage
- Segment (basic block) Coverage
- Branch Coverage
- Condition Coverage
- Condition/Decision Coverage
- Modified Condition/Decision Coverage
Statement Coverage:
- Achieved when all statements in a method have been executed at least once
- Faults cannot be discovered if the parts containing them are not executed
- Equivalent to covering all nodes in control flow graph (actual % of coverage would be different)
- Executing a statement is a weak guarantee of correctness, but easy to achieve
- In general, several inputs execute the same statements — important question in practice is how we can minimize test cases?
Statement Coverage Measure
public void printSum(int a, int b){
int result = a + b;
if(result > 0)
System.out.println("red", result);
else if( result < 0)
System.out.println("blue", result);
}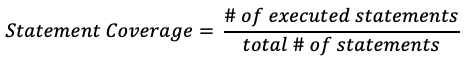
Initially for , , coverage is . After , , coverage is
Segment (basic block) Coverage
- Segment (basic block) coverage counts segments rather than statements
- May produce drastically different numbers
- Assume two segments and
- has one statement, has nine
- Exercising only one of the segments will give or statement coverage
- Segment coverage will be in both case
Statement coverage in practice:
- Statement coverage is most used in industry. Why???
- Typical coverage target is
- Why not aim for ?
- Since there can be dead code, as well sometimes not make sense to test on getter and setter methods
- Why not aim for ?
Statement coverage problems:
- Predicate may be tested for only one value (misses many bugs)
- Loop bodies may only be iterated once
- Statement coverage can be achieved without branch coverage. Important cases may be missed

Statement coverage does not call for testing simple if statements. A simple if statement has no else-clause. To attain full statement coverage requires testing with the controlling decision true, but not with a false outcome. No source code exists for the false outcome, so statement coverage cannot measure it.
If you only execute a simple if statement with the decision true, you are not testing the if statement itself. You could remove the if statement, leaving the body (that would otherwise execute conditionally), and your testing would give the same results.
Since simple if statements occur frequently, this shortcoming presents a serious risk. #to-understand
Branch Coverage
- Achieved when every branch from a node is executed at least once
- At least one true and one false evaluation for each predicate
- Can be achieved with paths in a control flow graph with 2-way branching nodes and no loops
- Even less if there are loops
The “+1” is for the “else” branch, when all the above are not taken
Branch Coverage Measure:

Branch coverage problems:
- Short-circuit evaluation means that many predicates might not be evaluated
- A compound predicate is treated as a single statement. If clauses, combinations, but only are tested
- Only a subset for all entry-exit paths is tested

 ???
???
Condition Coverage
- Condition coverage reports the true or false outcome of each condition.
- Condition coverage measures the conditions independently of each other.
Condition Coverage Measure:

In this case, A and B should be evaluated at least once against “true” and “false”.

Condition/Decision Coverage
- Sometimes also called branch and condition coverage
- It is computed by considering both branch and condition coverage measures


Modified Condition/Decision Coverage (MC/DC)
- Key Idea: test important combinations of conditions and limiting testing costs
- Extend branch and decision coverage with the requirement that each condition should affect the decision outcome independently
- In other words, each condition should be evaluated one time to “true” and one time to “false”, and this with affecting the decision’s outcome
- Often required for the mission-critical systems #to-understand
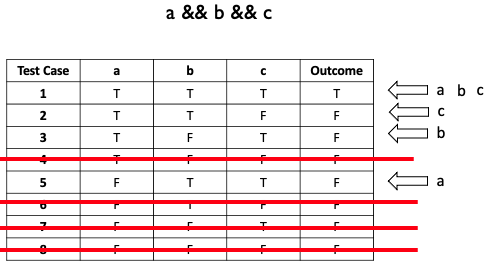
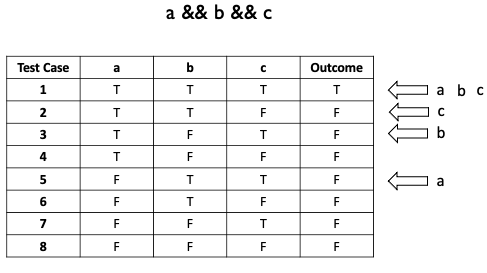
MC/DC Example:
For value of independently, test case 1 and 5 impact the results
For value of independently, test case 1 and 3 impact the results
For value of independently, test case 1 and 2 impact the results
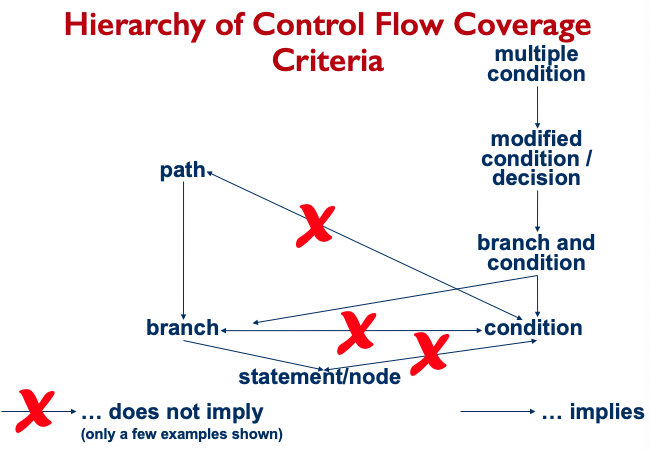
Test Criteria Subsumption
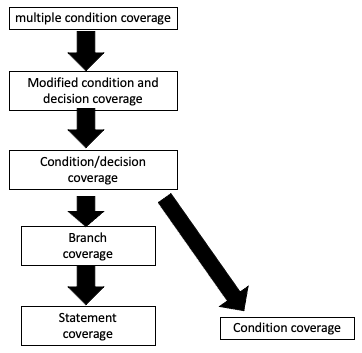 The way to read this is “branch coverage implies statement coverage”.
The way to read this is “branch coverage implies statement coverage”.
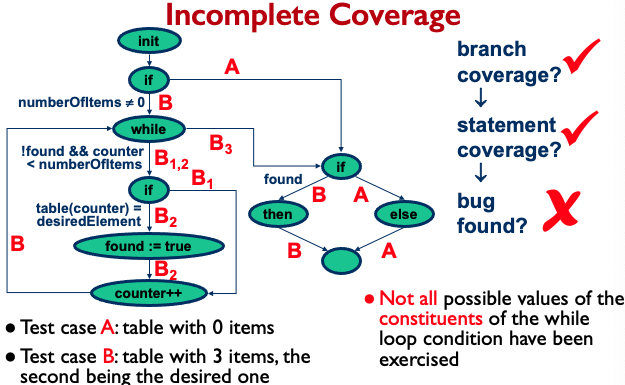
Dealing with Loops
- Loops are highly fault-prone, so they need to be tested carefully
- Simple view: Every loop involves a decision to traverse the loop or not
- A bit better: Boundary value analysis on the index variable
- Nested loops have to be tested separately starting with the innermost
Loop Coverageto-understand
- Minimal coverage should, when possible, execute the loop body:
- Zero times (do not enter the loop)
- Once (do not repeat it)
- Twice or more times (repeat it once or more times)
- Simple loop more extensive coverage, set loop control variable to:
- Minimum - I
- Minimum
- Minimum + I
- Typical
- Maximum - I
- Maximum
- Maximum + I Boundary value analysis for robustness testing.
This will come back in later topics 🙂
- Nested loop
- Start at innermost loop
- Set all the outer loops to their minimum values
- Set all other loops to their typical values
- Test cases for single loop (e.g., minimum, minimum + I, typical, maximum - I, maximum) for the innermost loop
- Move up in nested loop level
- If outermost loop done, do cases for single loop for all loops in the nest simultaneously (i.e., from minimum - I to maximum + I) Base choice for category partitioning, combining several boundary values (keep all but one variable at their nominal values)
- Start at innermost loop
DataFlow
From last class:
Summary
- Statement coverage
- Covering every node in CFG
- Branch coverage
- For every branching node in CFG, at least one true and one false
- Condition coverage
- For every condition in all branching node in CFG, at least one true and one false for each condition
- Condition/decision
- Cover both all branch and all condition
Path Coverage
Path Coverage
- Test case for each possible path
- In practice, however, the number of paths is too large, if not infinite
- Some paths are infeasible
- It is key to determine “critical paths”
- •Test suite 1 = {<x=0, z=1>, <x=1, z=3>} (executes all edges but does not show risk of division by 0)
- Test suite 2 = {<x=0, z=3>, <x=1, z=1>} (would find the problem by exercising the remaining possible flows of control through the program)
- Test suite I Test suite 2 all paths covered

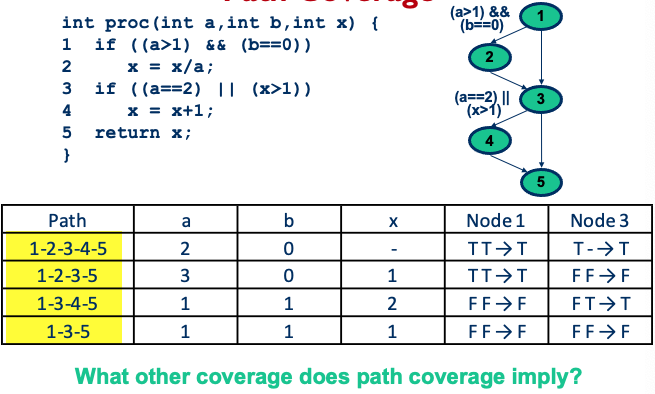
Exercise: Path Coverage Show that path coverage does not imply condition coverage by changing the if statement below:
if (a > 0)
x = 1;
else
x = 2;
end if;Path coverage: condition coverage
Now show that condition coverage does not imply path coverage by changing the if statement.
Data flow and coverage
Data flow analysis
- CFG paths that are significant for the data flow in the program
- Focuses on the assignment of values to variables and their uses, i.e., where data is defined and used
- Analyze occurrences of variables
- Definition occurrence: value of variable is referred
- Use occurrence: variable used to decide whether predicate is true
- Computational use: compute a value for defining other variables or output value
Definitions and Uses:
- A program written in a programming language such as C and Java contains variables
- Variables are defined by assigning values to them and are used in expressions
- Statement defines variable and uses variables and
- Statement
scanf("%d %d", &x, &y)defines variablesxandy - Statement
printf("Output: %d \n", x + y)uses variablesxandy
Pointers
- Consider the following sequence of statements that use pointers:
z = &x;
y = z + 1;
*z = 25;
y = *z + 1;- 1st statement: defines a pointer variable
zbut does not usex - 2nd statement: defines
yand usesz - 3rd statement: defines
xaccessed through the pointer variablez - 4th statement: defines
yand usesxaccessed through the pointer variablez
Arrays
- Arrays are also tricky – consider the following declaration and two statements in C:
int A[10];
A[i] = x + y;- 2nd statement: defines
Aand usesi,x, andy - Alternative view for 2nd statement: defines
A[i], not the entire arrayA(the choice of whether to consider the entire arrayAas defines or the specific element depends upon how stringent the requirement is for coverage analysis) - The same kind of reasoning also applies to fields of a class
First statement, whether A[10] is a def, not a clear answer ⇒ depending on language and Compiler.
c-use
Uses of a variable that occur within an expression as part of an assignment statement, in an output statement, as a parameter within a function call, and in subscript expressions, are classified as c-use, where the “c” in c-use stands for computational.
How many c-uses of
xcan you find in the following statements?
z = x+1; A[x+1] = B[2]; foo(x*x); output(x)
In general, a definition of
A[E]is interpreted as a c-use of variables inEfollowed by a def ofAIn general, a reference to
A[E]is interpreted as a use of variables inEfollowed by a use ofAThere are one / one / two / one c-uses of x.
p-use
The occurrence of a variable in an expression used as a conditional in a branch statement such as an
ifand awhile, is considered as a p-use, where the “p” in p-use stands for predicate.
How many p-uses of
zandxcan you find in the following statements?
if(z>0) (output(x)}; while(z>x){...}There are 2 p-uses of z and 1 p-use of x (and another c-use of x). Since
output(x)is c-use ofx.
p-use: Possible Confusion
- Consider the statement:
if(A[x+1]>0) {output(x)};- The use of
Ais clearly a p-use Is the use ofxin the subscript, a c-use or a p-use???? The use of x is definitely a c-use because it is used in the computation of the index. However, it is also a p-use, because it affects which array element is used in the condition. C-use⇒p-use
- The use of
Basics of Data Flow Analysis
- Variable definition:
- d(v, n): value is assigned to at node (e.g., LHS of assignment, input statement)
- Variable use, i.e., variable reference:
- c-use(v ,n): variable v used in a computation at node n (e.g., RHS of assignment, argument of procedure call, output statement)
- p-use(v, m, n) variable v used in predicate from node m to n (e.g., as part of an expression used for a decision)
- Variable kill:
- k(v, n): variable v deallocated at node n
 I understand what it’s doing, but it might be easier to draw it out with with circles with numbers.
I understand what it’s doing, but it might be easier to draw it out with with circles with numbers.
Data Flow Anomalies:
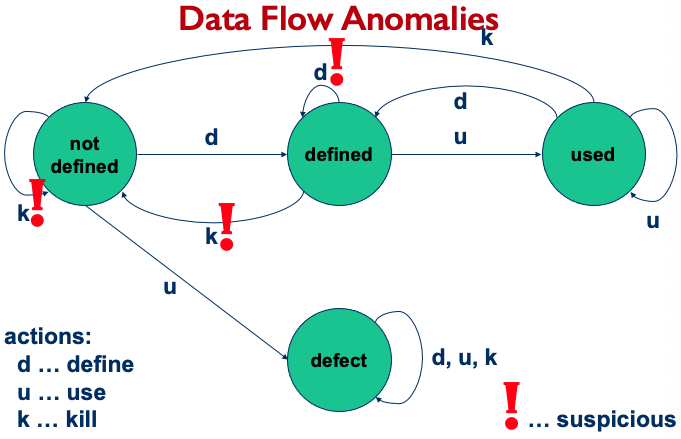
Data Flow Actions Checklist
- For each successive pair of actions
- dd suspicious
- dk probably defect
- du normal case
- kd okay
- kk probably defect (undefined behaviour)
- ku a defect
- ud okay
- uk okay
- uu okay
- First occurrence of action on a variable:
- k suspicious
- d okay
- u suspicious (may be global)
- Last occurrence of action on a variable:
- k okay
- d suspicious (defined but never used after)
- u okay (but maybe deallocation forgotten)
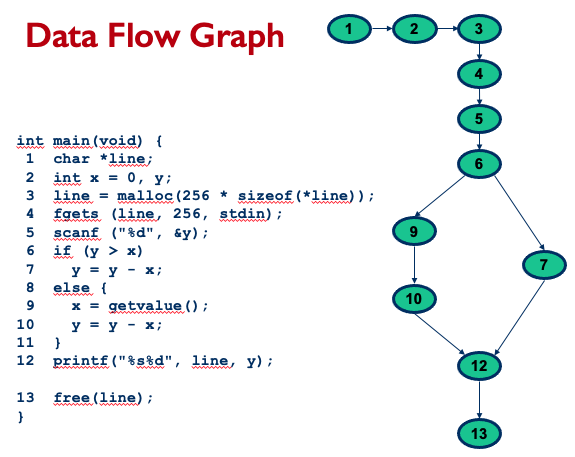
Data Flow Graph
Data Flow Graph
A data flow graph (DFG) of a program, also known as def-use graph, captures the flow of definitions (also known as defs) and use across basic blocks in a program.
- It is similar to a control flow graph of a program in that the nodes, edges, and all paths in the control flow graph are preserved in the data flow graph
- Annotate each node with def and c-use as needed, and each edge with p-use as needed
- Label each edge with condition which when true causes the edge to be taken
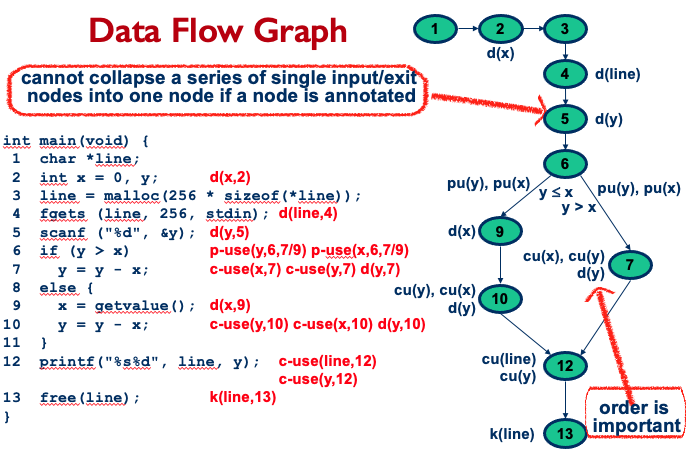
Note
- Cannot collapse a series of single input/exit nodes into one node if a node is annotated
- Order is important if you have several p(), d(), c() in a node.
Exercise: DFG for Factorial
1 public int factorial(int n){
2 int i, result = 1;
3 for (i=2; i£n; i++) {
4 result = result * i;
5 }
6 return result;
7 }Answer:
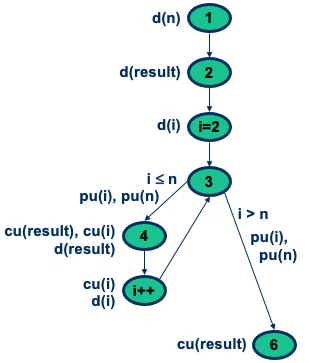
- Attempt it yourself as practice for exam!
Data Flow Graph: Paths and Pairs
- Complete path: initial node is start node, final node is exit node
- Simple path: all nodes except possibly first and last are distinct
- Loop free path: all nodes are distinct (cycle free?)
- def-clear path with respect to v: any path starting from a node at which variable v is defined and ending at a node at which v is used, without redefining v anywhere else along the path
- du-pair with respect to v: (d, u)
- d … node where v is defined
- u … node where v is used
- def-clear path with respect to v from d to u
- Also referred as “reach”: def to v at d reaches the use at u.
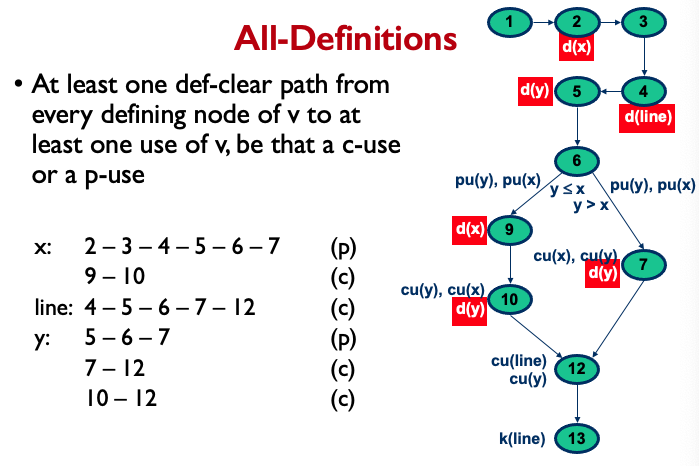
- Definition-use path (du-path) with respect to v: a path such that and either one of the following two cases:
- c-use of v at node , and is a def-clear simple path with respect to v (i.e., at the most single loop traversal)
- p-use of v on edge to and is a def-clear loop-free path (i.e., cycle free)
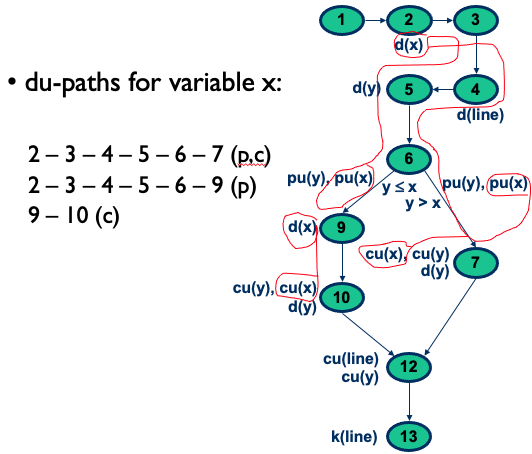
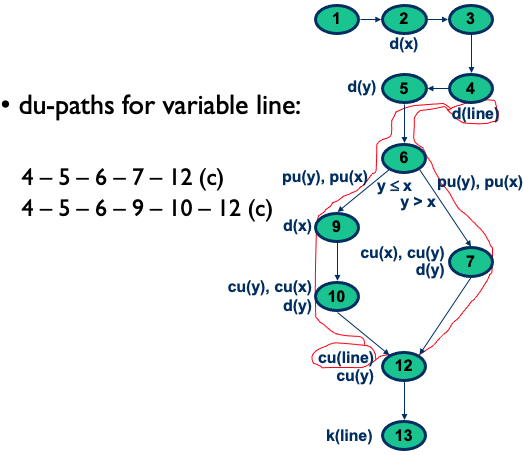
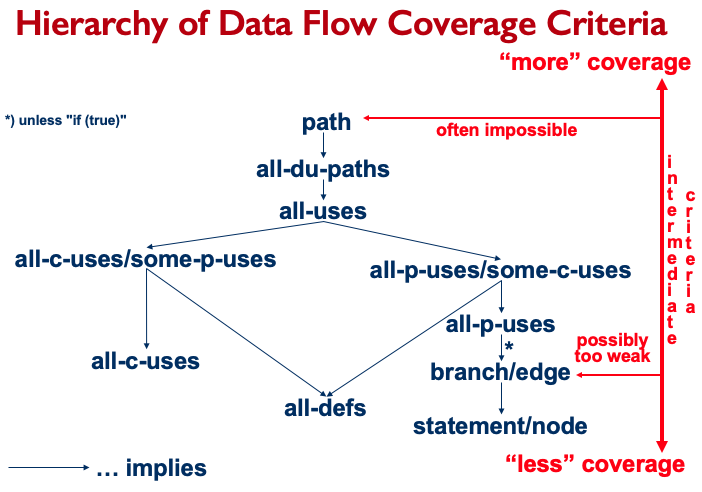
Data Flow Coverage:
- all-definitions (all-defs)
- all-uses
- all-p-uses/some-c-uses
- all-c-uses/some-p-uses
- all-du-paths
All Definitions:
All-Uses:
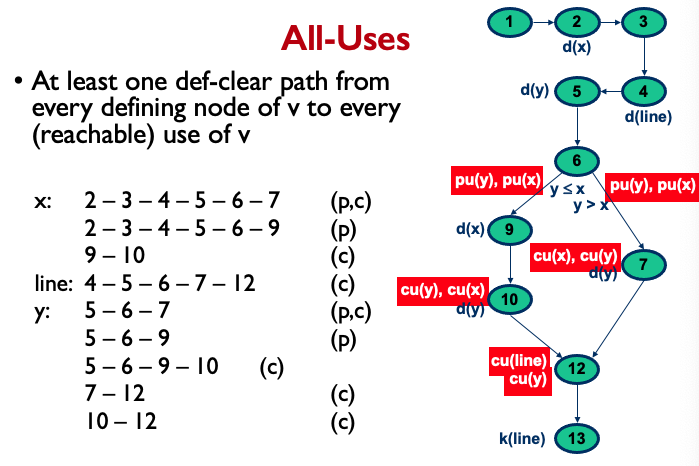
- What does reachable use of v mean? Where it simply uses it?
- Why is there not a line: 4-5-6-9-10-12?to-understand
All-P-Uses/Some-C-Uses:
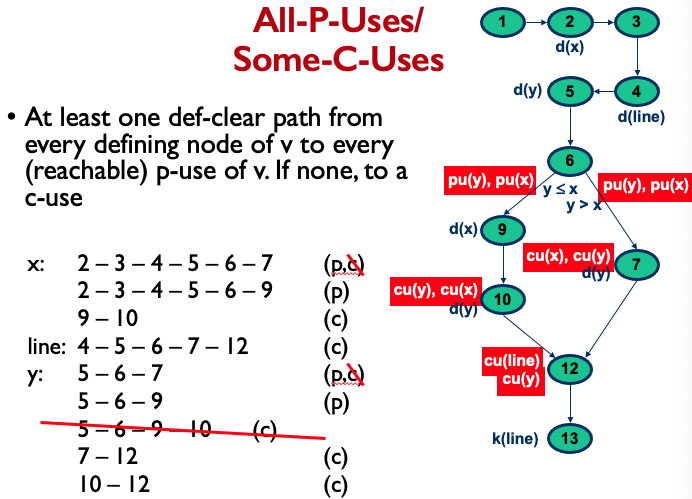
All-C-Uses/Some-P-Uses:
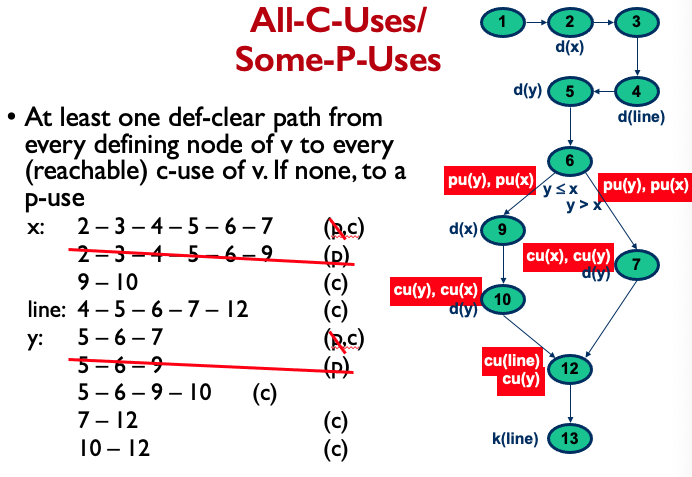
All-DU-Paths:
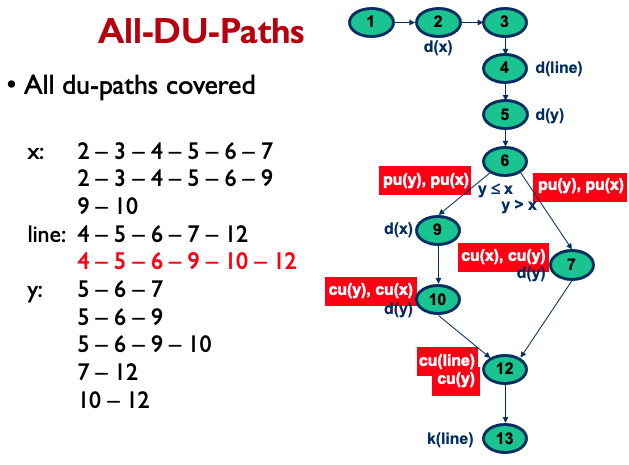
Hierarchy of Data Flow Coverage Criteria:
Exercise: Search
Look at the exercise on slide 49 of Week2 dataflow lecture.
Week 3
Creating Tests
Creating test cases:
- In order to increase the coverage of a test suite, one needs to generate test cases that exercise certain statements or follow a specific path
- Not alway easy
CFG question
What is the control flow graph of the following?
Answer
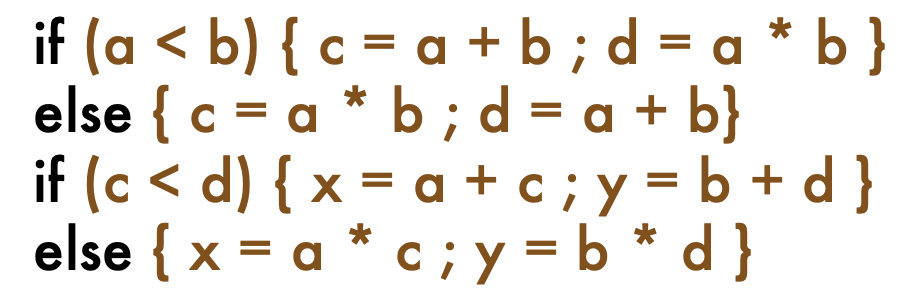
- The key question for creating a test for a path is:
- How to make the path execute, if possible.
- Generate input data that satisfies all the conditions on the path
- How to make the path execute, if possible.
- The key items you need to generate a test case for a path:
- Input vector
- Predicate
- Path predicate
- Predicate interpretation
- Path predicate expression
- Create test input from path predicate expression
Input Vector
A collection of all data entities read by the routine whose values must be fixed prior to entering the routine.
The members of an input vector are:
- Input arguments and constants
- Files
- Network connections
- Timers
Predicate
A logical function evaluated at a decision point.
In the following example, each of and are predicates:
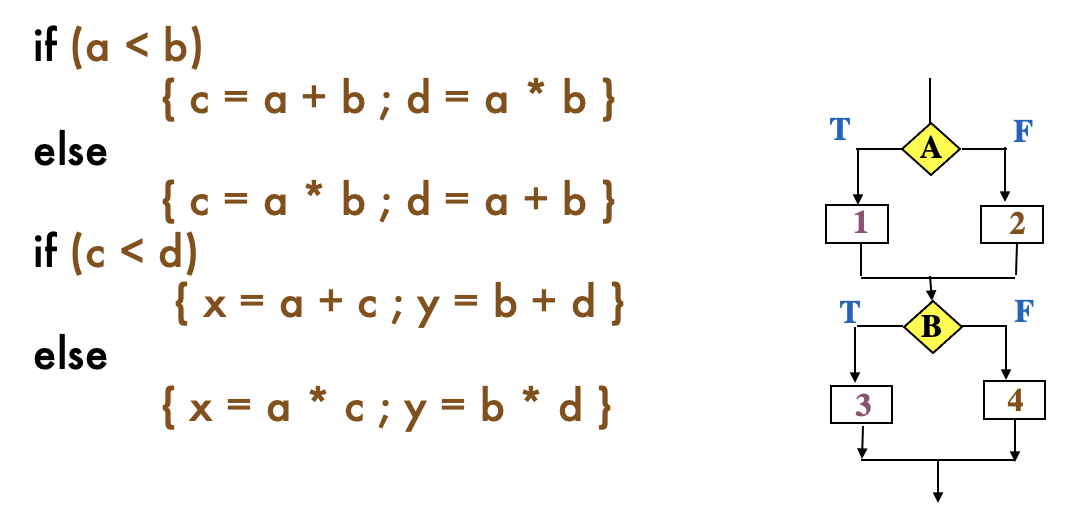
Pat Predicate
A path predicate is the set of predicates associated with a path.
Example: In the following and is a path predicate for path 4.
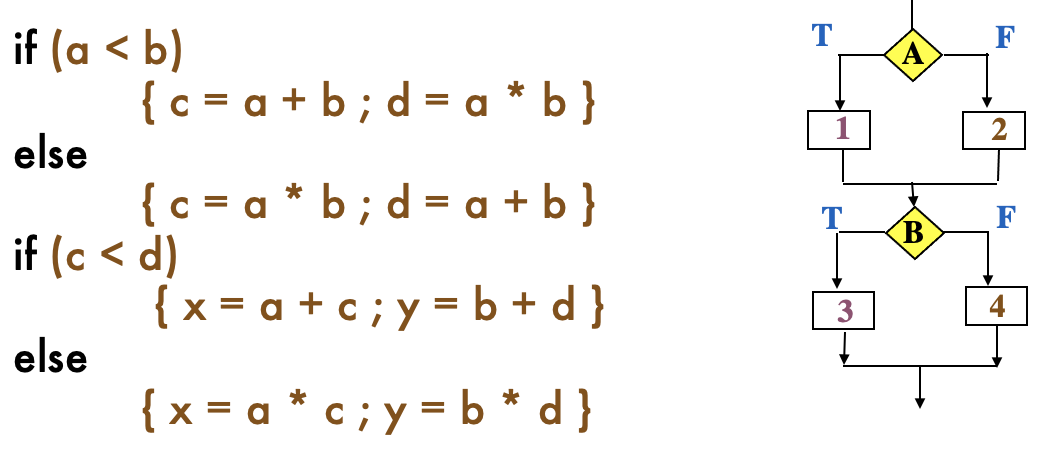
Predicate Interpretation
- A path predicate may contain local variables
- Local variables play no role in selecting inputs that force a path to execute
- Local variables cannot be selected independently of the input variables
- Local variables are eliminated with symbolic execution
Understanding the meaning and implications of each predicate is crucial for generating appropriate test inputs.
- A Symbolic Execution is
- Symbolically substituting operations along a path in order to express the predicate solely in terms of the input vector and a constant vector.
- A predicate may have different interpretations depending on how control reaches the predicate
Symbolic Execution
Key idea:
- Evaluate the program on symbolic input values
- Use an automated theorem to check whether there are corresponding concrete input values that make the program fail.
Symbolic execution is a technique used in software testing and verification to evaluate a program’s behaviour on symbolic input values rather than concrete values. The idea is to substitute symbolic values for variables and execute the program symbolically along different paths. This allows you to express the path predicate solely in terms of the input vector and a constant vector, effectively eliminating the influence of local variables.
Example: Symbolic execution
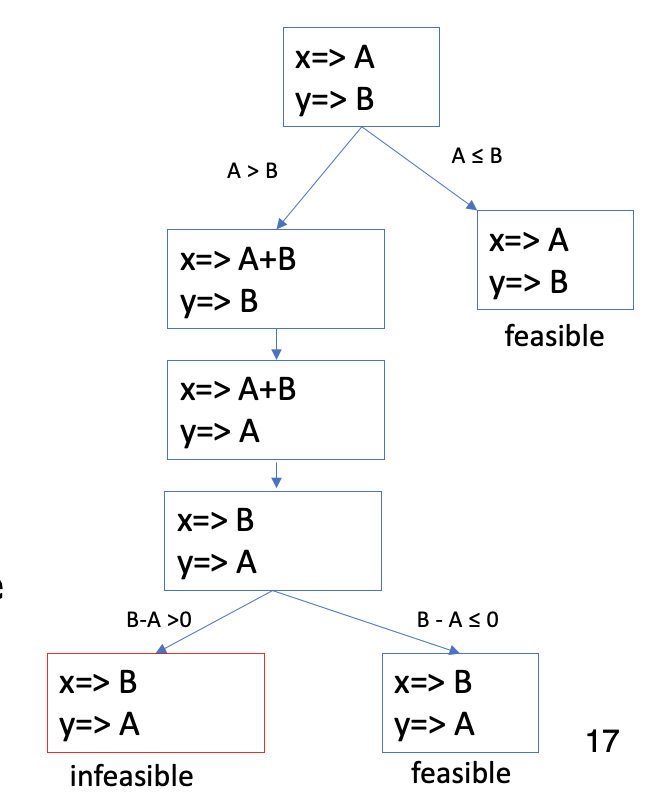
- Execute the program on symbolic values
- Symbolic state maps variables to symbolic values
- and
- Path condition is a logical formula over the symbolic inputs that encodes all branch decisions taken so far.
- All paths in the program forms its execution tree, in which some paths are feasible and some are infeasible


- why is it y ⇒ A ?

Path Predicate Expression
- An interpreted path predicate is called a path predicate expression.
- A path predicate expression has the following attributes
- No local variables
- It is a set of constraints in terms of the input vector, and, maybe, constants
- By solving the constraints, inputs force each path can be generated
- If a path predicate expression has no solution, the path is infeasible
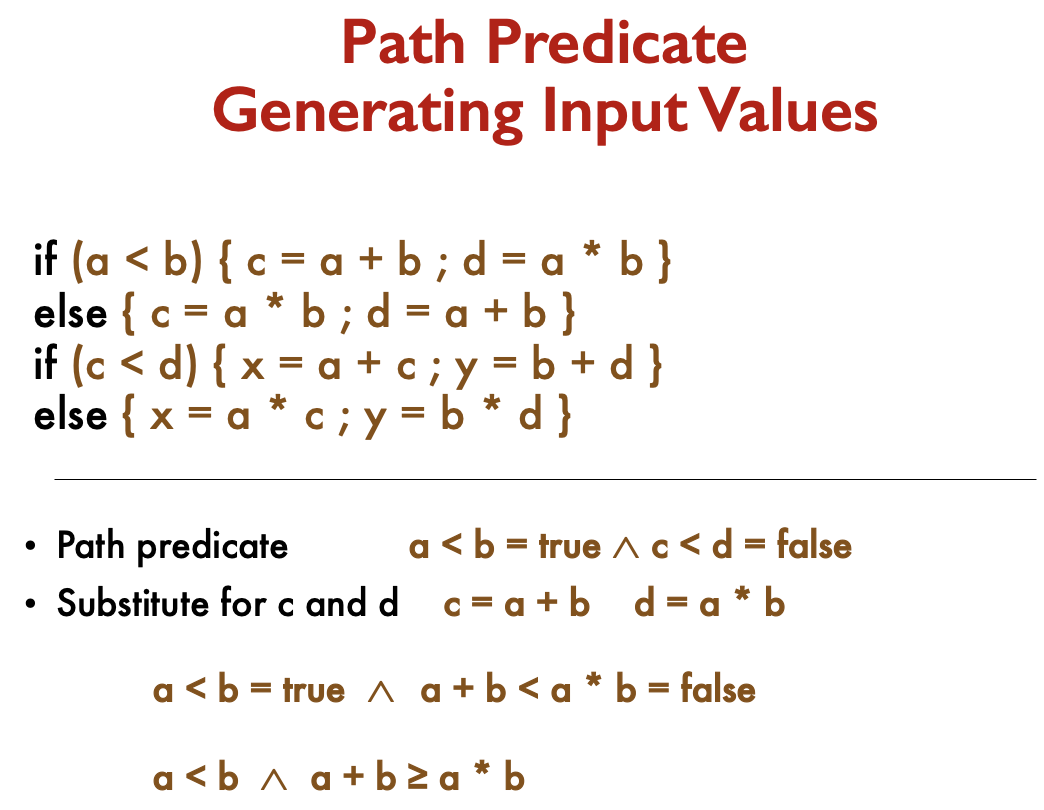
- We have feasible path, since a solution exists
- Can have infeasible paths, if there is no solution to the constraints

Organizing path predicates:
- We can organize the set of path predicates using a decision table
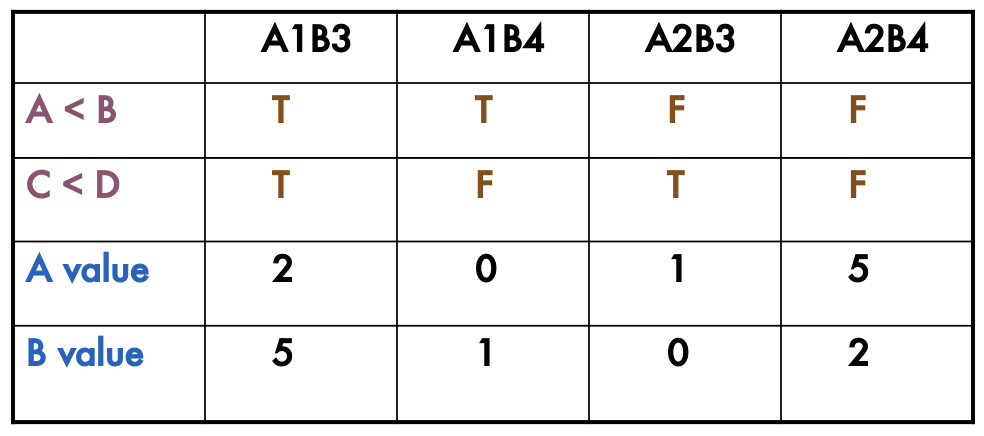
- Paths A1B3 and A2B4 give statement coverage or Paths A1B4 and A2B3 give statement coverage
- Why???
Selecting Paths:
- A program unit may contain a large number of paths.
- Path selection becomes a problem
- Some selected paths may be infeasible
- What strategy would you use to select paths?
- Select as many short paths as possible
- Tradeoffs?
- Choose longer paths
- Tradeoffs?
- Select as many short paths as possible
- What about infeasible paths?
- What would you do about them?
- Make an effort to write a program text with fewer or no infeasible paths.
Principles of maintainable test code
Test should be fast
- The faster we get feedback from the test code, the better. Slower test suites force us to run the tests less often, making them less effective.
- If you are facing a slow test, consider the following:
- Using mocks or stubs to replace slower components that are part of the test
- Redesigning the production code so slower pieces of code can be tested separately from fast pieces of code
- Moving slower tests to a different test suite that you can run less often
Tests should be cohesive, independent, and isolate
- Ideally, a single test method should test a single functionality or behaviour of the system. Complex test code reduces our ability to understand what is being tested at a glance and makes future maintenance more difficult.
- Tests should not depend on other tests to succeed. The test result should be the same whether the test is executed in isolation or together with the rest of the test suite.
- Test should clean up their messes, which will force tests to sup up things themselves and not rely on data that was already there.
Note
It is not uncommon to see cases where test B only works if test A is executed first. This is often the case when test B relies on the work of test A to set up the environment for it. Such tests become highly unreliable.
Tests should have a reason to exist
- You want tests that either help you find bugs or help you document behaviour. You do not want tests that, for example, increase code coverage. (Why? I know that sometimes you need to get code coverage as high as possible)
- If a test does not have a good reason to exist, it should not exist, since you need to maintain it.
- The perfect test suite is one that can detect all the bugs with the minimum number of tests.
Tests should be repeatable and not flaky
- A repeatable test gives the same result no matter how many times it is executed.
- Companies like Google and Facebook have publicly talked about problems caused by flaky tests.
- Because it depends on external or shared resources
- Due to improper time-outs
- Because of a hidden interaction between different test methods
- Other observations:
- Most flaky tests are flaky from the time they are written
- Flaky tests are rarely due to the platform-specifics (they do not fail because of different operating system)
Note
Developers lose their trust in tests that present flaky behavior (sometimes pass and sometimes fail, without any changes in the system or test code).
Tests should have strong assertions
- Tests exist to assert that the exercised code behaved as expected. Writing good assertions is therefore key to a good test!
- An extreme example of a test bad assertions is one with no assertions
- Assertions should be as strong as possible. You want your tests to fully validate the behaviour and break if there is any slight change in the output.
For example:
calculateFinalPrice()in aShoppingCartclass changes two properties:finalPriceand the taxPaid.- If your tests only ensure the value of the
finalPriceproperty, a bug may happen in the waytaxPaidis set, and your tests will not notice it.
Tests should break if the behaviour changes
- Tests let you know that you broke the expected behaviour
- If you break the behaviour and the test suite is still green, something is wrong with your tests
- Maybe weak assertions
- Maybe not really tested
- Test driven development (TDD) would help
Tests should have a single and clear reason to fail
- Test failure is the first step toward understanding and fixing the bug. Your test code should help you understand what caused the bug.
- The test is cohesive and exercises only one (hopefully small) behaviour of the software system.
- Give your test a name that indicates its intention and the behaviour it exercises.
- Make sure anyone can understand the input values passed to the method under test.
- Finally, make sure the assertions are clear, and explain why a value is expected.
Tests should be easy to write
- There should be no friction when it comes to writing tests; or it is too easy for you to give up and not do it.
- Writing unit tests tends to be easy most of the time, but it may get complicated when the class under test requires too much setup or depends on too many other classes. Integration and system tests also require each test to set up and tear down the (external) infrastructure.
- Make sure tests are always easy to write. Give developers all the tools to do that. If tests require a database to be set up, provide developers with an API that requires one or two method calls and voilà—the database is ready for tests.
- Investing time in writing good test infrastructure is fundamental and pays off in the long term.
Tests should be easy to read
- Your test code base will grow significantly. But you probably will not read it until there is a bug or you add another test to the suite.
- make sure all the information (especially the inputs and assertions) is clear enough
- use test data builders whenever I build complex data structures.
- What are test data builders?
- test data builders are a valuable tool for improving the readability, maintainability, and clarity of test code by providing a clean and concise way to construct complex test data structure

Tests should be easy to change and evolve
- Although we like to think that we always design stable classes with single responsibilities that are closed for modification but open for extension, in practice, that does not always happen.
- Your task when implementing test code is to ensure that changing it will not be too painful.
- For example, if you see the same snippet of code in 10 different test methods, consider extracting it.
- Your tests are coupled to the production code in one way or another. That is a fact. The more your tests know about how the production code works, the harder it is to change them.
Note:
a clear disadvantage of using mocks is the significant coupling with the production code. Determining how much your tests need to know about the production code to test it properly is a significant challenge.
Test Smells (Anti-Patterns)
Code and test smells (anti-patterns)
- The term code smell indicates symptoms that may indicate deeper problems in the system’s source code.
- For example: Long Method, Long Class, and God Class
- Study shows that code smells hinder the comprehensibility and maintainability of software systems
- The community has been developing catalogs of smells that are specific to test code
- Test smells are prevalent in real life and, unsurprisingly, often hurt the maintenance and comprehensibility of the test suite.
Test Smells
- Mystery Guest
- Resource Optimism
- Test Run War
- General Fixture
- Eager Test
- Lazy Test
- Assertion Roulette
- Indirect Testing
- For Testers Only
- Sensitive Equality
- Test Code Duplication
Note
In effective software testing book, Test code duplication⇒ excessive duplication, Unclear assertion⇒ assertion roulette, Resource optimism⇒ Bad handling of complex or external resources, General fixture⇒ fixtures that are too general, Sensitive assertion⇒ sensitive equality
Eager Test
When a test method checks several methods of the object to be tested, it is hard to read and understand, and therefore more difficult to be used as documentation. Moreover, it makes tests more dependent on each other and harder to maintain.
The solution is simple:
- separate the test code into test methods that test only one method, using a meaningful name highlighting the purpose of the test. Note that splitting into smaller methods can slow down the tests due to increased setup/teardown overhead.

Lazy Tests
- This occurs when several test methods check the same method using the same fixture (but for example check the values of different instance variables).
- Such tests often only have meaning when considering them together, so they are easier to use when joined using Inline Method
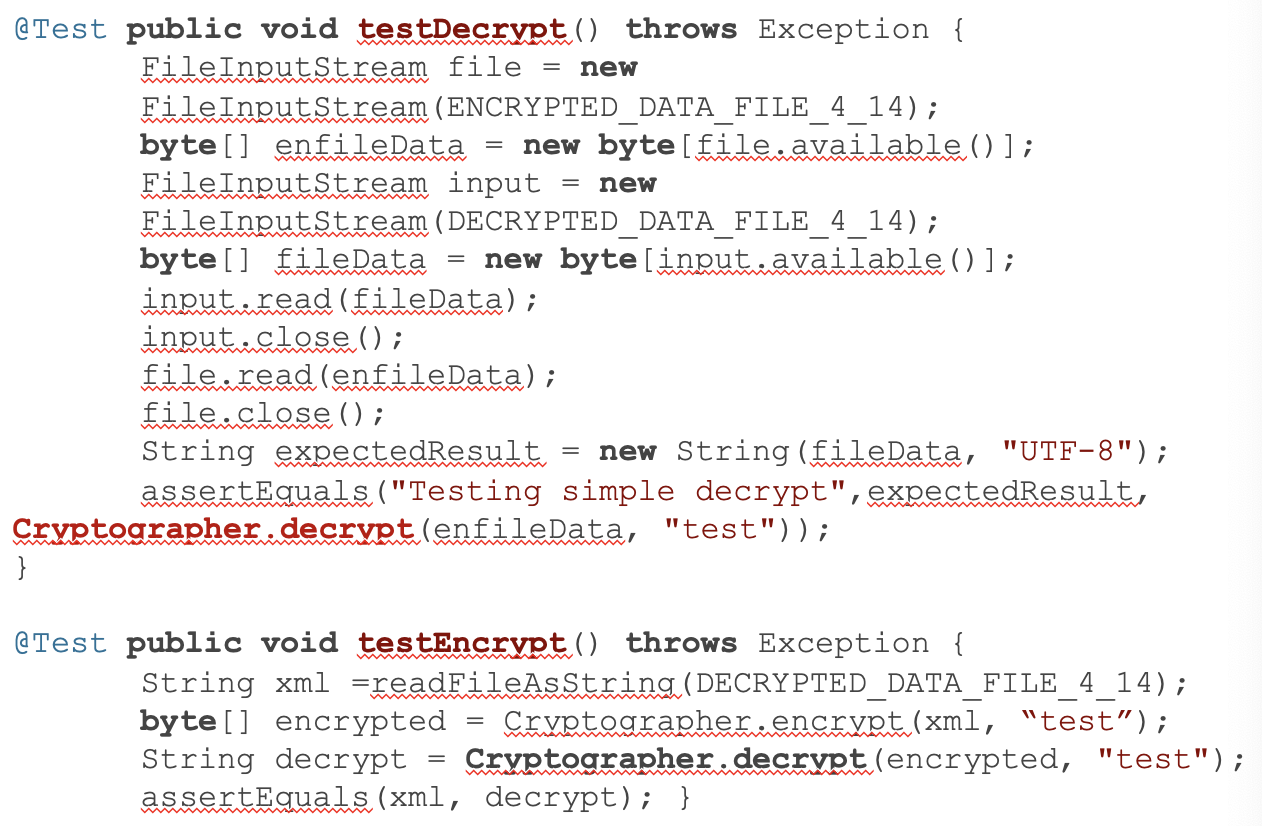
- Both test methods, testDecrypt() and testEncrypt(), call the same SUT method, Cryptographer.decrypt().
Mystery Guest
- When a test uses external resources, such as a file containing test data, the test is no longer self contained. Consequently, there is not enough information to understand the tested functionality, making it hard to use that test as documentation.
- Moreover, using external resources introduces hidden dependencies: if some force changes or deletes such a resource, tests start failing. Chances for this increase when more tests use the same resource.
- The use of external resources can be eliminated using the refactoring Inline Resource (1). If external resources are needed, you can apply Setup External Resource (2) to remove hidden dependencies.
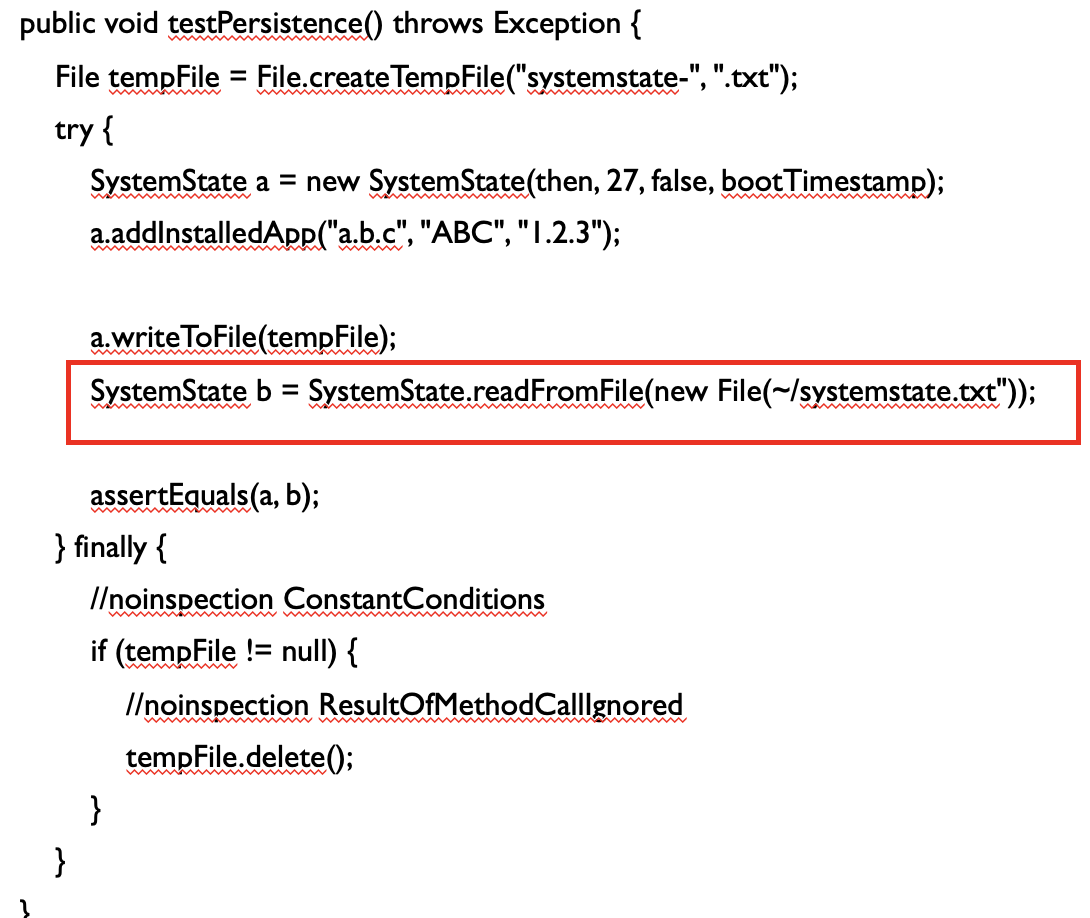
- As part of the test, the test method, testPersistence() depends on external file “~/systemstate.txt”
What is Refactoring: Inline Resource
To remove the dependency between a test method and some external resource, we incorporate that resource in the test code.
This is done by setting up a fixture in the test code that holds the same contents as the resource. This fixture is then used instead of the resource to run the test.
A simple example of this refactoring is putting the contents of a file that is used into some string in the test code. If the contents of the resource are large, chances are high that you are also suffering from Eager Test smell. Consider conducting Extract Method or Reduce Data refactoring.
What is Refactoring: Setup External Resource
- If it is necessary for a test to rely on external resources, such as directories, databases, or files, make sure the test that uses them explicitly creates or allocates these resources before testing, and releases them when done (take precautions to ensure the resource is also released when tests fail).
Resource Optimism
Test code that makes optimistic assumptions about the existence (or absence) and state of external resources (such as particular directories or database tables) can cause non-deterministic behaviour in test outcomes.
The situation where tests run fine at one time and fail miserably the other time is not a situation you want to find yourself in.
- Use Setup External Resource to allocate and/or initialize all resources that are used.

- The test method accesses a file without verifying if the file exists before using it in the test operations.
- You can just have test relying on the existence or inexistance of external resources and dependencies! Makes sense to me
Test Run War
Such wars arise when the tests run fine as long as you are the only one testing but fail when more programmers run them.
This is most likely caused by resource interference:
- some tests in your suite allocate resources such as temporary files that are also used by others.
- Apply Make Resource Unique to overcome interference.
What is Refactoring: Make Resource Unique?
- A lot of problems originate from the use of overlapping resource names, either between different tests run done by the same user or between simultaneous test runs done by different users.
- Such problems can easily be prevented (or repaired) by using unique identifiers for all resources that are allocated, for example by including a time-stamp. When you also include the name of the test responsible for allocating the resource in this identifier, you will have less problems finding tests that do not properly release their resources.
General Fixture
In the JUnit framework a programmer can write a setUp method that will be executed before each test method to create a fixture for the tests to run in.
Things start to smell when the setUp fixture is too general and different tests only access part of the fixture. Such setUps are harder to read and understand. Moreover, they may make tests run more slowly (because they do unnecessary work). The danger of having tests that take too much time to complete is that testing starts interfering with the rest of the programming process and programmers eventually may not run the tests at all.
Solution:
use setUp only for that part of the fixture that is shared by all tests using Extract Method and put the rest of the fixture in the method that uses it using Inline Method
- for example, two different groups of tests require different fixtures, consider setting these up in separate methods that are explicitly invoked for each test, or spin off two separate test classes using Extract Class.
- I don’t really understand what it means by fixture????to-understand
- And I don’t really understand this test smell.
- So from looking at the example, it seems like it has to do with the fixture doing to general things and the actual test only needing parts of what is done in the fixture.
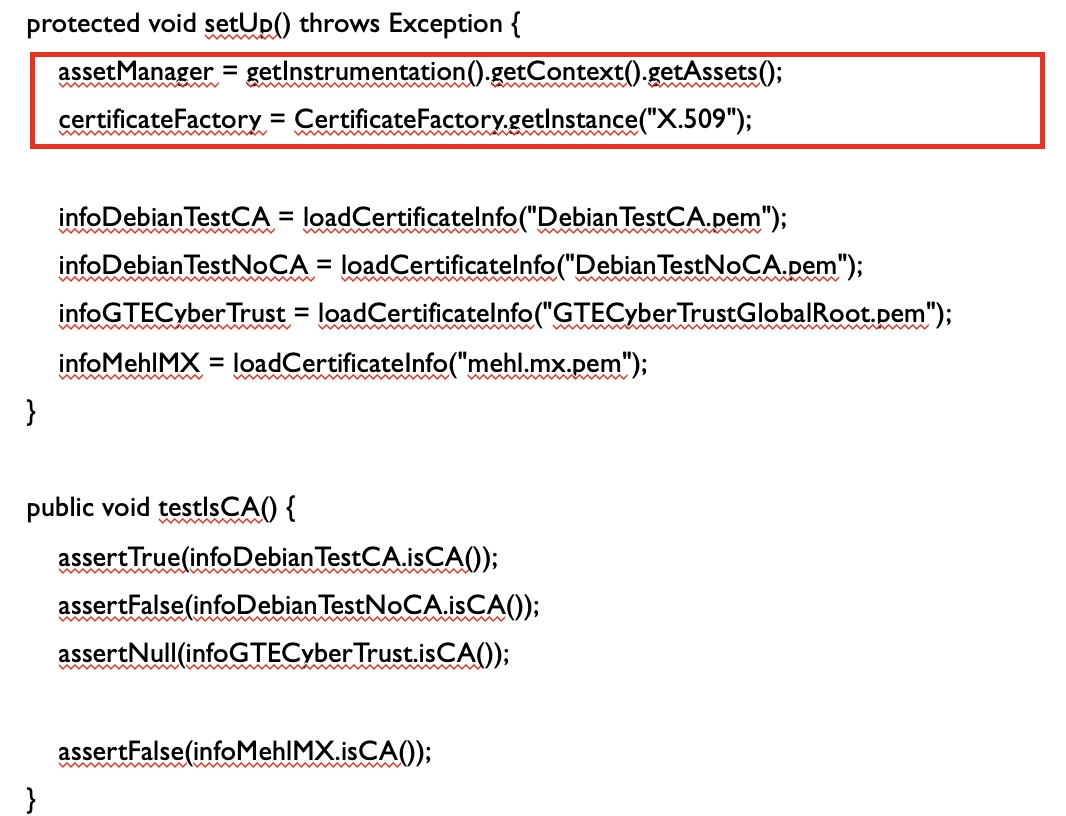
- The setup/fixture method initializes a total of 6 fields (variables). However, the test method, testIsCA(), only utilizes 4 fields.
Assertion Roulette
This smell comes from having a number of assertions in a test method that have no explanation. If one of the assertions fails, you do not know which one it is.
- Use Add Assertion Explanation to remove this smell.
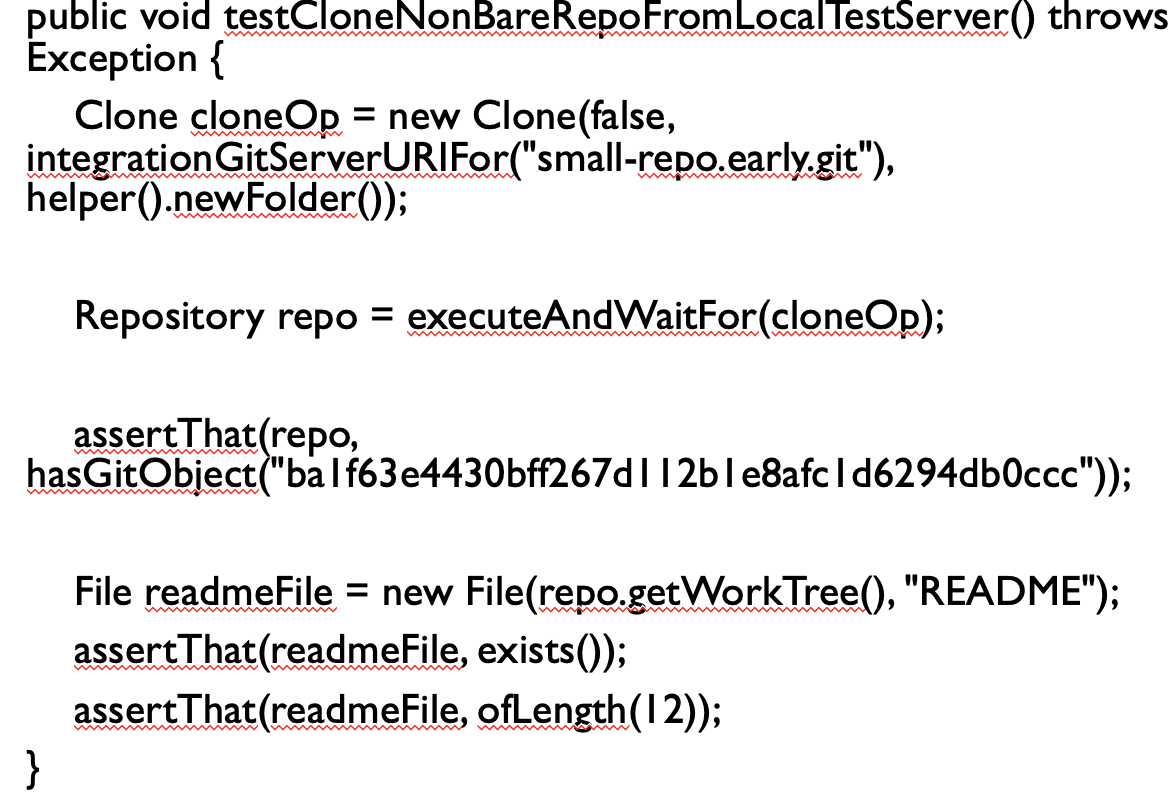
- As we can see, there are a lot of asserts.
Assertion Roulette vs. Eager Test?
Eager test:
- Testing multiple functionality
Assertion Roulette:
- One functionality but many assertions without explanation
What is Refactoring: Add Assertion Explanation
Assertions in the JUnit framework have an optional first argument to give an explanatory message to the user when the assertion fails.
Testing becomes much easier when you use this message to distinguish between different assertions that occur in the same test. Maybe this argument should not have been optional.
Very self explanatory
Indirect Testing
A test class is supposed to test its counterpart in the production code. It starts to smell when a test class contains methods that actually perform tests on other objects (for example because there are references to them in the class-to-be-tested).
Such indirection can be moved to the appropriate test class by applying Extract Method followed by Move Method on that part of the test. The fact that this smell arises also indicates that there might be problems with data hiding in the production code.
Note:
- that opinions differ on indirect testing. Some people do not consider it a smell but a way to guard tests against changes in the “lower” classes.
- In general, people feel that there are more losses than gains to this approach: It is much harder to test anything that can break in an object from a higher level. Moreover, understanding and debugging indirect tests is much harder.

- Should check if the system finds the less than threshold connection time, instead of the html output.
For Testers Only
When a production class contains methods that are only used by test methods, these methods either
- (1) are not needed and can be removed, or
- (2) are only needed to set up a fixture for testing.
Depending on functionality of those methods, you may not want them in production code where others can use them.
If this is the case, apply Extract Subclass to move these methods from the class to a (new) subclass in the test code and use that subclass to perform the tests on. You will often find that these methods have names or comments stressing that they should only be used for testing.
-
Fear of this smell may lead to another undesirable situation: a class without corresponding test class. The reason then is that the developer
- (1) does not know how to test the class without adding methods that are specifically needed for the test and
- (2) does not want to pollute his production class with test code. Creating a separate subclass helps to deal with this problem.
-
I’m a bit confused, just don’t include it? When we don’t want it in production code. Or move to a subclass. Pollution of production code…
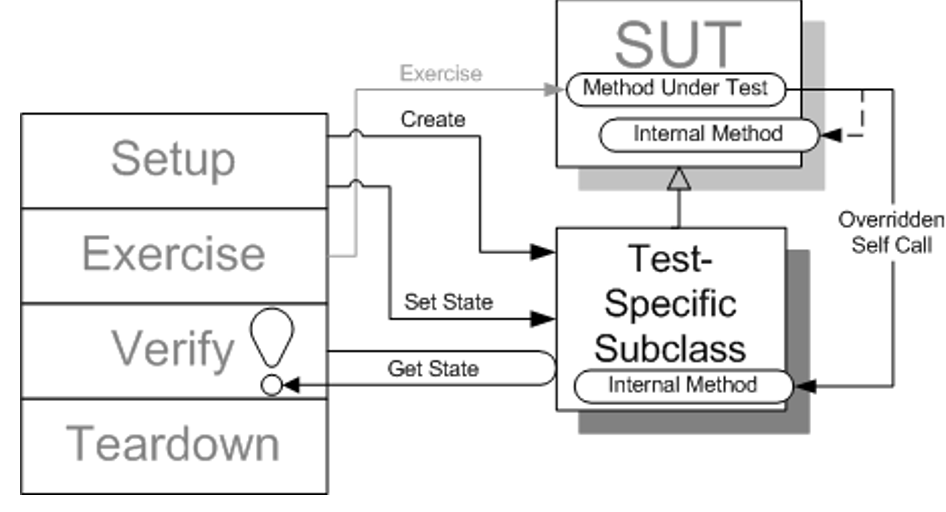
Sensitive Equality
It is fast and easy to write equality checks using the toString method. A typical way is to compute an actual result, map it to a string, which is then compared to a string literal representing the expected value. Such tests, however may depend on many irrelevant details such as commas, quotes, spaces, etc. Whenever the toString method for an object is changed, tests start failing.
The solution is to replace toString equality checks by real equality checks using Introduce Equality Method (6).

- Use of the default value returned by an objects toString() method, to perform string comparisons, runs the risk of failure in the future due to changes in the objects implementation of the toString() method.
What is Refactoring: Introduce Equality Method
If an object structure needs to be checked for equality in tests, add an implementation for the “equals” method for the object’s class.
You then can rewrite the tests that use string equality to use this method. If an expected test value is only represented as a string, explicitly construct an object containing the expected value, and use the new equals method to compare it to the actually computed object.
- Implement equal’s functions for class object
- This allows tests to use real equality checks instead of relying on string comparisons.
Test Code Duplication
- Test code may contain undesirable duplication. In particular the parts that set up test fixtures are susceptible to this problem. The most common case for test code will be duplication of code in the same test class.
- This can be removed using Extract Method. For duplication across test classes, it may provide helpful to mirror the class hierarchy of the production code into the test class hierarchy.
- A special case of code duplication is test implication:
- test A and B cover the same production code, and A fails if and only if B fails.
- A typical example occurs when the production code gets refactored: before this refactoring, A and B covered different code, but afterwards they deal with the same code and it is not necessary anymore to maintain both tests.


Mutation Copy
Measuring Test Cases
- What we have learned so far?
- Quantitatively measure how much code is covered by test cases?
- Do the coverage metrics directly measure the effectiveness of test cases?
Test Case Effectiveness
- Test suite A can detect more bugs than test suite B.
- Given one bug, some test cases in suite A fail, but all test cases in suite B pass.
- The best test suite can detect every bug; whenever a bug is introduced, at least one test case will fail.
Measure test suite effectiveness
- A simple solution: Find all bugs in a software.
- The chicken or the eggs causality dilemma
- The state-of-the-art solution: artificially inject bugs
- Mutation testing
- Modify (mutate) some statements in the code, so we have many different versions of the code. Each version is a bug.
- Check if the test cases can find the bug, i.e., some test cases fail and some do NOT fail.
- Mutation testing
The metrics we covered so far are based on the contents we can obtain in software, whether requirements, code implementation,
Mutation Testing
Mutation Testingt
- Fault-based testing: directed towards “typical” faults that could occur in a program
- Basic idea:
- Take a program and test data generated for that program
- Create a number of similar programs (mutants), each differing from the original in one small way, i.e., each possessing a fault (e.g., replace addition operator by multiplication operator)
- The original test data is then run through the mutants
- If test data detects all differences in mutants, then the mutants are said to be dead, and the test set is adequate
- Mutation Testing is NOT a testing strategy like Boundary Value or Data Flow Testing. It does not outline test data selection criteria.
- Mutation Testing should be used in conjunction with traditional testing techniques, not instead of them.
Note: Mutation testing is based on two hypotheses.
The first is the competent programmer hypothesis. This hypothesis states that most software faults introduced by experienced programmers are due to small syntactic errors.[1] The second hypothesis is called the coupling effect. The coupling effect asserts that simple faults can cascade or couple to form other emergent faults.[6][7]
Steps in Mutation Testing
- Step 1: Modify statements in the code and create mutants
- Step 2: Test cases are run through the generated mutants
- Step 3: Compare the results of the original and the mutant
- Step 4: The mutant is killed if different results are found. The test case is good as it detects the change (i.e., injected defect). The mutant is alive if the results are the same: the test case is NOT effective.
A mutant remains live either because it is equivalent to the original program (functionally identical though syntactically different – equivalent mutant) or the test set is inadequate to kill the mutant.
- In the latter case, the test data need to be re-examined, possibly augmented to kill the live mutant.
- For the automated generation of mutants, we use mutation operators, i.e., predefined program modification rules (corresponding to a fault model).
Different Mutants
- Stillborn mutant: syntactically incorrect, killed by compiler
- Trivial mutant: killed by almost any test case
- Equivalent mutant: always produces the same output as the original program
- None of the above are interesting from a mutation testing perspective. We want to have mutants that represent hard to detect faults
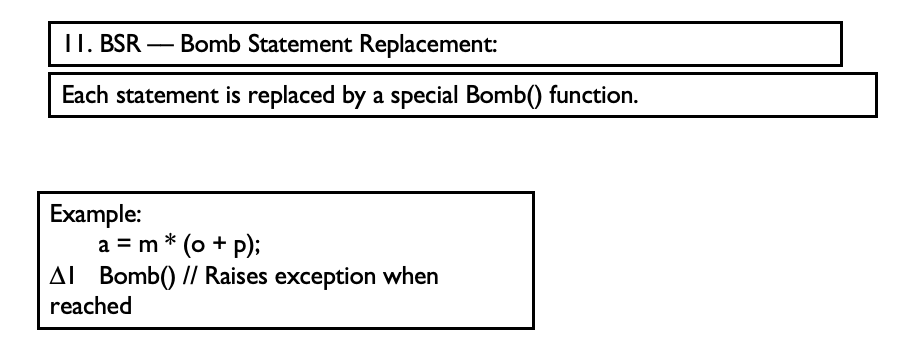
Example of Mutation Operators:

e.g., see http://pitest.org/quickstart/mutators/
Mutation Operators


- The failOnZero() method is a special mutation operator that causes a failure if the parameter is zero and does nothing if the parameter is not zero (it returns the value of the parameter)
- leftOp returns the left operand (the right is ignored), rightOp returns the right operand



- UOD
- For example, the statement “if !(a > -b)” is mutated to create the following two statements:
if (a > -b) if !(a > b)
Example of Mutation Operators
- Specific to Object-Oriented Programming languages:
- Replacing a type with a compatible subtype (inheritance)
- Changing the access modifier of an attribute or method
- Changing the instance creation expression (inheritance)
- Changing the order of parameters in the definition of a method
- Changing the order of parameters in a call
- Removing an overloading method
- Reducing the number of parameters
- Removing an overriding method
Assumptions
- What about more complex errors, involving several statements?
- Competent programmer assumption:
- given a specification a programmer develops a program that is either correct or differs from the correct program by a combination of simple errors
- Coupling effect assumption:
- test data that distinguishes all programs differing from a correct one by only simple errors is so sensitive that it also implicitly distinguishes more complex errors
- The assumption is extended later with: complex faults are coupled to simple faults in such a way that a test data set that detects all simple faults in a program will detect a high percentage of the complex faults
- test data that distinguishes all programs differing from a correct one by only simple errors is so sensitive that it also implicitly distinguishes more complex errors
Specifying Mutation Operators
- Ideally, we would like the mutation operators to be representative of (and generate) all realistic types of faults that could occur in practice
- Mutation operators change with programming languages, design and specification paradigms
- In general, the number of mutation operators is large as they are supposed to capture all possible syntactic variations in a program
- Mutants are considered to be good indicators of test effectiveness
Mutation Coverage
- Complete coverage equates to killing all non-equivalent mutants
- The amount of coverage is called mutation score (ratio of dead mutants over all non-equivalent mutants)
- For a set of test cases is the percentage of non-equivalent mutants killed by the test data
- Mutation Score = 100 * D / (N - E)
- D: Dead mutants
- N: Number of mutants
- E: Number of equivalent mutants
- A set of test cases is mutation adequate if its mutation score is 100%.
- We can see each mutant as a test requirement
- The number of mutants depends on the definition of mutation operators and the software syntax/structure
- Number of mutants tends to be large, even for small programs (random sampling?)
A simple example
- Discussion
- Mutant 3 is equivalent, because
minValand A have the same value at the changed line of code
- In order to have an appropriate test case, we must:
- Reach the program fault seeded during execution (reachability)
- Cause the program state to be incorrect (infection)
- Cause the program output to be incorrect (propagation)
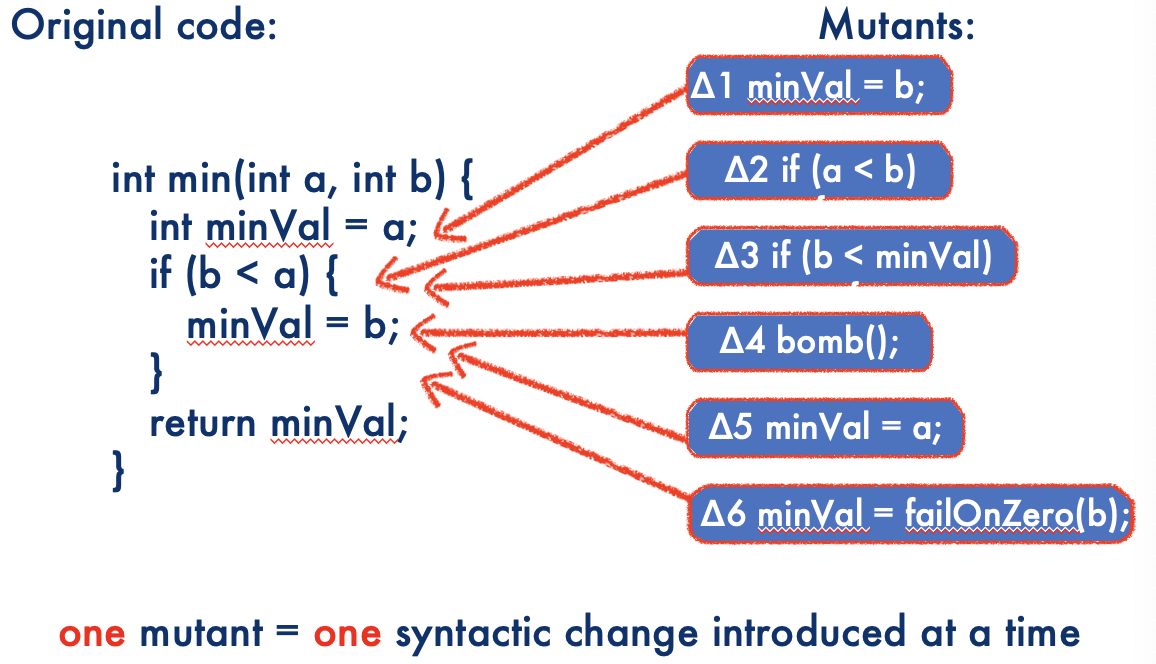
Strong and Weak Mutation
- Strong mutation: a fault must be reachable, infect the state, and propagate to output
- Weak mutation: a fault which kills a mutant need only be reachable and infect the state
Experiments show that weak and strong mutation require almost the same number of test cases to satisfy them
Strong Mutation Coverage (SMC)
- Strongly killing mutants
- Given a mutant for a program and a test case , is said to strongly kill iff the output of on is different from the output of on
- Strong mutation coverage (SMC)
- For each mutant in , contains a test case which strongly kills .
Weak Mutation Coverage (WMC)
- Weakly killing mutants
- Given a mutant that modifies a source location in program and a test case , is said to weakly kill iff the state of the execution of on is different from the state of the execution of on , immediately after some execution of
- Weak mutation coverage (WMC)
- For each mutant in , contains a test case which weakly kills .
- Note it’s output difference vs. state difference for SMC and WMC!!
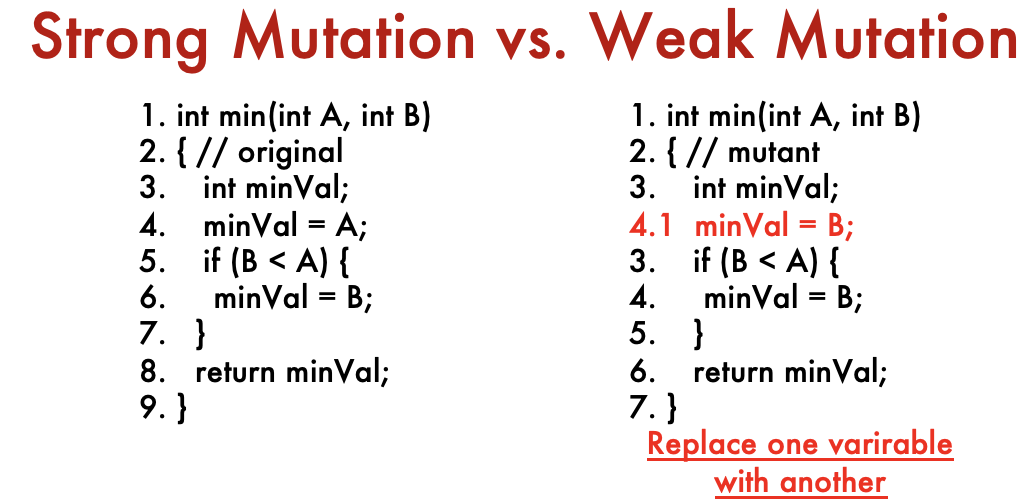
- Reachability: unavoidable
- Infection: need
- Propagation: wrong
minValneeds to return to the caller; that is we cannot execute the body of the if statement, so need - Condition for strongly killing mutation
- TC: , return 7 but expected 5
- Conditions for weakly killing mutation
- TC: , return 2 and expected 2
Need to go through ALL the following examples
Below. My brain kinda froze.
Another Simple Example
The program prompts the user for a positive number in the range of 1 to 20 and then for a string of that length. The program then prompts for a character and returns the position in the string at which the character was first found or a message indicating that the character was not present in the string. The user has the option to search for more characters.


- First input an array a with length
- Then input an array , search for
- Then say you want to continue
- then search for
char a - Then say you want to continue
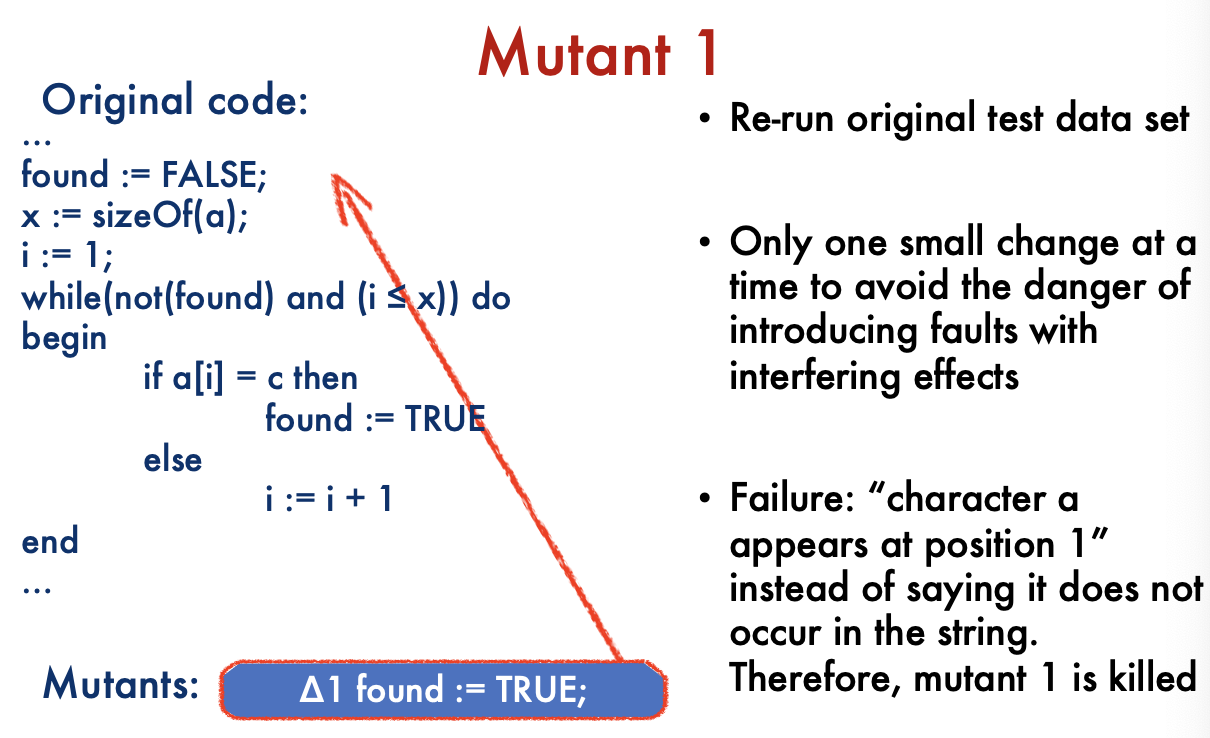
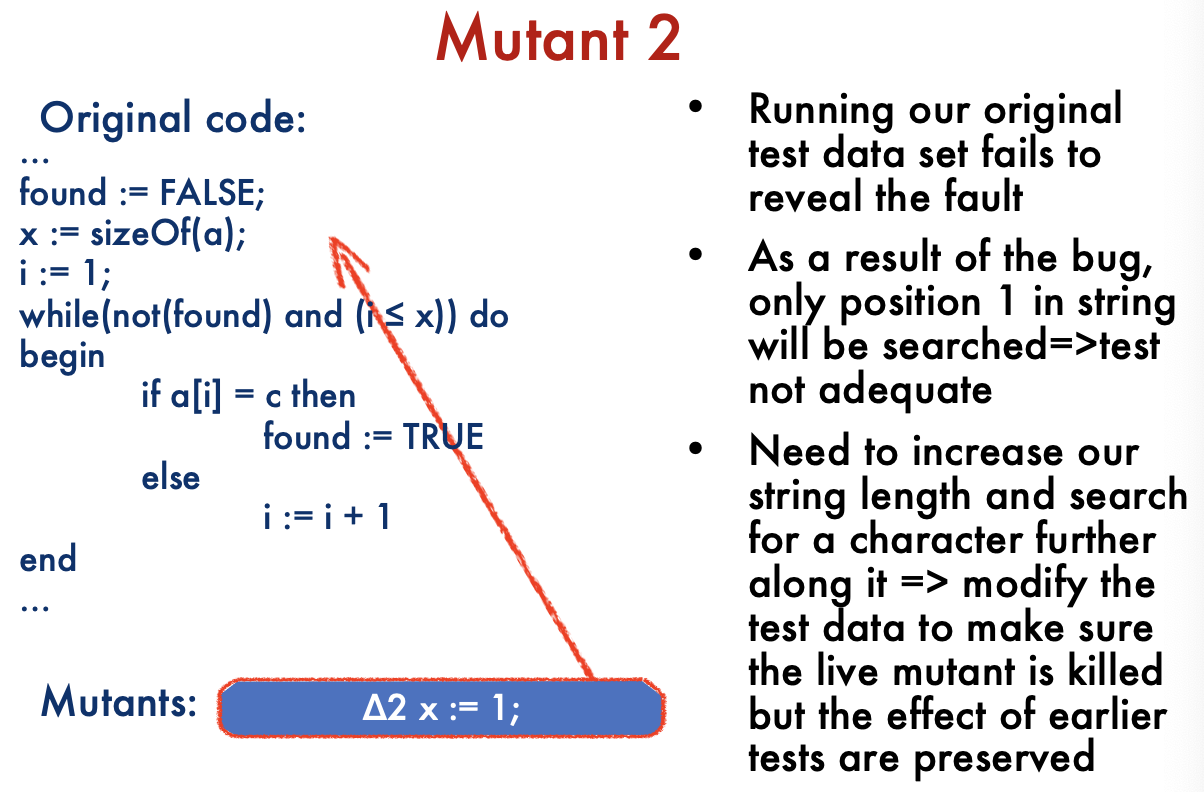
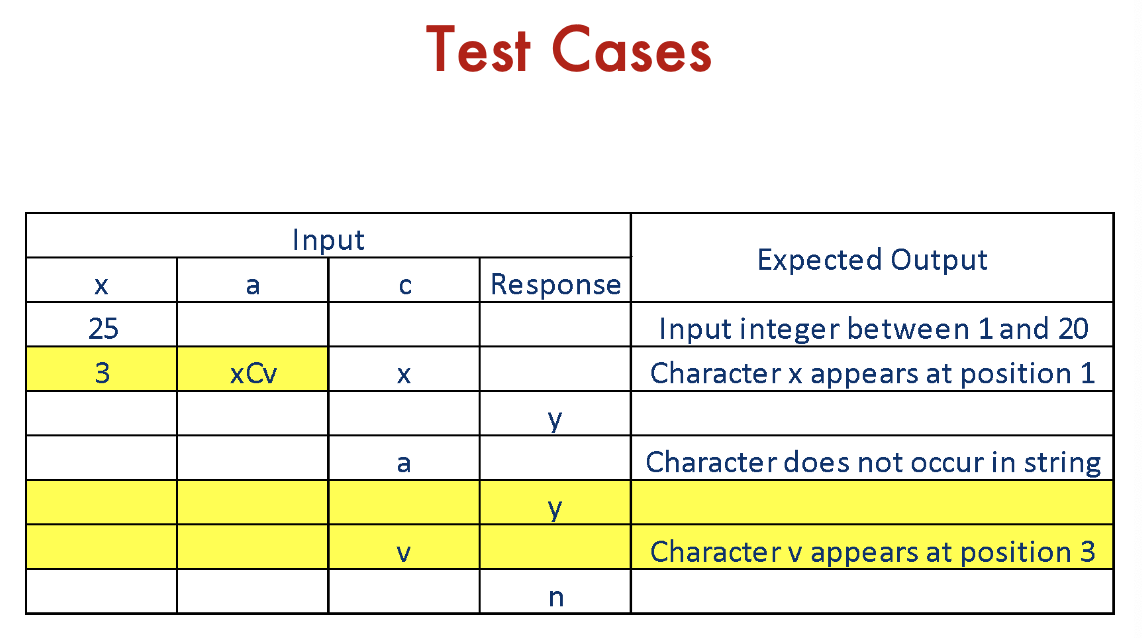

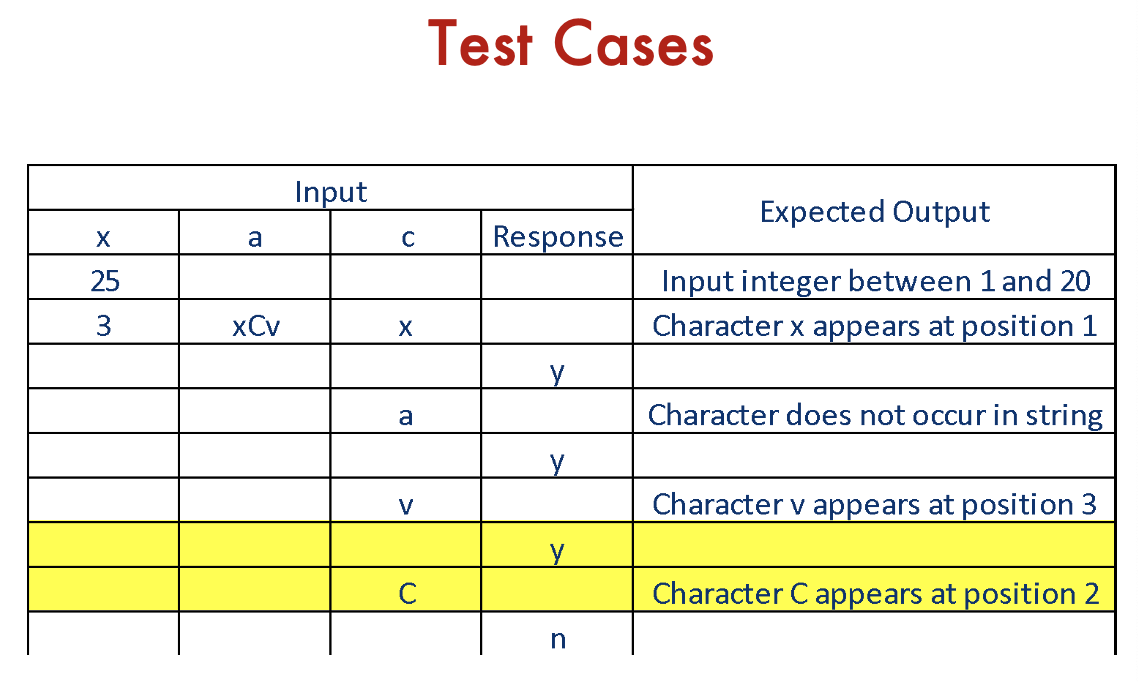
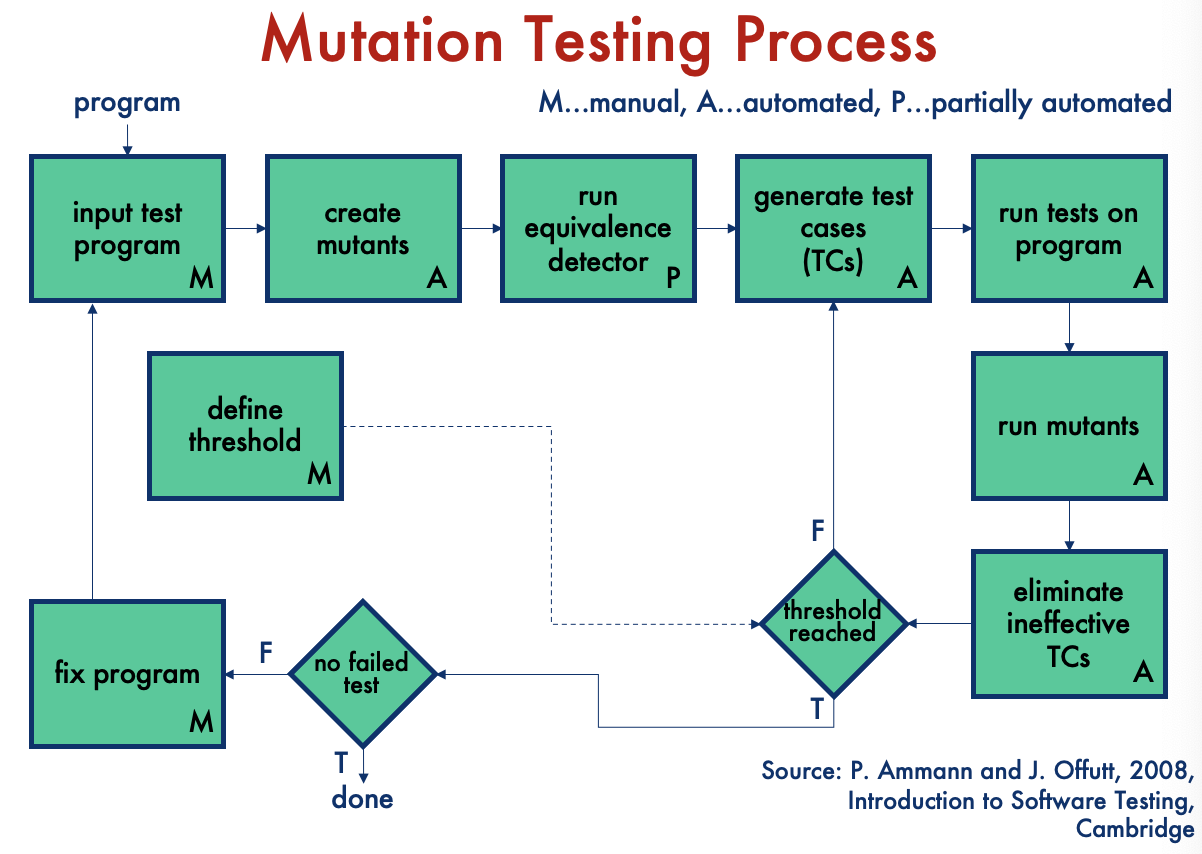
Mutation Testing: Summary
- Measures the quality of test cases
- Assumption: in practice, if the software contains a fault, there will usually be a set of mutants that can only be killed by a test case that also detects that fault
- Provides the tester with a clear target (mutants to kill)
- Computationally intensive, a possibly very large number of mutants is generated
- Equivalent mutants are a practical problem: it is in general an undecidable problem
Discussion
- Probably most useful at unit testing level but research is progressing…
- Mutation operators for module interfaces (aimed at integration testing)
- Mutation operators on specifications: Petri nets, state machines… (aimed at system testing)
- Also very useful for assessing the effectiveness of test strategies:
- Assess with the help of the mutation score test cases generated according to different test strategies
- Use the mutation score as a prediction of fault detection effectiveness
What about non-functional bugs?
- Can we design mutants that introduces non-functional issues?
- A delay (like
wait()) in the code to introduce performance issues?
- How big the delay is appropriate?
- Would the two assumptions still hold for non-functional bugs?
- Developers only make small issues>
- Tests detects simple issues can detect complex issues?
- The infection and propagation are hard to define outside of the functional test domain.
 #todo
#todo
- If possible, find test inputs that do not reach the mutant. If it is impossible, explain why.
- If possible, find test inputs that satisfy reachability but not infection for the mutant. If it is not possible, explain why.
- If possible, find test inputs that satisfy reachability and infection, but not propagation for the mutant. If it is not possible, explain why.
- Find a mutant of line 4 that is equivalent to the original statement.
Relevant Readings:
- Jorgensen: Chapter 21
- Ammann & Offutt: Chapter 9
Week 4
Integration Strategy
- How individual components are assembled to form larger program entities
- Problem 1: test component interaction
- Problem 2: determine optimal order of integration
- Strategy impacts:
- The form in which unit test cases are written
- The type of test tools to use
- The order of coding / testing components
- The cost of generating test cases
- The cost of locating and correcting detected defects
Integration Testing
Integration Testing
Goal: ensure components work in isolation and when assembled
Need a component dependency structure
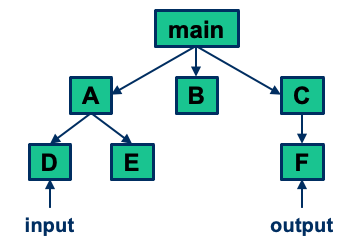
Questions
- How do we ensure a component is effectively tested in isolation?
- Assuming all components work in isolation, what types of faults can be expected? mostly interface-related (e.g., wrong method called, wrong parameters, incorrect parameter values, use of version that is not supported)
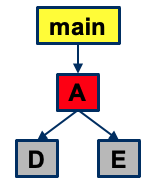
Integration Testing: Stubs
- Stub: replaces a called module
- Can replace whole components (e.g., database, network)
- Must be declared/invoked as the real module:
- Same name as replaced module
- Same parameter list as replaced module
- Same return type as replaced module
- Same modifiers (static, public or private) as replaced module
Example of stub:
So apparently, notice how it’s somehow isolating this component without needing the actually implementation of other parts. We have a dummy variable and we just want to know if it prints the given inputs out correctly.

- Common functions of a stub:
- Display / log trace message
- Display / log passed parameters
- Return value according to test objective - may be:
- Form a table
- From an external file
- Based on a search according to parameter value
- …
void main() {
1 int x, y;
2 x = A();
3 if (x > 0) {
4 y = B(x);
5 C(y);
} else {
6 C(x)
}
7 exit(0);
}- Test for path 1-2-3-4-5-7:
- Stub for
A()such thatx > 0returned
- Stub for
- Test for path 1-2-3-6-7
- Stub for
A()such thatx <= 0returned
- Stub for
- Problem:
- Stubs can become too complex
Integration Testing: Drivers
- Driver module used to call tested modules:
- Parameter passing
- Handling return values
- Typically, drivers are simpler than stubs
public class TestSomething {
public static void main (String[] args) {
float iSend = 98.6f;
Whatever what = new Whatever();
System.out.println("Sending someFunc: " + iSend);
int iReturn = what.someFunc(iSend);
System.out.println ("SomeFunc returned: " + iReturn);
}
}- A driver module, in the context of integration testing, is responsible for calling the tested modules or components and facilitating the integration process.
- The method
someFunc()of theWhateverinstancewhatis called withiSendas its argument. This is the point where integration testing occurs, as the driver module is interacting with thesomeFunc()method, which is likely part of a larger system or module. - Is the TestSomething the driver module?
- the driver module is the
TestSomethingclass. The purpose of this class is to act as a driver for testing thesomeFunc()method, which is likely part of another module or class (in this case, theWhateverclass).
- the driver module is the
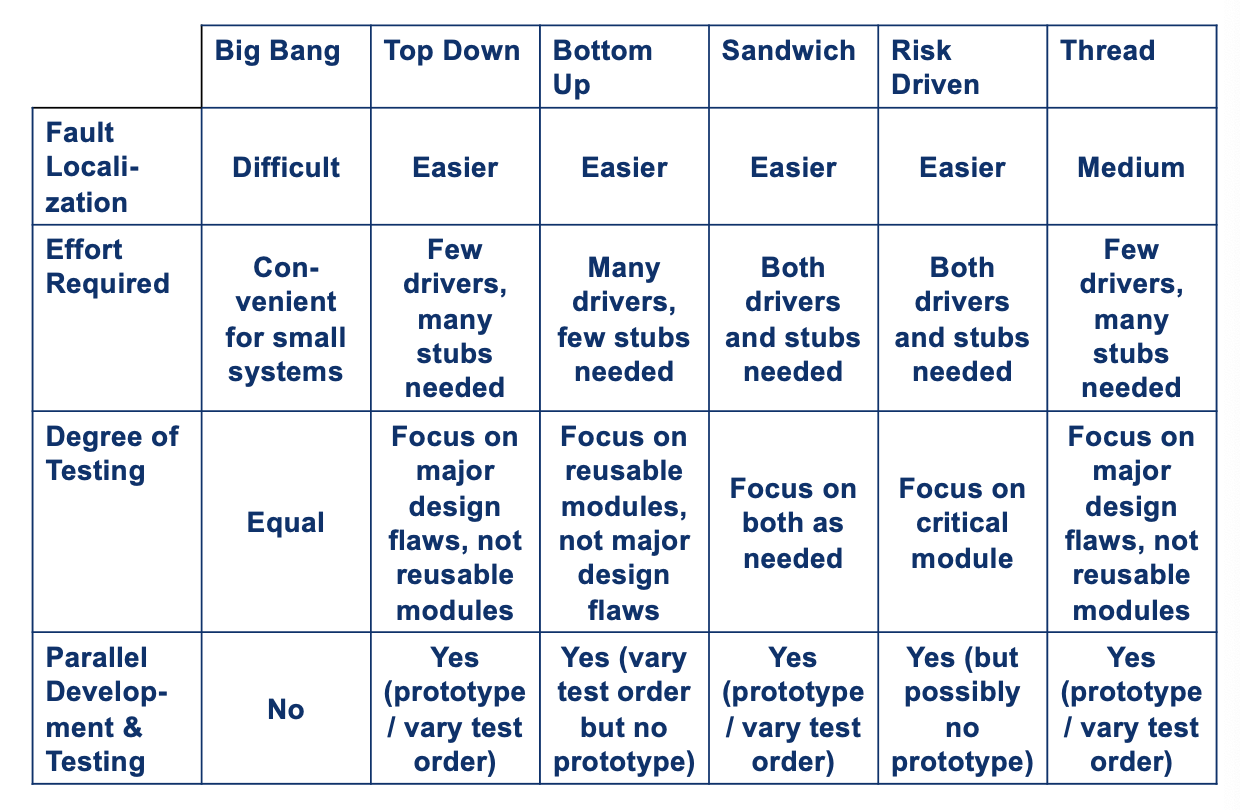
Integration Testing Strategies
- Different strategies for integration testing:
- Big Bang
- Top-Down
- Bottom-Up
- Sandwich
- Risk-Driven
- Function/Threaded-Based
- Comparison criteria:
- Fault localization
- Effort needed (for stubs and drivers)
- Degree of testing of modules achieved
- Possibility for parallel development (i.e., implementation and testing)
Big Bang Integration
- Non-incremental strategy
- Integrate all components as a whole
- Assumes components are initially tested in isolation (that’s the responsibility of programmers)
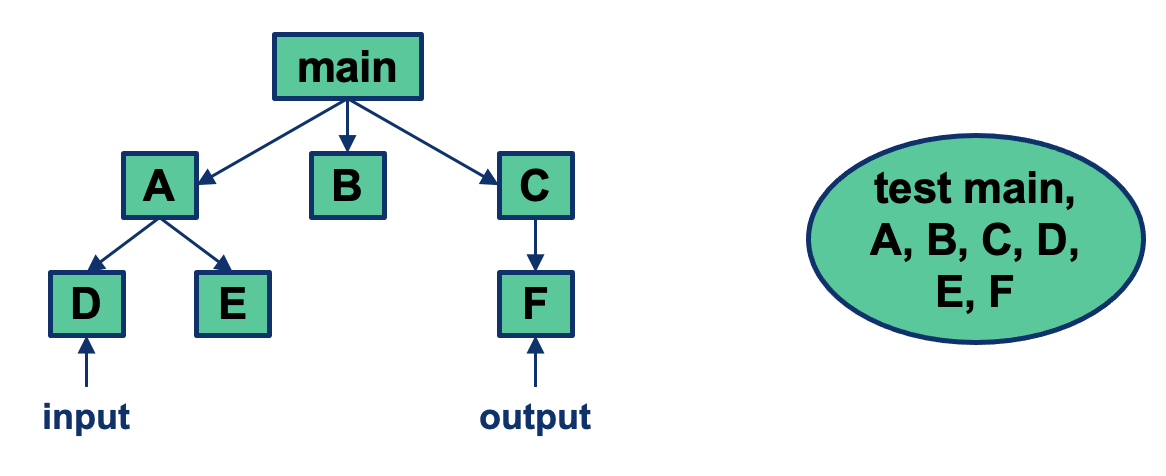
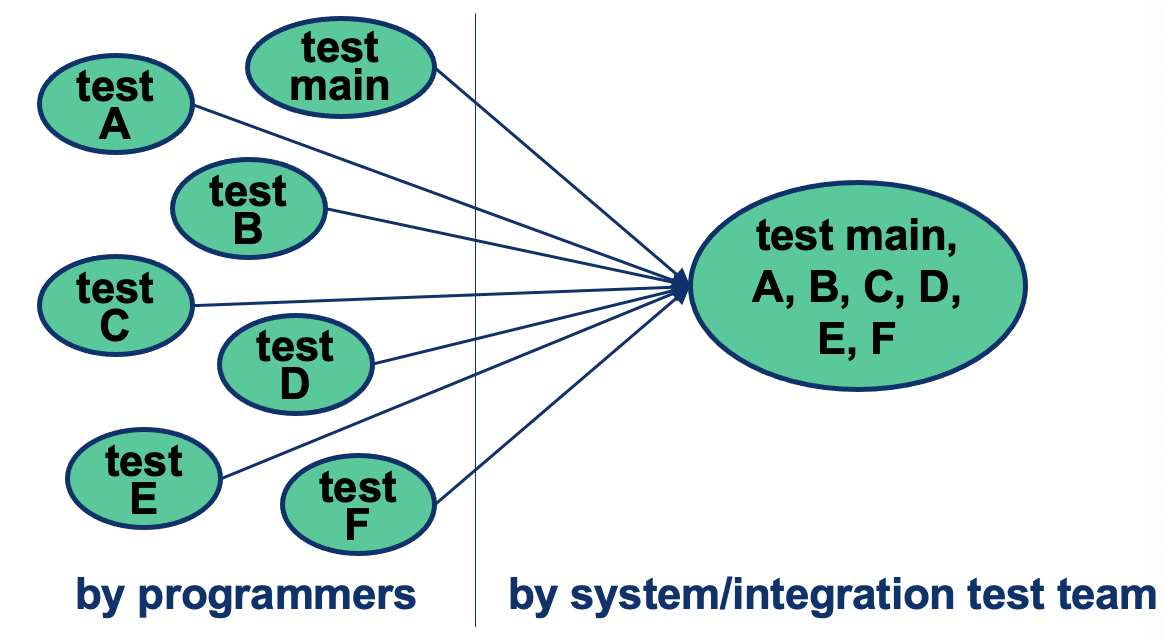
Advantages:
- Convenient for small/stable systems
Disadvantages:
- Does not allow parallel development (i.e., testing while implementing)
- Fault localization difficult
- Easy to miss interface faults
Top-Down Integration
- Incremental strategy
- Test high-level components, then called components until lowest-level components
- Possible to alter order such to test as early as possible:
- Critical components
- Input/output components
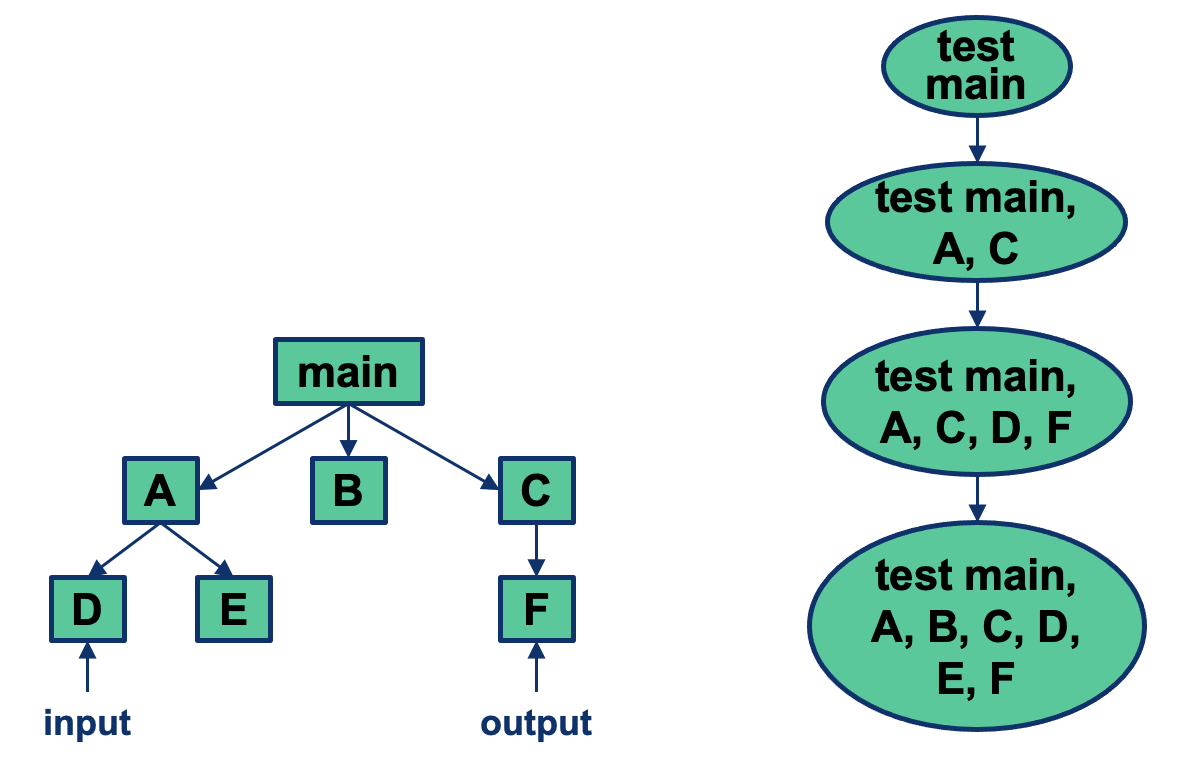
Advantages:
- Fault localization easier
- Few or no drivers needed
- Possibility to obtain an early prototype
- Testing can be in parallel with implementation
- Different order of testing/implementation possible
- Major design flaws found first (in logic components at the top of the hierarchy)
Disadvantages:
- Needs lots of stubs
- Potentially reusable components (at the bottom of the hierarchy) can be inadequately tested
Bottom-Up Integration
- Incremental strategy
- Test low-level components, then components calling them until highest-level component
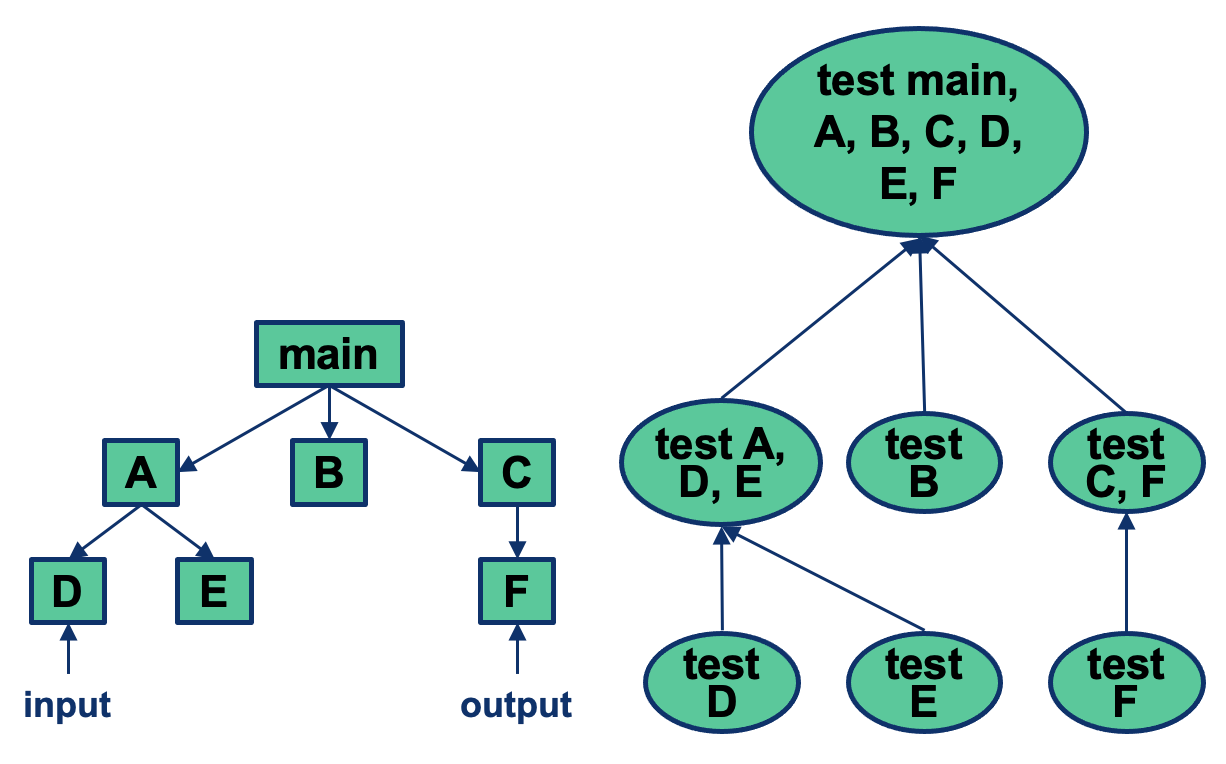
Advantages:
- Fault localization easier (than big-bang)
- No need for stubs
- Reusable components tested throughly
- Testing can be in parallel with implementation
- Different order of testing/implementation possible Disadvantages:
- Needs drivers
- High-level components (that relate to the solution logic) tested last (and least)
- No concept of early skeletal system
Sandwich Integration
- Combines top-down and bottom up approaches
- Distinguishes three layers:
- Logic (top) tested top-down
- Middle
- Operational (bottom) tested bottom-up
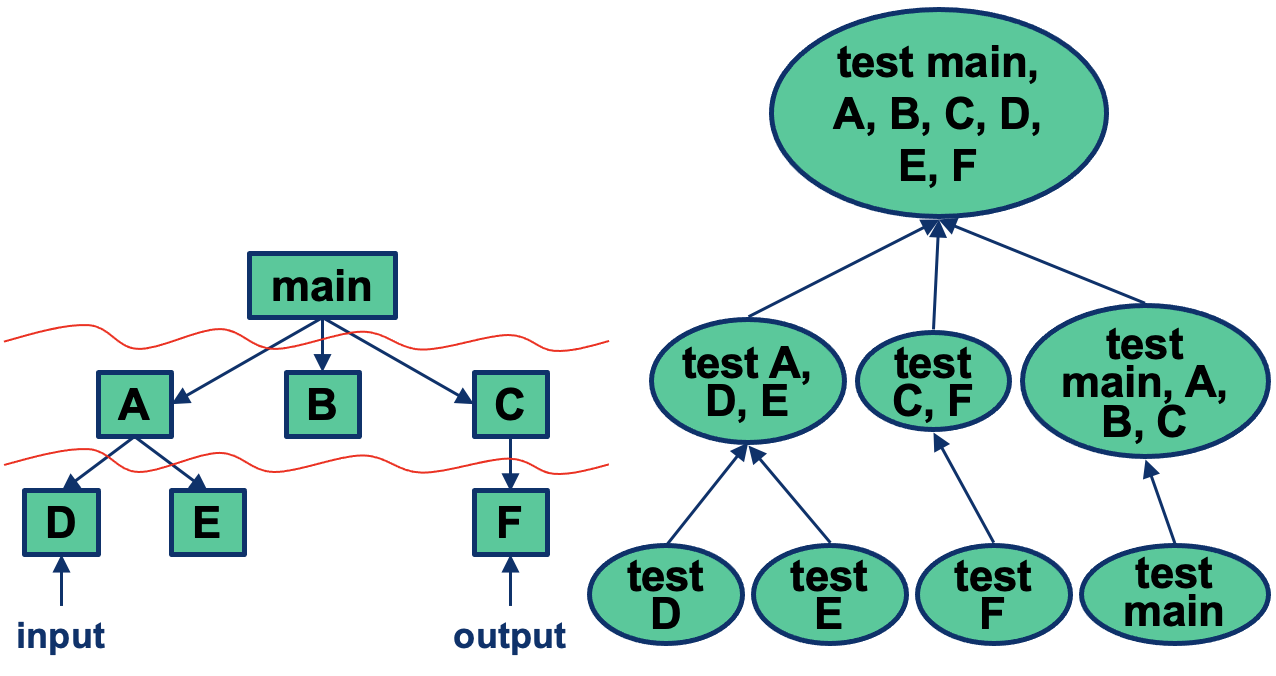
Test form main at start stubs out ABCDEF
Other Integration Testing Strategies
- Risk-driven integration:
- Integrate based on criticality (most critical or complex components integrated first with called components)
- Function/thread-based integration:
- Integrate components according to threads/functions they belong to
Testing Object-Oriented Systems
Object-orientation helps analysis and design of large systems, but based on existing data, it seems that more, not less, testing is needed for OO software.
Many unit-testing techniques are applicable to classes (e.g., state-based testing, control flow-based testing, data flow-based testing), but OO software has specific constructs that we need to account for during testing:
- Encapsulation of state
- Inheritance
- Polymorphism and dynamic binding
- Abstract classes
- Exceptions
Basically, OO helps design of large systems, but testing is more difficult!
- Unit and integration testing are especially affected as they are more driven by the structure of the software under test
- Unit and integration testing of classes is white-box testing, as it is using structural information of classes
Need specific techniques for OO systems
Recall
That the integration testing techniques have been based on functions… the scenario is more complex for classes.
Class vs. Procedure Testing
-
Testing single methods can be based on traditional unit testing techniques, but it is usually simpler than testing of functions (subroutines) of procedural software, since methods tend to be small and simple
-
In OO systems, most methods contain a few LOCs
- complexity lies in method interactions
-
Method behaviour is meaningless unless analyzed in relation to other operations and their joint effect on a shared state (data member values)
-
Testing classes poses new problems:
- The identification of behaviour to be observed, i.e., how to complement input/output relations with state information to define test cases & test oracles.
- The manipulation of objects state without violating the encapsulation principle (state is not directly accessible, but can only be accessed using public class operations)
- Polymorphism and dynamic binding leads to the test of one-to-many possible invocations of the same interfaces
- Each exception needs to be tested (e.g., analyze the code for possible null pointer exception)
Example: Watcher
- Testing method
checkPressure()in isolation is meaningless:
- Generating test data
- Measuring coverage
- Creating oracle is more difficult:
- The value produced by
checkPressure()depends on the state of class Watcher’s instances (variable status)- Failures due to incorrect values of variable status can be revealed only with tests that have control and visibility on that variable.

New Fault Models
- Traditional fault taxonomies, on which control and data flow testing techniques are based, do not include faults due to object-oriented features
- New fault models are vital for defining testing methods and techniques targeting OO specific faults, e.g.,:
- WrongWrong instance of method inherited in the presence of multiple inheritance
- Wrong redefinition of an attribute / data member
- Wrong instance of the operation called due to dynamic binding and type errors
- There is a lack of statistical information on frequency of errors and costs of detection and removal
Basically saying it introduces new kinds of error that we need to address when testing classes!
OO Integration Levels
- Functions (subroutines) are the basic units in procedural software
- Classes introduce a new abstraction level
- Basic unit testing: the testing of a single operation (method) of a class (intra-method testing)
- Unit testing: the testing of methods within a class (intra-class testing) (integration of methods)
- It is claimed that any significant unit to be tested cannot be smaller than the instantiation of one class
Intra-class Testing (continued)
- Black box, white box approaches
- Data flow-based testing (but across several methods in one class)
- Each exception raised at least once
- Each interrupt forced to occur at least once
- Each attribute set and got at least once
- State-based testing
- Big bang approach indicated for situation where methods are tightly coupled
- Alpha-omega cycle (constructors, get methods, Boolean methods, set methods, iterators, destructors)
- Complex methods can be tested with stubs/mocks
Note
Destructors are generally not there in Java systems (exception is the finalize() method).
State-based testing⇒ not covered in these slides ⇒ Since the state of an object is implicitly part of the input and output of methods, we need a way to systematically explore object states and transitions. This can be guided by a state machine model, which can be derived from module specifications.
- Classes introduce different scopes of integration testing: the testing of interactions among classes (inter-class testing), related through dependencies, i.e., association, composition, inheritance
Cluster integration
- Integration of two or more classes through inheritance (cluster) incremental test of inheritance hierarchies
- Integration of two or more classes through containment (cluster)
- Integration of two or more associated classes / clusters to form a component (i.e., subsystem)
- Big bang, bottom-up, top-down, scenario-based
- Integration of components into a single application (subsystem/system integration)
- Similar techniques for cluster integration also applicable at this level (big bang, bottom-up, top-down, use case-based)
- Client/server integration
Mock Objects
Testing of OO systems requires drivers and stubs
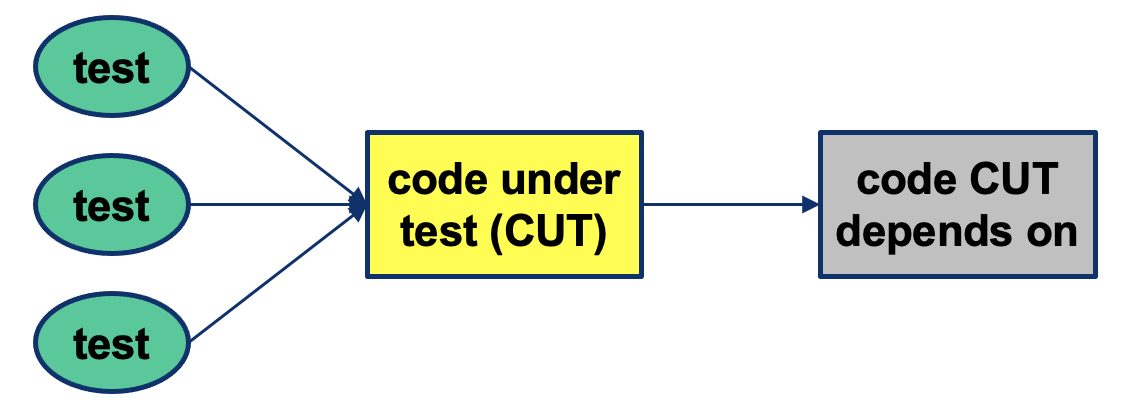
- Difficult to flexibly stub dependent code without:
- Changing CUT
- Maintaining a library of stub objects
- Difficult to manage a library of stubs
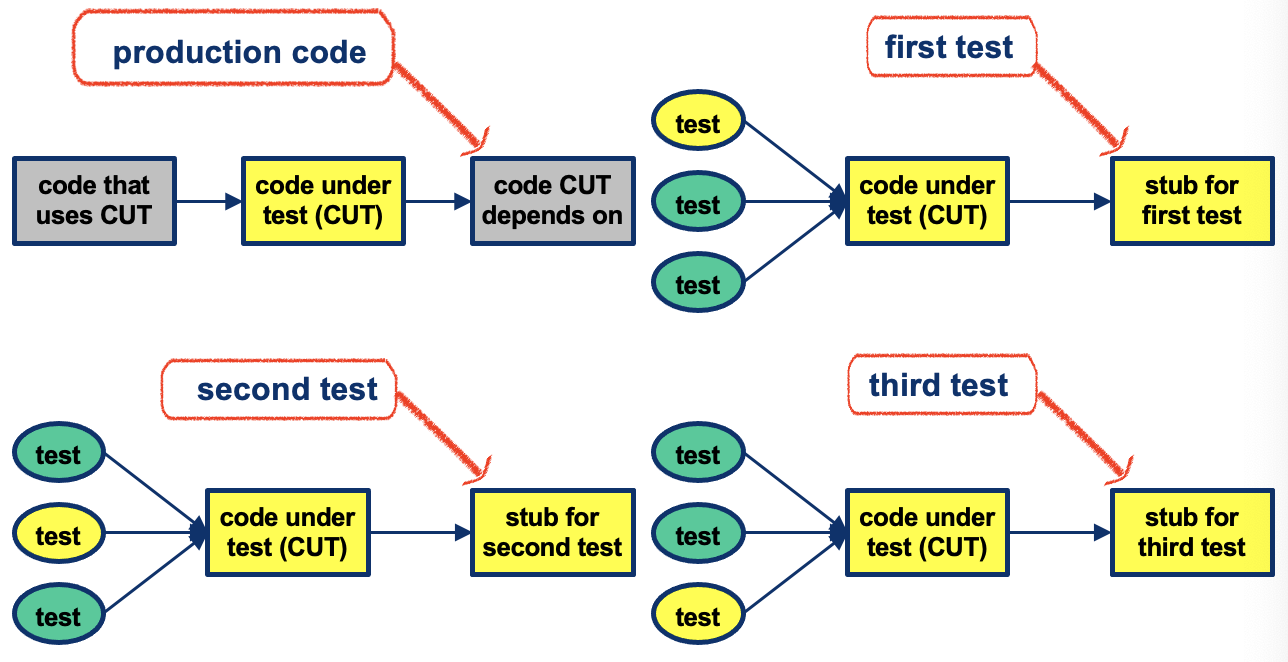
Introduce Mock object (form of stubs):
- Based on interfaces
- Easier to setup and control
- Isolates code from details that may be filled in later
- Can be refined incrementally by replacing with actual code
- Based on dependency inversion principle (higher-level modules use interfaces as an abstract layer instead of lower-level modules directly)
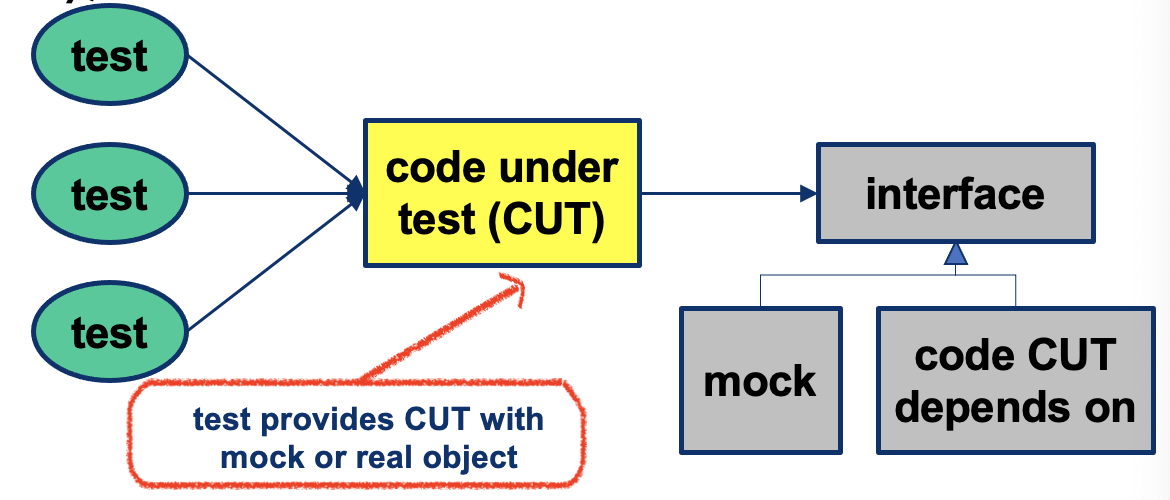
- Test controls mock behaviour (sets up which one to use)
- Mock transparently replaces actual code
Mock Objects: Example
Testing a servlet:
- How to unit test without involving a web server, servlet container?
- How to automate testing?
- Not having to check results in a web browser?
- Use something like the JUnit framework?
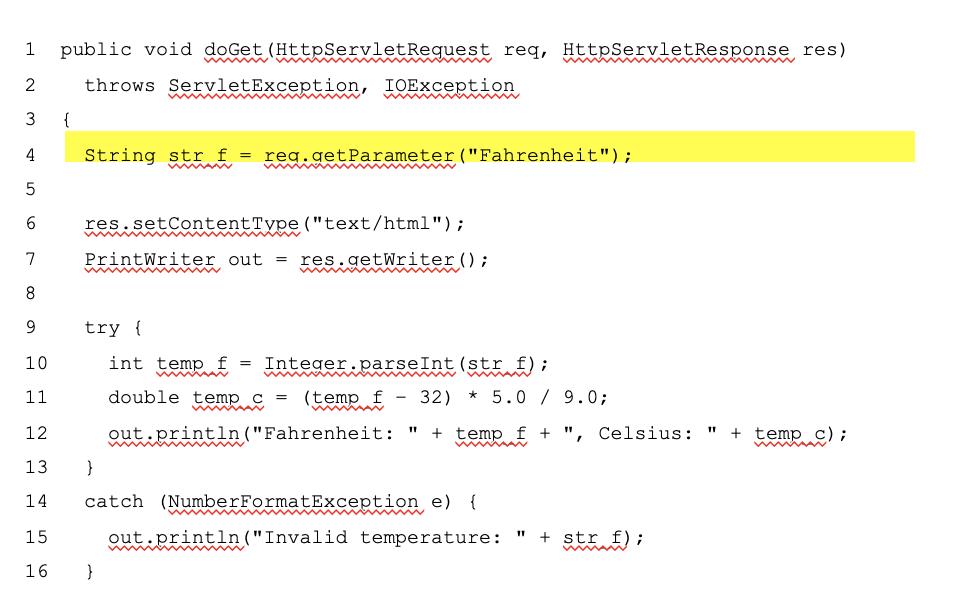
Mock Objects: Example (continued)
Mocks replace HttpServletRequest and HttpServletResponse when testing doGet:
Mocks replace HttpServletRequest and HttpServletResponse when testing doGet:


Mock Objects: Creation
- Manual creation:
- Advantage: more control
- Disadvantage: may introduce need for several classes, difficulties with existing infrastructure classes (e.g., JDBC)
- Popular frameworks:
- EasyMock
- Mockito
- Older frameworkds:
- iMock
- MockMaker
- MockObjects
- Mockrunner
Mockito
Characteristics of a Mock
- A mock object is a dummy implementation for an interface or a class in which you define the output of certain method calls. Mock objects are configured to perform a certain behaviour during a test. They typical the interaction with the system and test can validate that.
- Configure (mock or spy)
- Define output (stub)
- Call verify (verify interaction)
http://www.vogella.com/tutorials/Mockito/article.html
The Mockito Basics
- Create a Mock
- Verify
- Stubbing
- Iterating
- Argument Captor
- Spy
Creating a Mock
- A Mock has the same method calls as the normal object
- However, it records how other objects interact with it
- There is a Mock instance of the object but no real object instance
- List example
- Let’s import Mockito statically so that the code looks clearer
import static org.mockito.Mockito.*;- //mock creation
List mockedList = mock(List.class);- Or @Mock List mockedList;
Verify
- “Once created, a mock will remember all interactions. Then you can selectively verify whatever interactions you are interested in.”
- Let’s mock a List and use the add function
mockList.add(“one”);verify(mockedList).add(“one”);verify(mockedList).add(“two”);//will fail because we never called with this value
- You can verify number of invocations
verify(mockedList, times(2)).add(“one”);/ /will fail since called onceverify(mockedList, atLeast(2)).add(“one”);//will fail since called once
Verify no more interactions
- Checks if any of given mocks has any unverified interaction.
“//using mocks
mockedList.add("one");
mockedList.add("two");
verify(mockedList).add("one");
//following verification will fail verifyNoMoreInteractions(mockedList);
Stubbing
- Return the whatever value we passed in
- Or “By default, for all methods that return a value, a mock will return either null, a primitive/primitive wrapper value, or an empty collection, as appropriate. For example 0 for an int/Integer and false for a boolean/Boolean.”
- Examples
when(mockedList.get(0)).thenReturn("first");
when(mockedList.get(1)).thenThrow(new RuntimeException());
Basic Mock Conclusions
-
Verify is critical as it allows us to determine what was passed to a mocked method by the method under test
- Asserts only check returned values
- Verify checks that a method is called
-
Examples
verify(mockStorage).barcode("1A");
verify(mockDisplay).showLine("1A");
verify(mockDisplay).showLine("Milk, 3.99");
- We still use asserts when we test values of the class/method under test
- “when” allows us to stub our method
when(mockStorage.barcode("1A")).thenReturn("Milk, 3.99");
Stubbing Gotchas
- Once stubbed, the method will always return a stubbed value, regardless of how many times it is called.
- Last stubbing is more important - when you stubbed the same method with the same arguments many times.
//All mock.someMethod("some arg") calls will return "two"
when(mock.someMethod("some arg")) .thenReturn("one")
when(mock.someMethod("some arg")) .thenReturn("two")
- How would you Stub the Stack?
Stubbing consecutive calls (iterator-style stubbing)
when(mockedStack.pop()).thenReturn(3,2,1);
Verify InOrder
- Want to ensure that the interactions happened in a particular order
List singleMock = mock(List.class);
//using a single mock
singleMock.add("was added first");
singleMock.add("was added second");
//create an inOrder verifier for a single mock
InOrder inOrder = inOrder(singleMock);
//following will make sure that add is first called with "was added first", then with "was added second"
inOrder.verify(singleMock).add("was added first");
inOrder.verify(singleMock).add("was added second");
- // B. Multiple mocks that must be used in a particular order
- Check that the verify of the call of mockStorage to the barcode happens before the call of mockDisplay to showline
- Use the InOrder class
//the order of calls in mockDisplay and moStorage will be tracked together
InOrder inOrder = inOrder(mockDisplay, mockStorage);
inOrder.verify(mockStorage).barcode("1A");
inOrder.verify(mockDisplay).showLine(“Milk, 3.99");
Verify InOrder with verifyNoMoreInteractions
mock.foo(); //1st
mock.bar(); //2nd
mock.baz(); //3rd
InOrder inOrder = inOrder(mock);
inOrder.verify(mock).bar(); //2n
inOrder.verify(mock).baz(); //3rd (last method)
//passes because there are no more interactions after last method:
inOrder.verifyNoMoreInteractions();
//however this fails because 1st method was not verified: Mockito.verifyNoMoreInteractions(mock);
Argument Captor
- Capture the value that is passed in
- Essential call verify and ask what was passed in
- Set it up for barcode(String barcode)
ArgumentCaptor<String> argCaptor = ArgumentCaptor.forClass(String.class);
- Capture what was passed to barcode
verify(mockStorage).barcode(argCaptor.capture());
//this line verifies the barcode function is called and remembers what is the input for the bar code function
- Use that arg value later to verify what was displayed
verify(mockDisplay).showLine(argCaptor.getValue());
// to ensure the same values are called in both barcode and showLine
Spying on real objects
- You can create spies of real objects. When you use the spy then the real methods are called (unless a method was stubbed).
- Let’s spy the LinkedList
List list = new LinkedList();
List spy = spy(list);
//optionally, you can stub out some methods:
when(spy.size()).thenReturn(100);
//using the spy calls *real* methods
spy.add("one");
- Spys have lots of Gotchas so avoid as much as possible
- Use only when you have legacy code that you can’t completely Mock out
Some Additional Tutorials
OO Integration
OO Integration Levels
- Classes introduce different scopes of integration testing: the testing of interactions among classes (inter-class testing), related through dependencies, i.e., association, composition, inheritance
Cluster integration
- Integration of two or more classes through inheritance (cluster) incremental test of inheritance hierarchies
- Integration of two or more classes through containment (cluster)
- Integration of two or more associated classes / clusters to form a component (i.e., subsystem)
- Big bang, bottom-up, top-down, scenario-based
- Integration of components into a single application (subsystem/system integration)
- Similar techniques for cluster integration also applicable at this level (big bang, bottom-up, top-down, use case-based)
- Client/server integration
Testing and Inheritance
- Should you retest inherited methods?
- Can you reuse superclass tests for inherited and overridden methods?
- To what extend should you exercise interaction among methods of all superclasses and of the subclass under test?
Inheritance
- In the early years people thought that inheritance will reduce the need for testing
- Claim 1: “If we have a well-tested superclass, we can reuse its code (in subclasses, through inheritance) with confidence and without retesting inherited code”
- Claim 2: “A good-quality test suite used for a superclass will also be sufficient for a subclass” Both claims are wrong.
Integration and Inheritance
- Makes understanding code more difficult
- Instance variables similar to global variables with respect to individual methods
- Test suite for a method almost never adequate for overriding methods
- Necessary to test inherited method in the context of inheriting classes
- Accidental reuse (inherited method not built for reuse)
- Multiple inheritance (multiple test cases needed, possibility of incorrect binding, repeated inheritance)
- Abstract classes need instantiation
- Generic classes
Interactions you may miss #1: Inherited methods should be retested in the context of a subclass
- Modifying a superclass: we have to retest its subclasses (expected)
- Add a subclass (or modify an existing subclass): we may have to retest the methods inherited from each of its ancestor superclasses, because subclasses provide new context for the inherited methods
- No problems if the new subclass is a pure extension of the superclass:
- Adds new instance variables and methods but there are no interactions in either directions between the new instance variables and methods and any inherited instance variables and methods
Add a subclass (or modify an existing subclass): excepted case
Testing of Inheritance
- Principle: inherited methods should be retested in the context of a subclass
- Example: if we change some method m in a superclass, we need to retest m inside all subclasses that inherit it
Inheritance: Simple Example
inherited methods should be retested in the context of a subclass
If we add a new method m2 that has a bug and breaks the invariant, method m is incorrect in the context of B even though it is correct in A
- Therefore, m should be tested in B
- The example illustrates that even if a method is correct in the superclass, it may become incorrect in the subclass if the subclass introduces changes that affect the behaviour or assumptions of the inherited methods.
- Therefore, retesting inherited methods in the context of subclasses ensures the correctness and integrity of the software’s behaviour.

Inheritance: Another Example
set_desired_temperature()allows the temperature to be between 5°C and 20°Ccalibrate()puts the actual refrigerator through cooling cycles and uses sensor readings to calibrate the cooling unit.- A new more capable model of refrigerator is created and can cool to – 5°C
- class
better_reefrigerator- a new version of
set_desired_temperature()calibrate()is unchanged- Should
better_refrigerator::calibrate()be retested? It has the exact same code?
- Yes, it has to be re-tested!
- Supposed that calibrate works by dividing sensor readings by temperature
- In
better_refrigerator, it is possible that temperature is 0°C causes a divide by 0 failure incalibrate()which cannot happen in refrigerator

Interactions you may miss #2: Overriding of Methods
- OO languages allow a subclass to replace an inherited method with a method of the same name
- The overriding subclass method has to be tested but different test sets are needed!
- Reason 1: if test cases are derived from a program structure (data and control flow), the structure of the overriding method may be different
- Reason 2: the overriding method behaviour (input/output relation) is also likely to be different
Inheritance: Simple Example
- If inside B we override a method from A, this indirectly affects other methods inherited from A.
- e.g., method m calls B.m2, not A.m2: so we cannot be sure that m is correct anymore and we need to retest it inside B
- Test cases developed for a method m defined in A are not necessarily sufficient for retesting m in subclasses of A
- e.g., if m calls m2 in A and then some subclass overrides m2 we have a completely new interaction that may not be covered well by the old test cases for m
- Still it is essential to run all superclass tests on a subclass
- Goal: check behavioural conformance of the subclass w.r.t the superclass
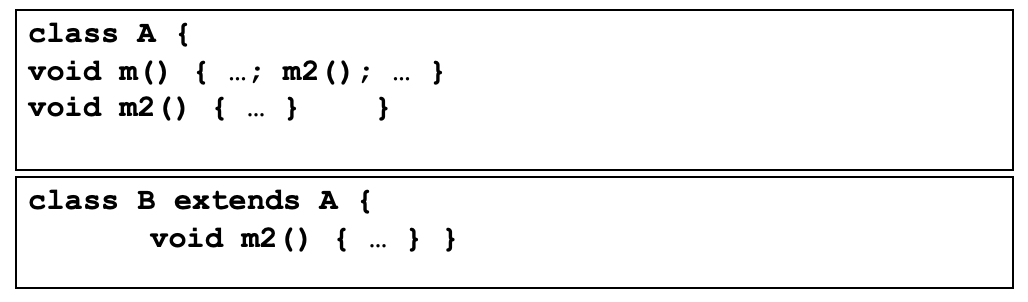
Inheritance: Another Example
- Test case 1: invokes
Base::foo()which in turns callsBase::helper()- Test case 2: the inherited method
Base::bar()is invoked on the derived object, which in turn callshelper()on the derived object, invokingDerived::helper()- Assuming all methods contain linear control flow only, do the test cases fully exercise the code of both
BaseandDerived?- Yes, according to traditional control flow coverage measures (e.g., statements, branches)
- Did we miss anything?
- We have not fully tested all interactions between
BaseandDerived!
Base::bar()andBase::helper()Base::helper()andDerived::helper()- Just because
Base::foo()works withBase::helper(), it does not mean that it will automatically work withDerived::helper()Base::helper()andDerived::helper()have identical interfaces, but (may have) different implementations- We need to exercise
foo()andbar()for both theBaseandDerivedclassNew test driver is needed…
- Exemplifies why inheritance has to be used with care - it leads to more testing!


Interactions you may miss #3: Integration and Polymorphism
Inheritance Context Coverage
- Coverage, regardless of the specific criterion used, if adapted to inheritance is not enough
- Extend the interpretation of traditional structural coverage meaesures
- Consider the level of coverage in the context of each class as separate measurements
- 100% inheritance context coverage requires the code must be fully exercised (for any selected criteria, e.g., all branches) in each appropriate context
- We need to exercise interactions between methods: in other words, we need to test method sequences
Testing abstract classes
- Abstract classes cannot be instantiated
- However, they define an interface and behaviour (contracts) that implementing classes will have to adhere to
- We would like to tests abstract classes for functional compliance
- Functional Compliance is a module’s compliance with some documented or published functional specification
Some prof's note
Explanation using abstract/concerete web services (e.g., Instagram): upload → filterBW
For abstract upload, you can have the following three concrete services:
- uploadFast
- uploadBig
- uploadRobust
Abstract test cases ensure these concrete services conforms to the suggested behaviour
Functional vs. Syntactic Compliance
- The compiler can easily test a class is syntactically compliant to an interface
- All methods in the interface have to be implemented with the correct signature
- Tougher to test functional compliance
- A class implementing the interface
java.util.Listmay be implementingget(int index)orisEmpty()incorrectly
- A class implementing the interface
- Think LSP…
Abstract Test Pattern
- This pattern provides the following
- A way to build a test suite that can be reused across descendants
- A test suite that can be reused for future as-yet-unidentified descendants
- Especially useful for writers of APIs.
An example
Consider a statistics application

Abstract Test Pattern Rule I
- Write an abstract test class for every interface and abstract class
- An abstract test should have test cases that cannot be overridden
- It should also have an abstract Factory Method for creating instances of the class to be tested.
Test cases that cannot be overridden → declare as “final”
Example abstract test class


Abstract Test Pattern Rule II
- Write a concrete test class for every implementation of the interface (or abstract class)
- The concrete test class should extend the abstract test class and implement the factory method
Example concrete test class
Only a few lines of code and all the test cases for the interface have been reused

Guidelines
- Tests that define the functionality of the interface belong in the abstract test class
- Tests specific to an implementation belong in a concrete test class
- We can add more test cases to
TestSuperSlowStatPakthat are specific to its implementation
- We can add more test cases to
Summary:
Abstract Test Pattern:
- Purpose:
- Provides a way to build a test suite that can be reused across descendants of an interface or abstract class.
- Offers a test suite that can be reused for future implementations not yet identified, particularly beneficial for API writers.
- Rule I: Abstract Test Class:
- Write an abstract test class for every interface and abstract class.
- Abstract tests should include test cases that cannot be overridden, typically declared as “final” to prevent overriding.
- Abstract test classes should also contain an abstract Factory Method for creating instances of the class being tested.
- The Factory Method is abstract and must be implemented by concrete subclasses to return instances of the concrete class being tested.
- Test cases defining the functionality of the interface or abstract class belong in the abstract test class.
- Rule II: Concrete Test Class:
- Write a concrete test class for every implementation of the interface or abstract class.
- The concrete test class should extend the abstract test class and implement the Factory Method to return instances of the concrete class being tested.
- Tests specific to the implementation of the interface or abstract class belong in the concrete test class.
Example:
- In the provided example,
TestStatPakis the abstract test class for theStatPakinterface. - Concrete test classes such as
TestSuperSlowStatPakextendTestStatPakand implement the Factory Method to return instances of the concrete class being tested (SuperSlowStatPak). - Tests defining the functionality of the
StatPakinterface, such astestMean()andtestStdDev(), belong inTestStatPak. - Additional test cases specific to the implementation of
SuperSlowStatPakcan be added toTestSuperSlowStatPak.
Inter-class (cluster) Integration
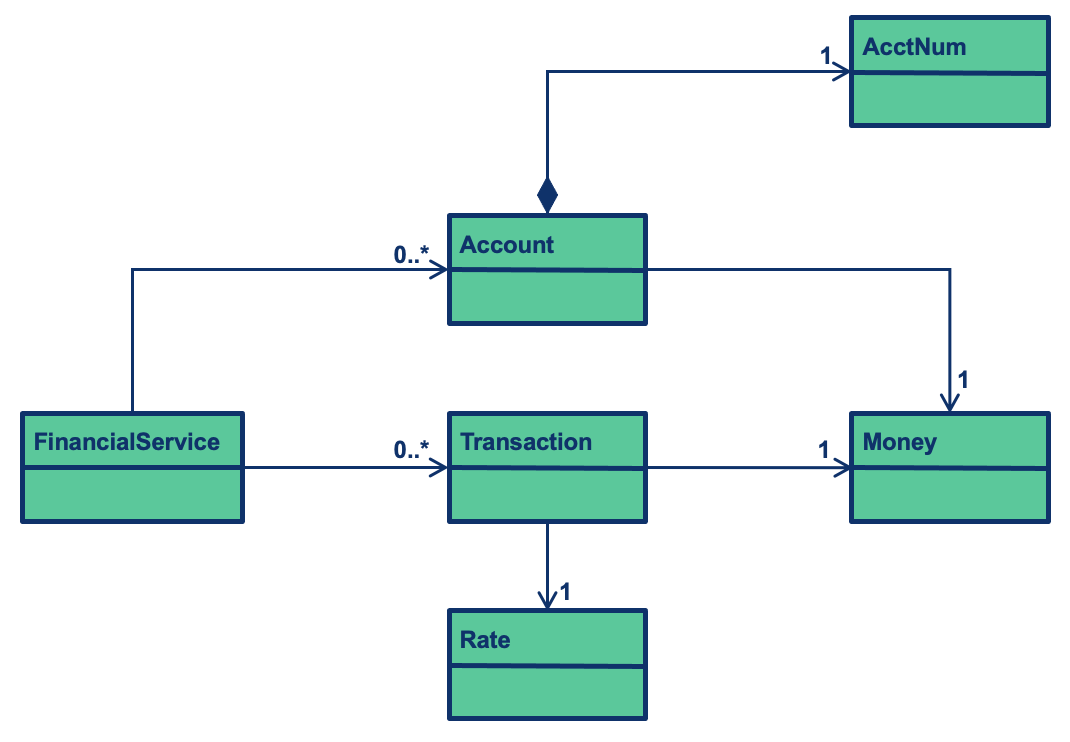
Cluster Integration
- Needs a class dependency tree
- Dependency structure not always that clear-cut
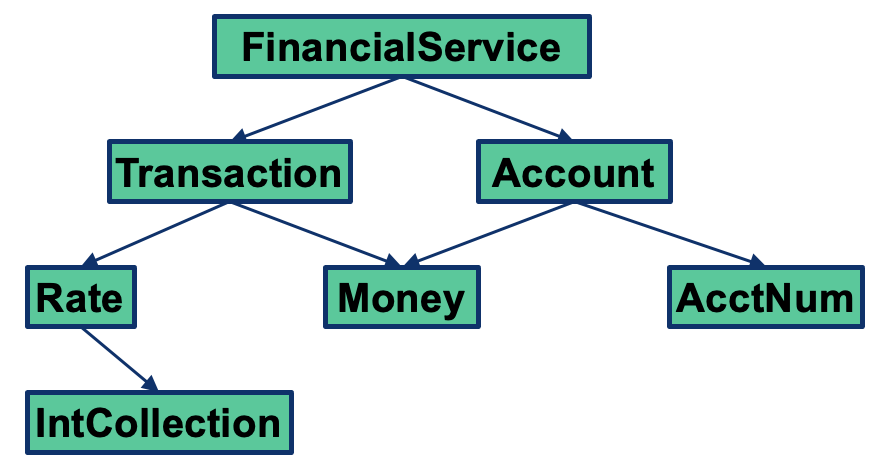
Cluster Integration: Big Bang
- Recommend only when:
- Cluster is stable, only few elements added/changed
- Small cluster
- Components are very tightly coupled (i.e., impossible to test separately in practice)
Cluster Integration: Bottom-Up
Most widely used technique: Integrate classes starting from leaves and moving up in dependency tree
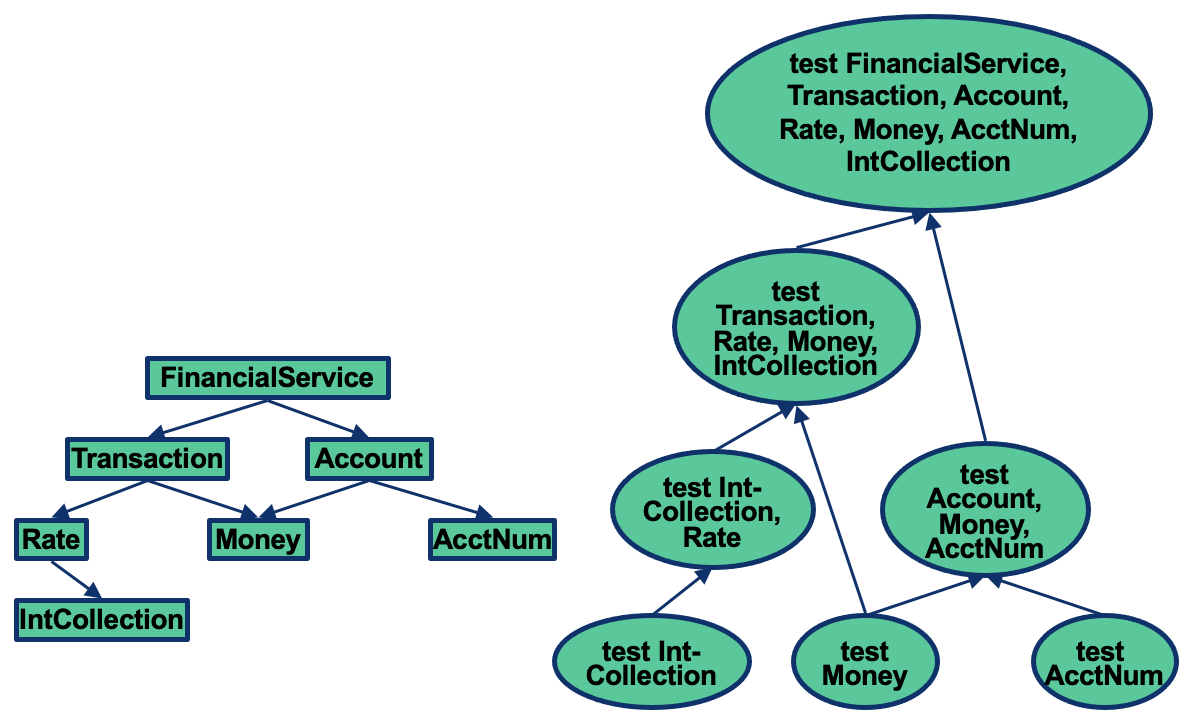
Cluster Integration: Top Down
Widely used technique: Integrate classes starting from the top and moving down the dependency tree to leaves
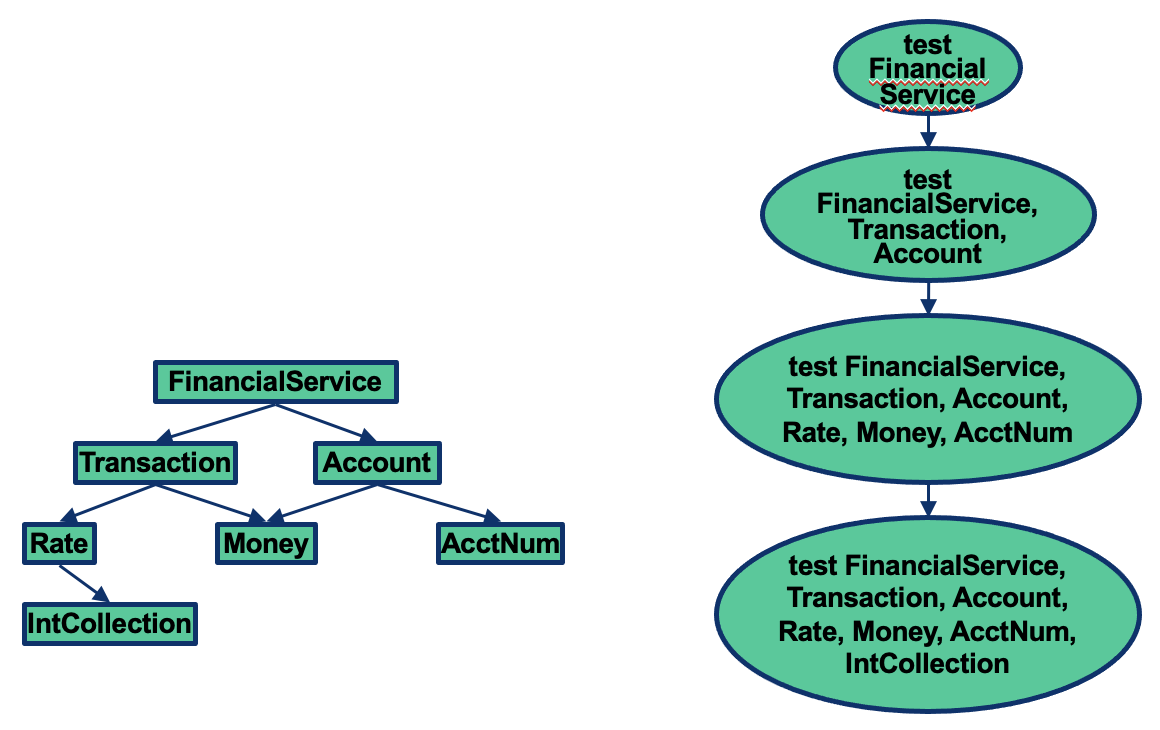
Cluster Integration: Scenario-Based
- Scenario:
- Describes interaction (collaboration) of classes
- E.g., represented as interaction diagrams
- Approach:
-
- Map collaboration onto dependency tree
-
- Choose a sequence to apply collaborations (e.g., simplest first, with fewest stubs first, …)
-
- Develop and run test exercising collaboration
-
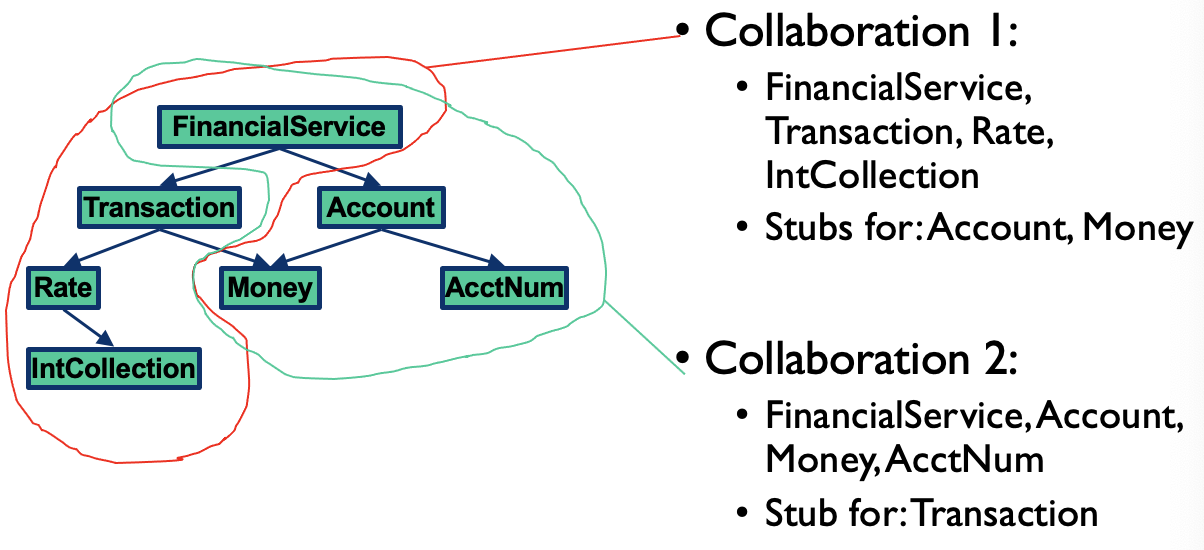
Integration Order Problem
- It is not advised to perform a big-bang integration of classes; integration must be done in stepwise manner, but this leads to stubs
- It is not always feasible to construct a stub that is simpler than the actual piece of code it simulates
- Stub generation cannot be automated because it requires an understanding of the semantics of the simulated functions
- The fault potential for some stubs may be the same or higher than that of the real function
- Minimizing the number of stubs to be developed should result in drastic savings
- Class dependency graphs usually do not form simple hierarchies but complex networks
- Most OO Systems:
- Strong connectivity
- Cyclic interdependencies
Sample Systems with Cycles
- ATM (Automated Teller Machine)
- Ant: Java based tool (open source project)
- SPM (Security Patrol Monitoring)
- BCEL (Byte Code Engineering Library): tool to manipulate Java class files (open source project)
- DNS (Domain Naming System): network naming services in Java
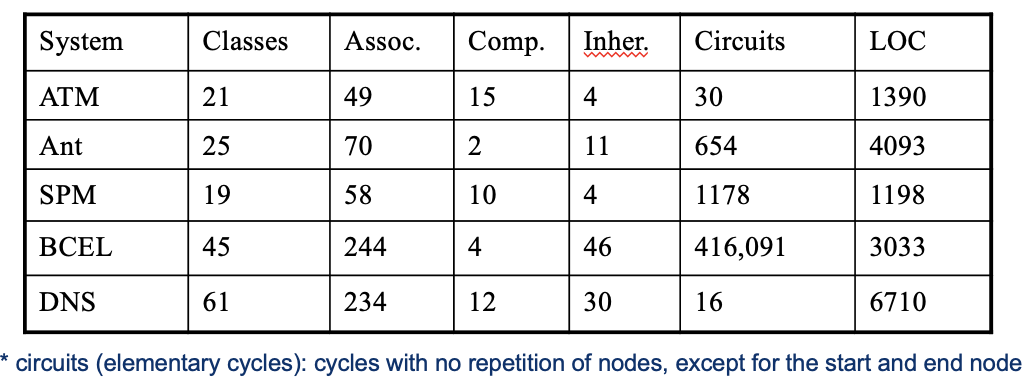
Kung et al. Strategy
- Aims at producing a partial ordering of testing levels based on class diagrams
- Classes under test at a given level should only depend on classes previously tested
- No stub is required since previously tested classes can be included in subsequent testing levels
- Class dependency information can either come from reverse engineering or design documentation (e.g., UML)
Object Relation Diagram (ORD)
- Uses static information only
- The ORD for a program P is an edge-labeled graph where the nodes represent the classes in P, and the edges represent the inheritance, composition, and association relations
- For any two classes C1 and C2
- Edge labeled I from C1 to C2: C1 is a subclass of C2
- Edge labeled C from C1 to C2: C1 is composed of C2 (C1 contains one or more C2 instances)
- Edge labeled A from C1 to C2: C1 associates with C2 (bidirectional association two edges)
What is static information?
ORD Example
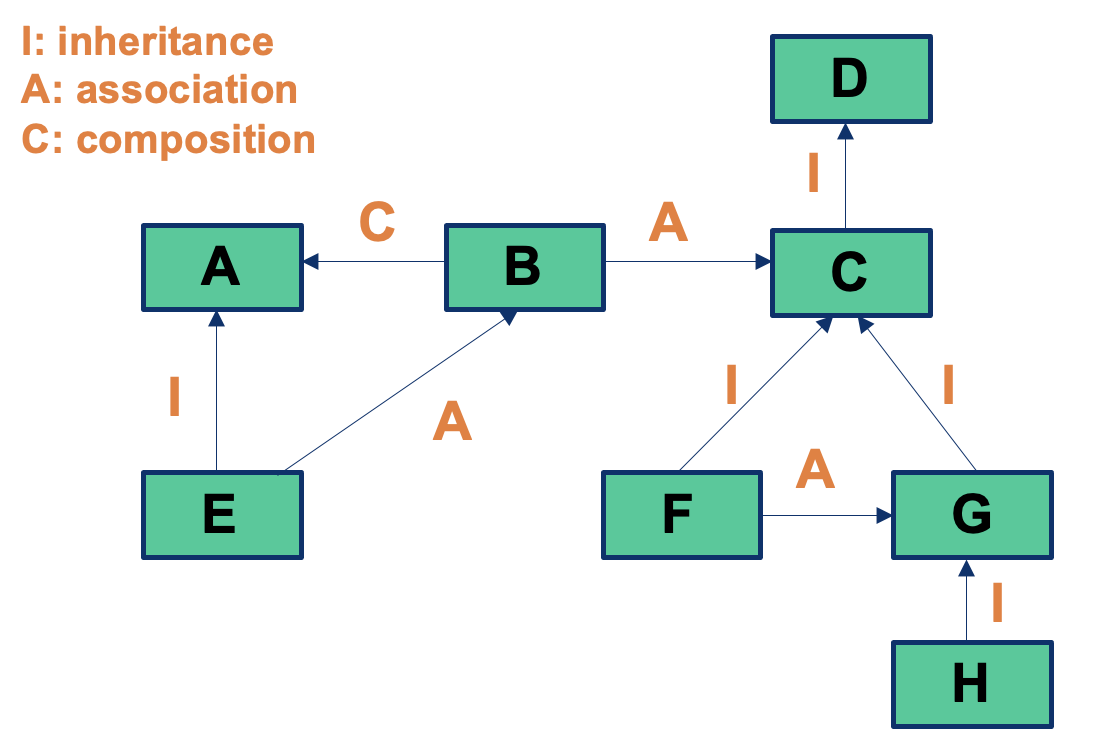
Class Firewall (CFW)
- Identify the effect of a class change at the class level
- CDW(X) for a class X: set of classes that could be affected by a change to class X, i.e., that should be retested when class X is changed
- Assuming the ORD is not modified by the change, Kung et al. argue that, for adequate testing, CFW(X) has to include: subclasses of X, classes composed with X, and the classes associated with X
Firewall Example
- Transitive closure of incoming edges (may lead to large set)
Notice, the CFW(X) is always the classes that has an arrow pointing to X.
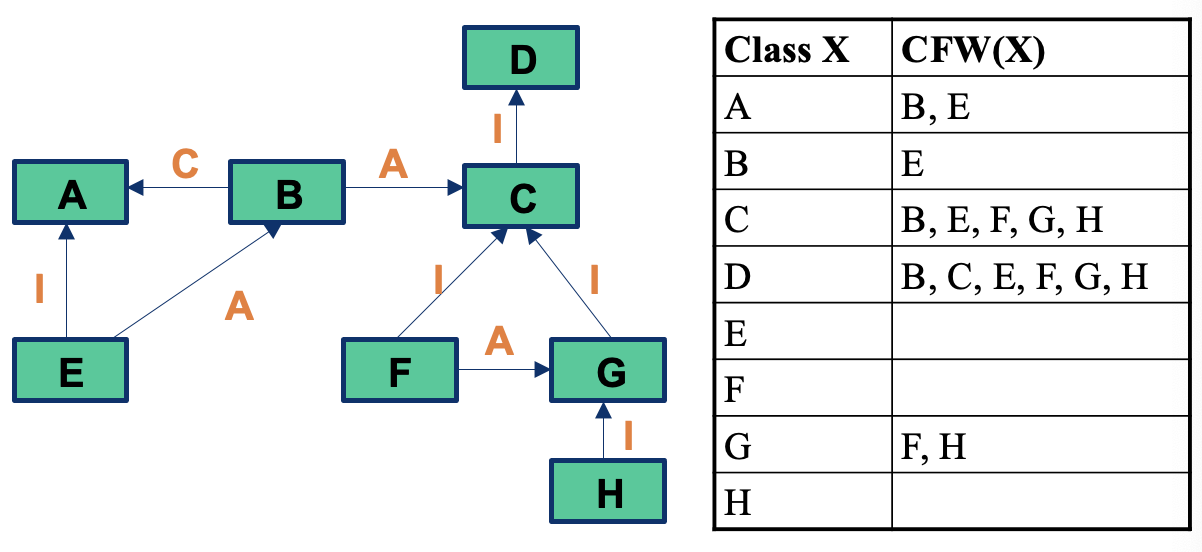

(more formal def’n of previous example)
- Last point: for a change that contains multiple classes, the CFW is the union of the CFWs of each changed class
Test (Partial) Order
- Provides the tester with a road map for conducting integration testing
- Desirable order is the one that minimizes the number of stubs or stubbing effort
- Test the independent classes first, then test the dependent classes based on their relationships
- E.g., testing a class C before the class D that contains it allows the tester to use the actual class C instead of stubs
- Similarly, a subclass would be tested after its superclass(es)
Integration Order of Acyclic ORDs
- Can generate a test order that ensures that X is tested before all the classes of CFW(X)
- Stubs are not required
- 4 successive testing levels for the example as shown next
- Several classes at same level partial order
- Kung et al.’s technique is simply a topological sorting, in graph theory terms
Prof's note
2nd last point: Since there are several classes at the same level, we call it a partial order
Example Test Order
Also useful for regression testing: A and D changes CFW({A,D}) = {B,C,E,F,G,H}, i.e., all classes must be retested
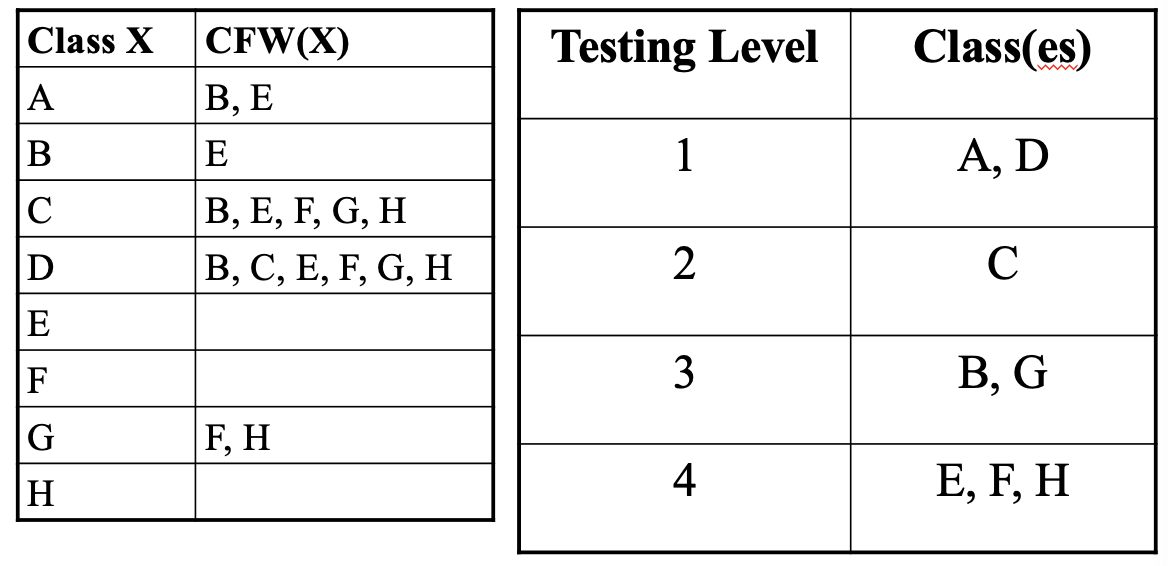
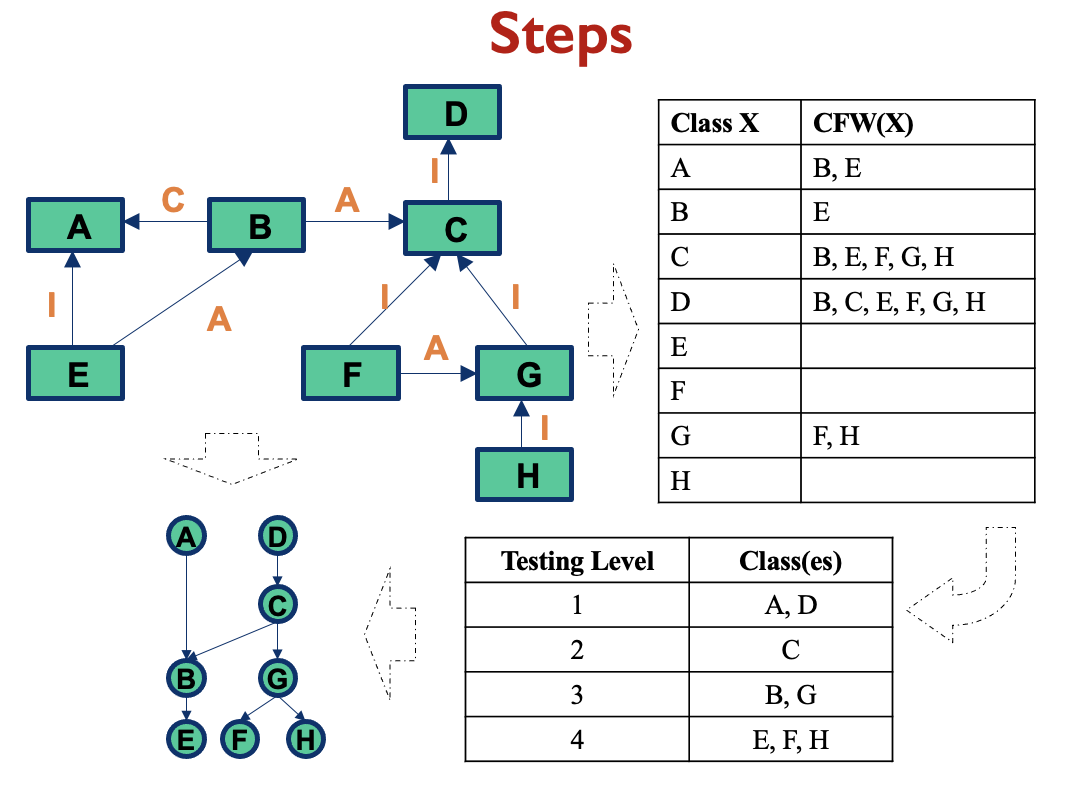
Prof's note
Use pen tool to draw on slide:
Look for all classes that do not occur in the CFW(X) column add them to testing level
Cross out a row after adding a class to testing level
Repeat until no rows left
Dynamic Binding
- Dynamic (execution time) relationships between classes are not taken into account by Kung et al.
- Class F associates with G which is a parent of class H
- Due to polymorphism, F may dynamically associate with H and thus, should be tested after H
- F and H should not be tested in any order as stated before
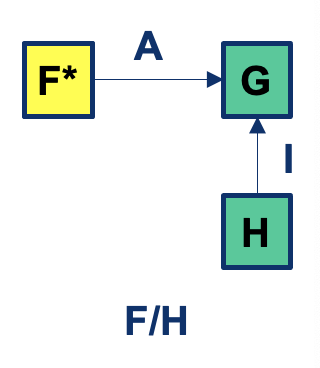
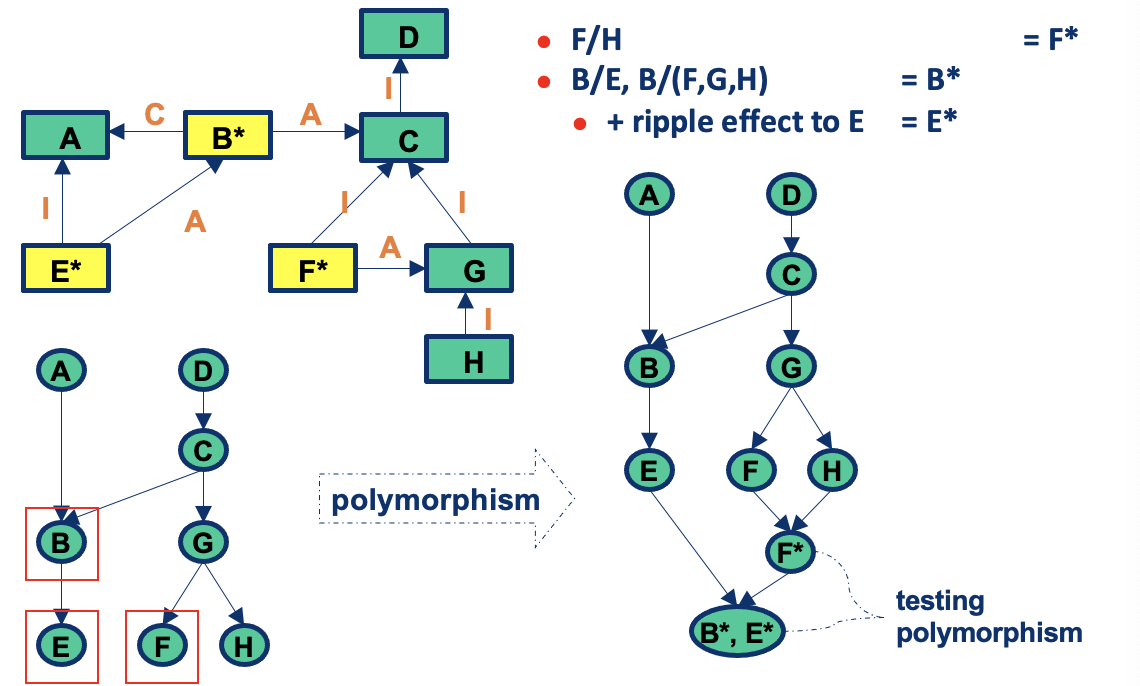
- Since H inherits from G and F associates with G, F* is created
- Since F, G, and H inherit from C and B associates with C, B* is created
- Since E inherits from A and A is composed of B, we have a ripple effect that spreads from B* to E*
- We do not presume any integration test technique
- B*: Test polymorphic interfaces of B/E, B/(F, G, H)
- E*: Test polymorphic interfaces of E/B/(F,G,H)
- F*: Test polymorphic interfaces of F/H
Abstract Classes
- Some testing levels become (partly) infeasible because of abstract classes (shown in italic)
- If A is an abstract class, testing it at level 1 is unworkable
- Testing B at level 3 now requires subclass E to be instantiated (instead of A)
- E cannot be tested after B

- and same Testing level table as before (same example)
A and G are abstract:
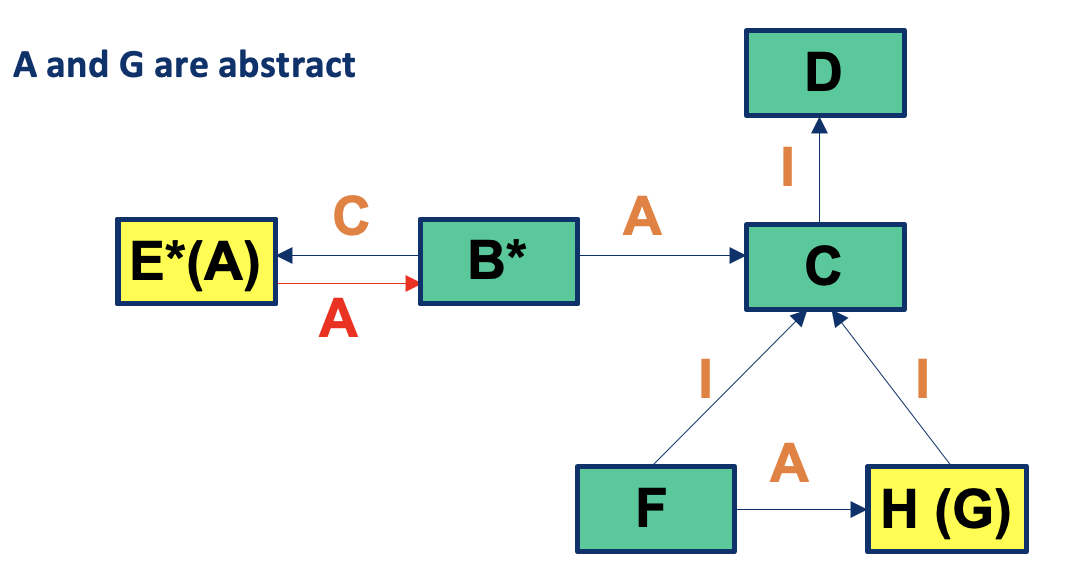
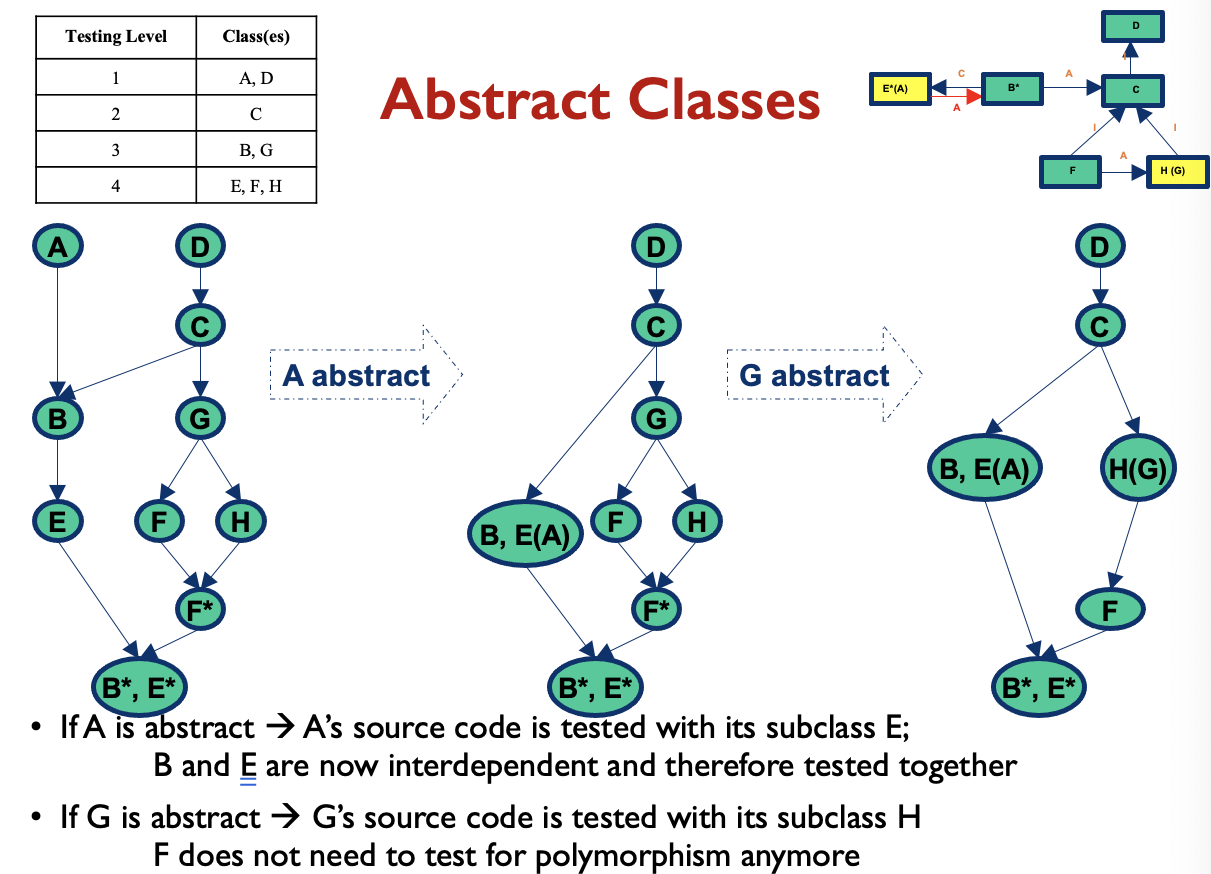
ORD Example (II)
A is abstract (shown in italic).
Integration Order (II) A is abstract
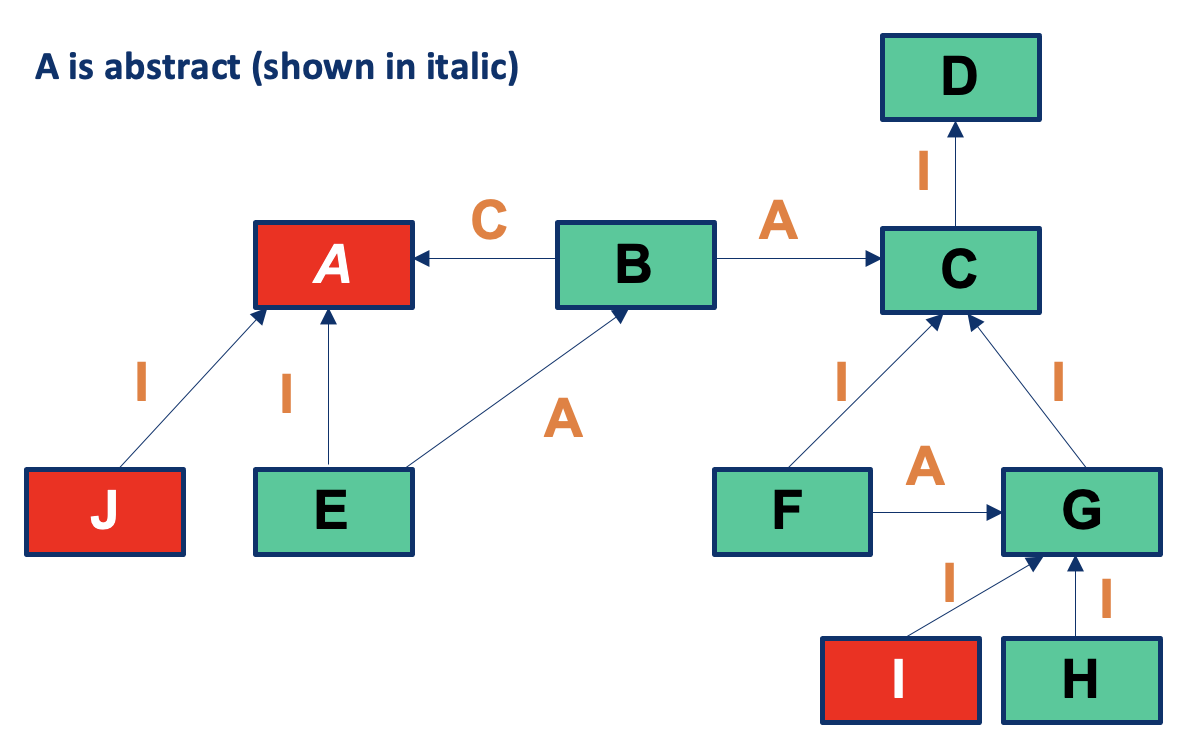
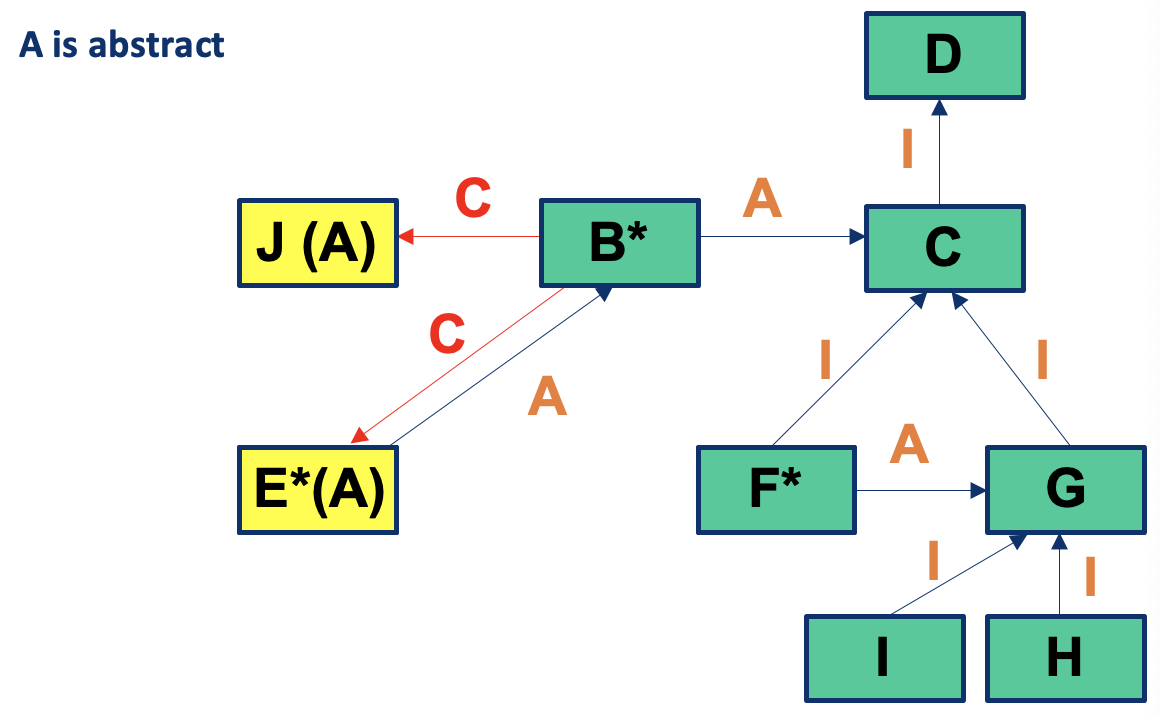
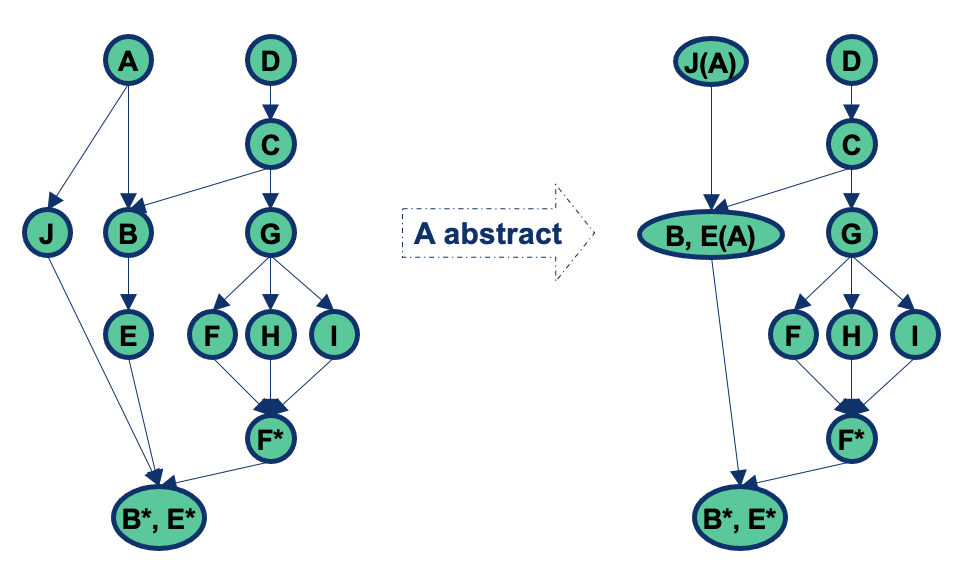
Cyclic ORDs
- In practice, ORDs are often cyclic
- This is due to performance needs, poor design, late changes, …
- Topological sorting cannot be applied
- Cluster:
- Maximal set of nodes that are mutually reachable through the relation R+ (strongly connected component in graph theory)
- Cycle breaking: identify and remove an edge from a cluster and repeat until the graph (in the cluster) becomes acyclic
Which relation edge(s) to remove?
- Each deletion results in at least one stub
- Inheritance: many inherited, non-overridden methods must be re-tested in subclasses stubbing a parent class is therefore out of question
- Composition: usually involves intense interactions not good for stubbing
- Association: yes!
- Theorem: every directed cycle always contains at least one association edge
- If there is any choice, it would be wise to select the association that leads to the development of the simplest stub possible
Prof's note
Why is this theorem true?
Inheritance and composition are acyclic by definition!
Cycle and Polymorphism
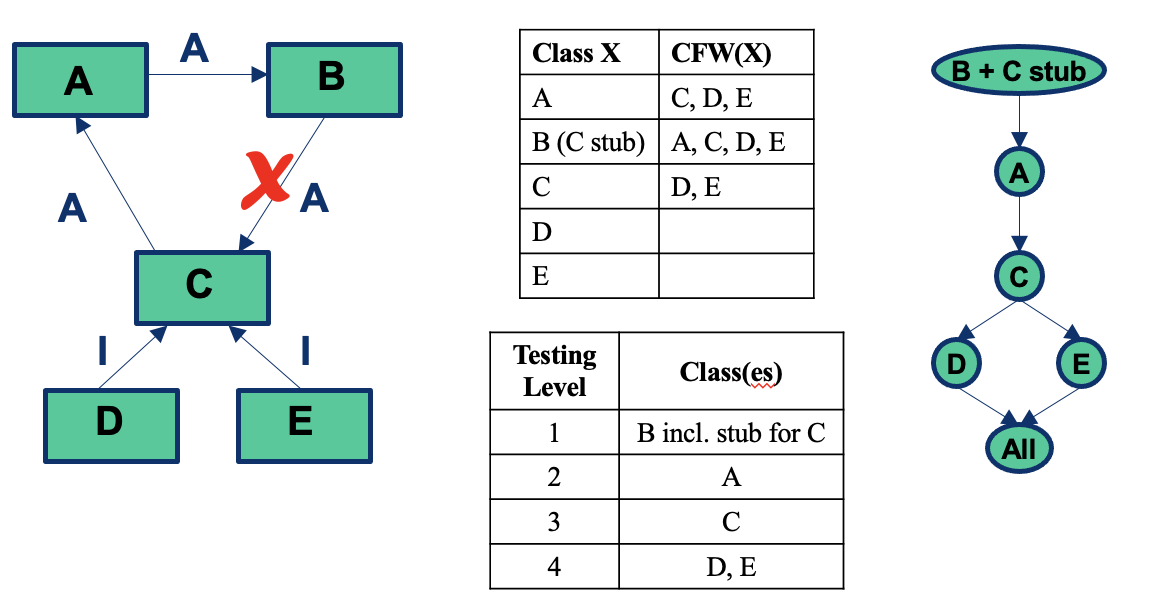
- Depending where the cycle is broken, the resulting test order is very different
Defining the ORD
- Class dependency information in Object Relation Diagram (ORD) can either come from reverse engineering or design documentation (e.g., UML)
- Straightforward for UML
- Inheritance, composition, association in UML map directly to ORD
- How should interface be handled?
- From source code?
- Inheritance, interface?
- Typically clear
- Association or composition?
- E.g., in Java, fields with type of other class
- Lifecycle is linked for composition (may be tricky to determine with automatic garbage collection)
- Inheritance, interface?
Prof's note
Composition is strong form of aggregation (where deleting whole deletes the parts too)
Difficult to determine in Java due to garbage collection
- From source code?
- What about dependencies that are not expressed by inheritance, composition, or association?
- E.g., a factory creates an object and returns it to the caller (Relationship of factory with class of the object is not inheritance, not composition, and not association – there is no field in the factory with the class as its type! However, the factory cannot be tested without the class.)
- E.g., passing in an object as a parameter
- E.g., creating an object in a method as a local variable
- Dependencies like that also need to be captured with an A edge in the ORD
Note
Look at the imports for clues!
Week 5
First, Refer to Integration Order for more exercises!!!!
Testing OO: Data slice testing
Sequences: Motivation & Issues
- It is argued that testing a class aims at finding the sequence of operations for which a class will be in a state / has produced output that is contradictory to its expected results
- state-based testing, data flow-based testing across methods
- Testing classes for all possible sequences is not usually possible – the resources required to test a class increase exponentially with an increase in the number of its methods
- It is necessary to devise a way to reduce the number of sequences and still provide sufficient confidence
Example: CCoinBox
Coin box of a vending machine implemented in C++
The coin box has a simple functionality and the code to control the physical device is omitted
It accepts only quarters and allows vending when two quarters are received
It keeps track of total quarters received when an item is sold (totalQrts), the current quarters received (curQrts), and whether vending is enabled (allowVend)
Functions: adding a quarter, returning current quarters, resetting the coin box to its initial state, and vending
The following is possible {
AddOtrs();AddOtrs();ReturnOtrs();Vend()} FREE DRINKS!This is a state dependent fault, in the sense that executing some operations turns out not to be possible in certain states where they are legal or, alternatively that some operation sequences which should not be possible are nevertheless executed
Method structural testing would conclude that, e.g., each branch has been executed – the omission may remain undetected even with functional testing
The failure results from involving a certain sequence of operations method testing alone is not enough!

Fault
A fault in the
ReturnQtrs()method, where it fails to reset theallowVendflag, leads to unintended behaviour where vending is allowed even after returning quarters.This fault is state-dependent, meaning it only manifests in certain states of the object, highlighting the importance of testing sequences of operations.
Data Slices: Basic Principles
- Goal: reduce the number of method sequences to test
- The (concrete) state of an object at a single instant of time is equivalent to the aggregated state of each of its data members at that instant
- The correctness of a class depends on
- Whether the data members are correctly representing the intended state of an object
- Whether the member functions are correctly manipulating the representation of the object
Data Slices: Approach
- A class can be viewed as a composition of data slices
- A data slice is a portion of a class with only a single data member and a set of member functions such that each member function can manipulate the values associated with this data member
- Test one slice at a time
- For each slice, test possible sequences of the methods belonging to that slice (one occurrence) – equivalent to testing a specific data member, i.e., class partial correctness
- Repeat for all slices to demonstrate class correctness
Data Slices: Issues
- This is a code-based approach many potential problems
- What if the code is faulty and a method that should access a data member does not? sequences of methods that interact through that data member will not be tested and the fault may remain undetected
- How to identify legal sequences of methods?
- What strategy to use when there is a large, possibly infinite, number of legal sequences?
Example: SampleStatistic
Part of the GNU C++ library


Generate MaDUM
- MaDUM: Minimal Data Member Usage Matrix
- matrix where is the number of data members and represents the number of member methods •– it reports on the usage of data members by methods
- Difficult usage categories: constructors, reporters (read only), transformers, others
- A poor design may make such classification difficult to apply
- Account for indirect use of data members, through intermediate member functions
Create call graph
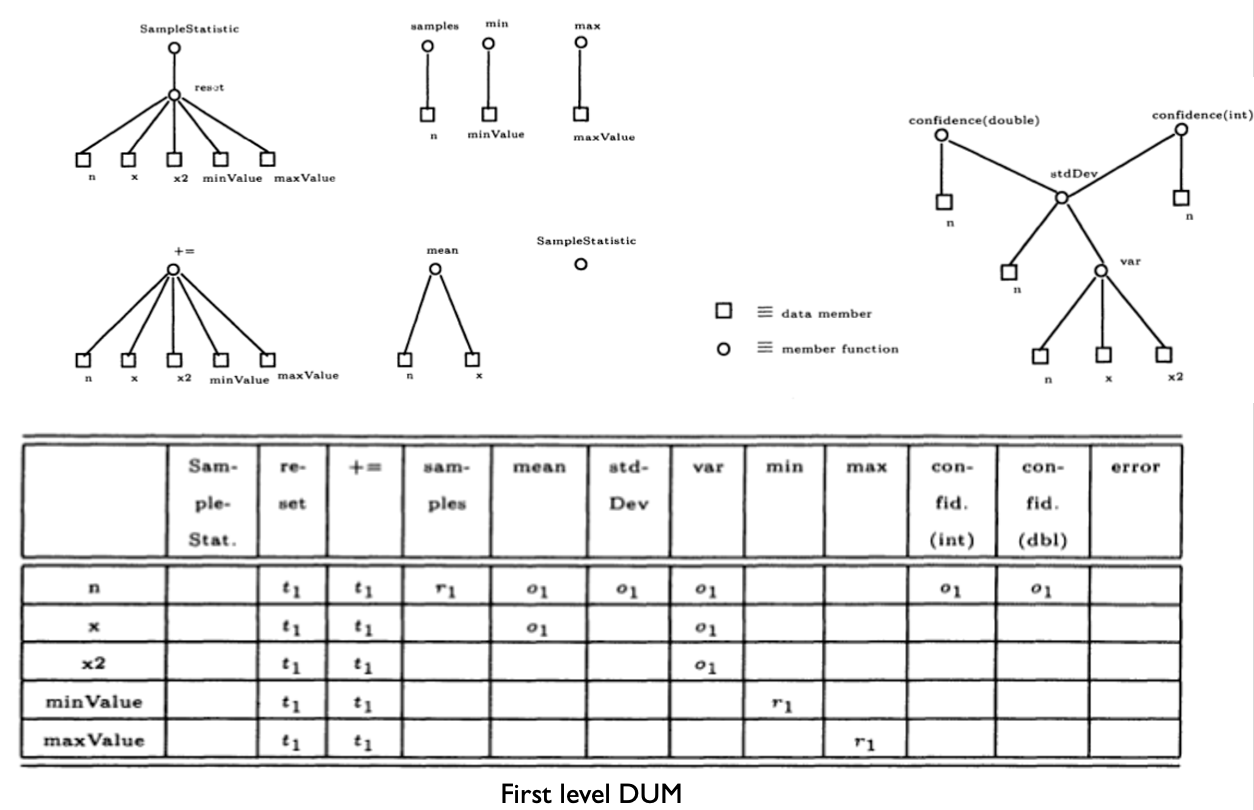
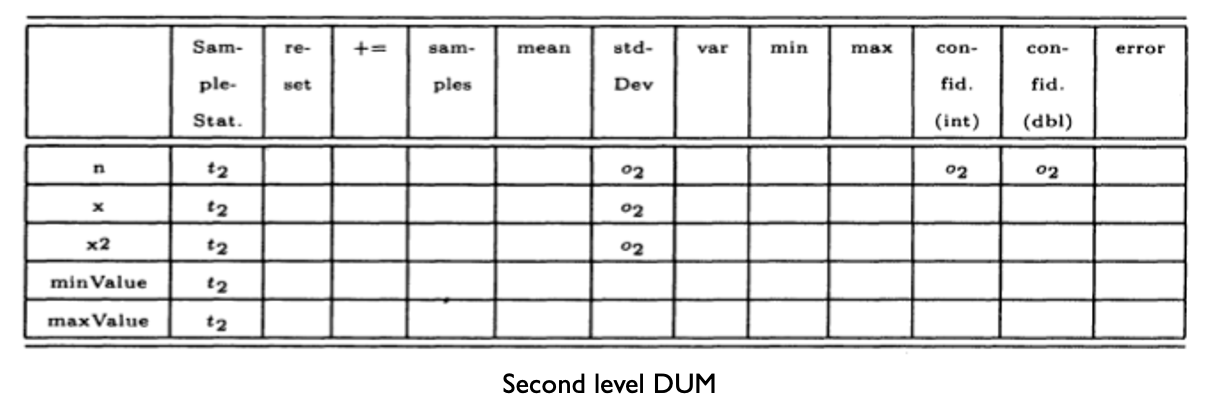

SampleStatistic: DUM
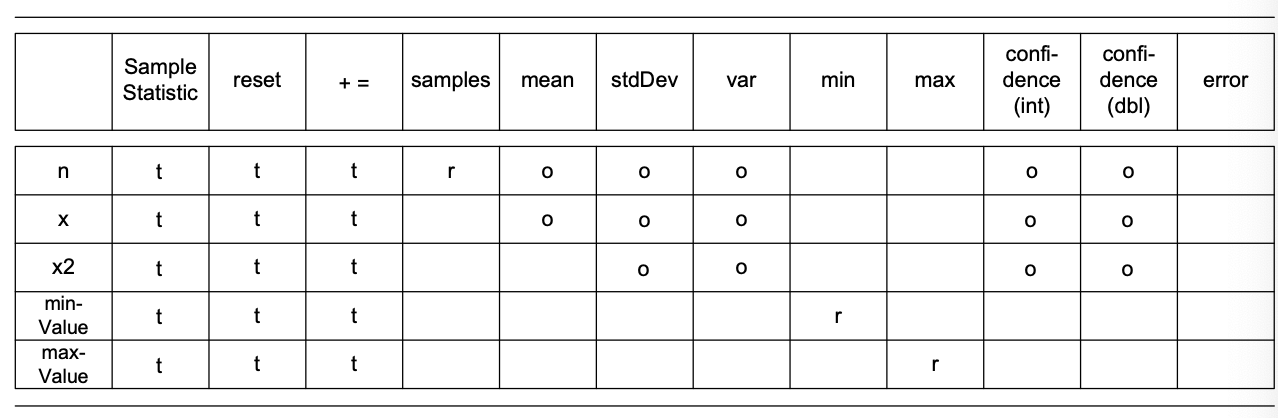
- Matrix accounts for indirect use, through called methods
stdDev()does not directly accessxandx2, but callsvar()that does- All
SampleStatistic()does is callreset() - Some are redundant
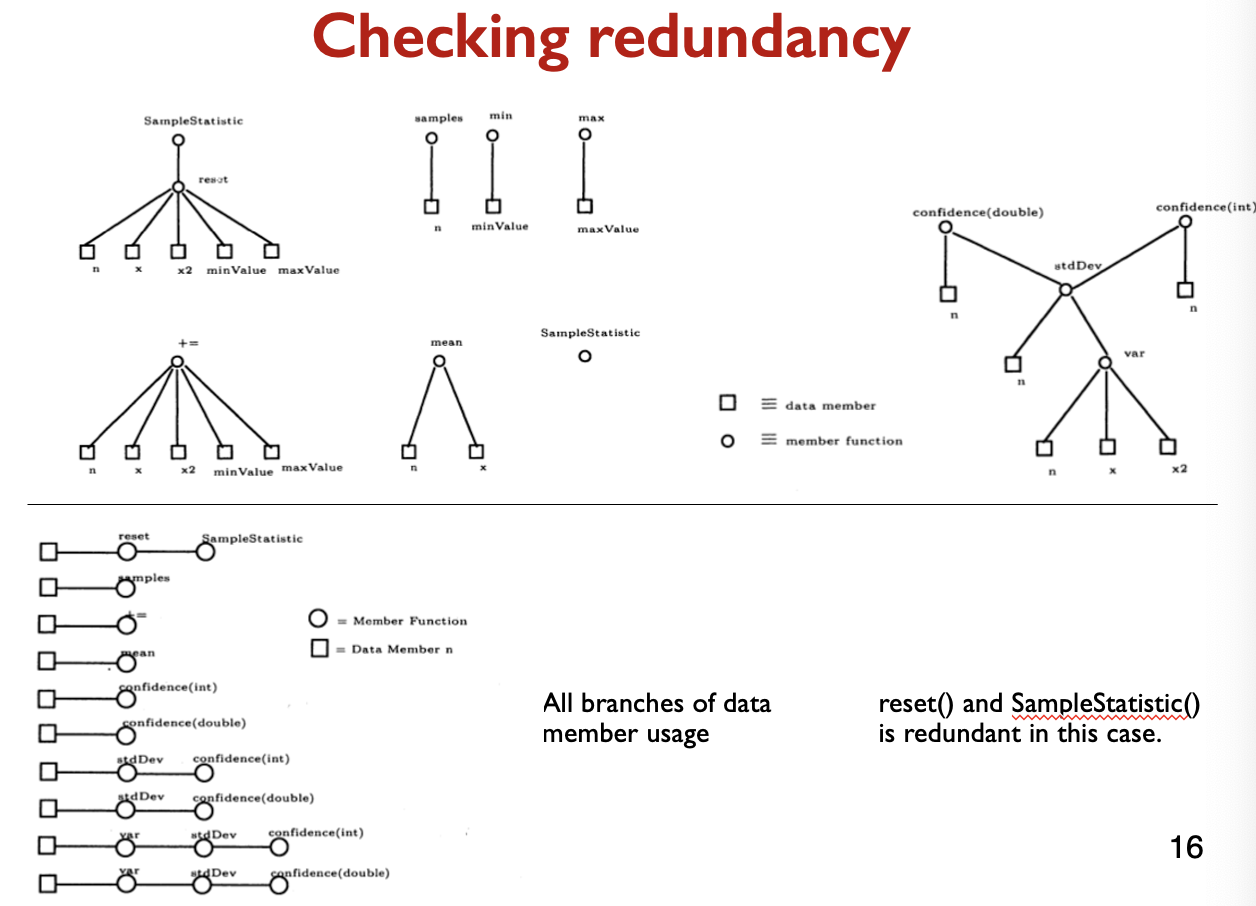
- Can we do it for X and X2?
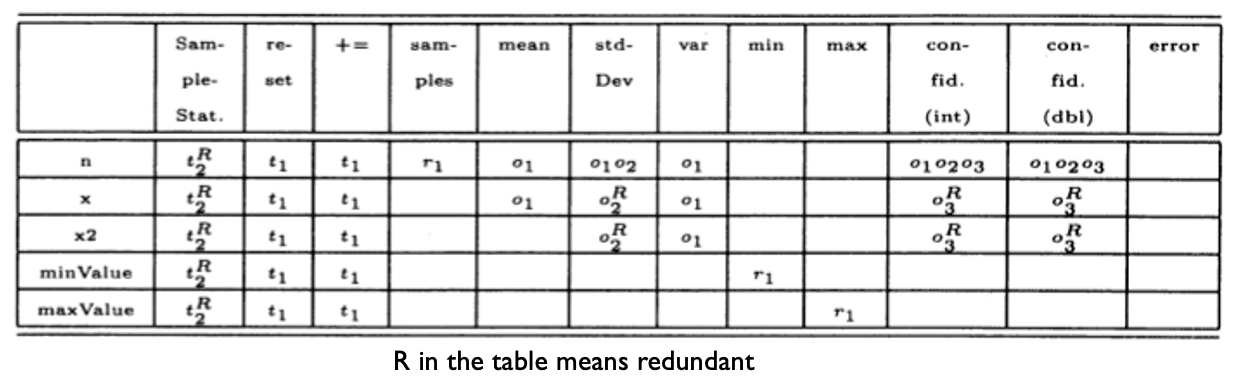
SampleStatistic: MaDUM
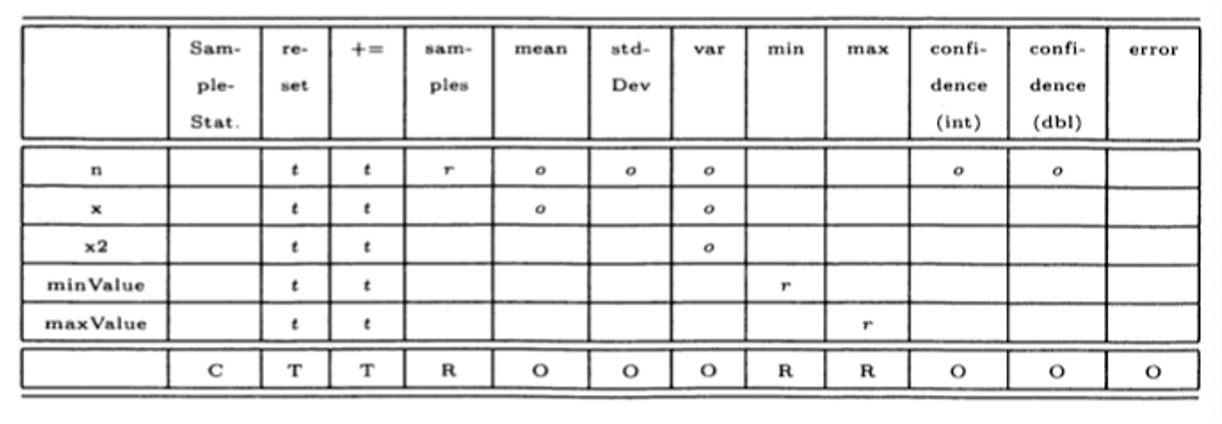
Test Procedure
- Classification of methods is used to decide the test steps to be taken:
-
- Test reporters
-
- Test contructors
-
- Test transformers
-
- Test others
-
- We would like to automate that procedure to the extent possible
Test the Reporters
- First make sure the reporter method does not alter the sate of the data member that it reports on.
- Then, create a random sequence of operations, except for reporters, of the data slice under test and append it with the reporter method.
- SampleStatistic:
samples(),min(),max()need to be tested for n, min-Value and max-Value, respectively.
Test the Constructors
- Constructors initialize data members (there may be several per class)
- Test that:
- All data members are correctly initialized
- All data members are initialized in correct order
- Run the constructor and append the reporter method(s) for each data member
- Verify if in correct initial state (state invariant)
- SampleStatistic: only one simple constructor (only calls
reset()constructor probably does not require testing as long asreset()is tested thoroughly)
Note
As stated earlier, our approach to testing a class is from a single data member’s perspective.
Test the Transformers
- Rationale: test interactions between methods
- For each data slice:
-
- Instantiate object under test with constructor (already tested
-
- Create sequences, e.g., all legal permutations of transformer and other methods in the data slice
- 3)Append the reporter method(s) (already tested)
-
Are permutations sufficient to test interactions between methods?
- For each member function, execute all control flow paths where the data slice is manipulated
Note
No, repeated use of a method could also cause a defect
Test the Others
- They do not fall into the three previous categories
- They do not change the state of the object
- They neither report the state of any data member nor transforms the state in anyway
- They should be tested as any other functions
- Only their functionality as stand-alone entities needs to be checked
- Any standard test technique can be used
Data Slices: Discussion
- Slicing may not be helpful for many classes (e.g., CCoinBox)
- Number of sequences may still be large
- Many sequences may be impossible (illegal)
- Automation? (e.g., oracle, impossible sequences)
- Are we missing many faults by testing slices independently? (e.g., if faults lead to incorrectly defined slices)
- Implicitly aimed at classes with no state-dependent behaviour? (transformers may need to be executed several times to reach certain states and reveal state faults)
Note
States depends on behaviour while sometimes behaviour may depend on states
Testing Derived Classes
- When two classes are related through inheritance, a class is derived from another class
- The derived class may add facilities or modify the ones provided by the base class – it inherits data members and methods of its base class
- Two extreme options for testing a derived class:
- Flatten the derived class and retest all slices of the base class in the new context
- Only test the new/redefined slices of derived class
Bashir and Goel’s Strategy
- Assuming the base class has been adequately tested, what needs to be tested in the derived class?
- Extend the MaDUM of the base class to generate MaDUM_derived
- Take the MaDUM of the base class
- Add a row for each newly defined or re-defined data member of the derived class
- Add a column for each newly defined or re-defined member function of the derived class
Example: SampleHistogram


- MaDUM_derived of SampleHistogram has eight rows, three of them for local data members, and twenty columns, eight for local member functions (two of them re-defined)
- Both
resetand+=are re-defined/overridden in SampleHistogram and invoke their counterpart in SampleStatistics – they therefore indirectly access all the data members of SampleStatistics
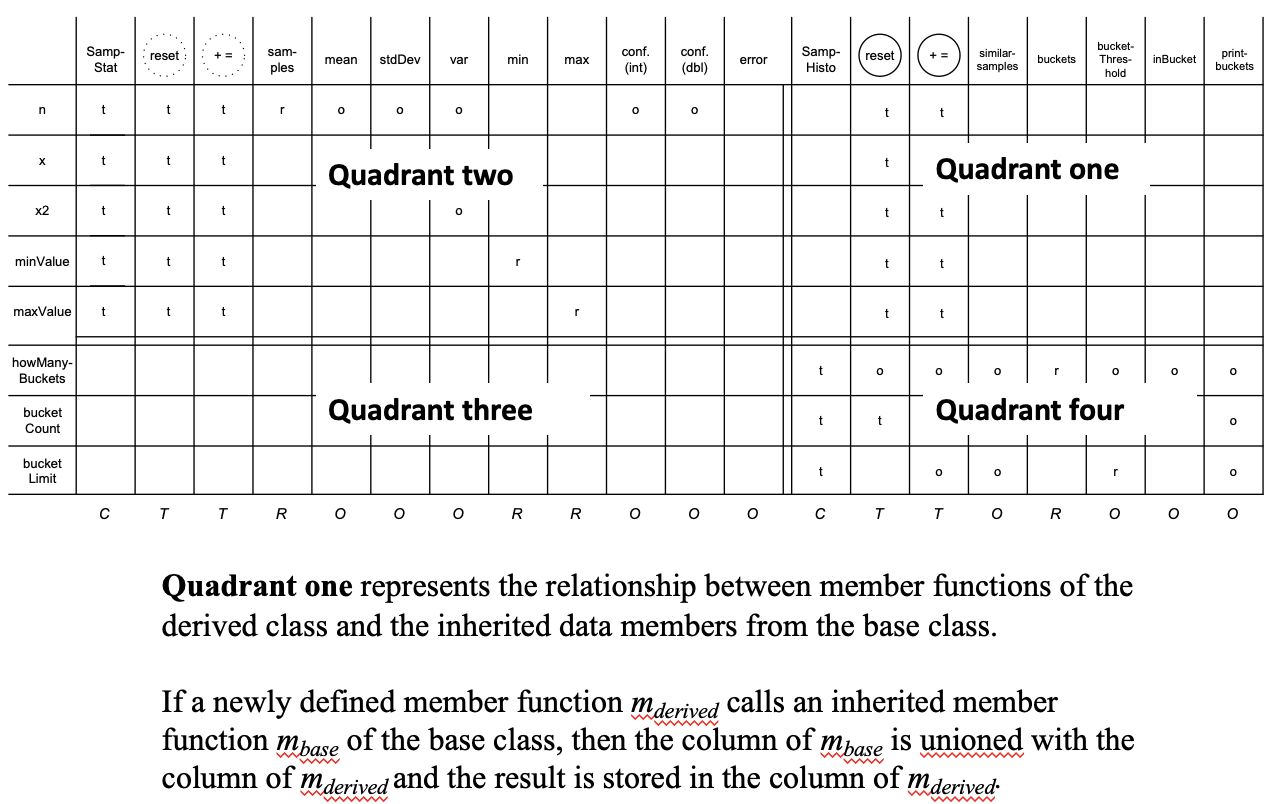


Note
Think about the example of testing inheritance.
Class B has m() call m1()
Class C inherits B, overrides m1. C.m() will call C.m1()

Test Procedure for Derived Class
- Local attributes: similar to base class testing
- Retest inherited attributes (i.e., their data slices):
- •If they are directly or indirectly accessed by a new or re-defined method of the derived class
- Check upper right quadrant (quadrant one) of MaDUM_derived
- We have to ascertain which inherited attributes mandate re-testing à MaDUM_derived can be used for automation
- Once these inherited attributes are identified, the test procedure is similar to slice testing in the base class, but uses inherited and new/redefined methods
- Identify inherited attributes to be re-tested:
- An inherited data member needs to be re-tested if the number of entries in its MaDUM row has increased between MaDUM_base and MaDUM_derived
- For SampleHistogram, the set of inherited data members that needs re-testing includes all inherited data members: {
n,x,x2,minValue,maxValue} becausereset()and+=()affect each inherited data member
Week 6
Fuzzing
Challenge with manual test-case generation
- Manual test case generation can be laborious and difficult
- Takes human time and effort
- Requires understanding the test code
- Can we automate this?
- Automated test case generation
Fuzzing
Set of automated testing techniques that tries to identify abnormal program behaviours by evaluating how the tested program responds to various inputs
A dumb fuzzer
cat /dev/urandom | tested application- Black box. Does not try to reason about the tested program
- Random input and monitor test programs for odd behaviours
- Easy to implement and fast
- Relies on “luck” of random input
- May run same things again and again
- Shallow program exploration
A fuzzer can be categorized as follows
- Generation-based: inputs are generated from scratch
- Mutation-based: by modifying existing inputs
- Dumb or smart depending on whether it is aware of input structure
- White-, grey-, or black-box, depending on whether it is aware of program structure.
Goal
- Find real bugs
- Reduce the number of false positives
- Generate reasonable input
- If we’re expecting a string, passing a file will be rejected before it even makes it to our code
Fuzzing a URL Parser
- A program that accepts a URL
- The URL has to be in a valid format
URL = scheme://netloc/path?query#fragment
- Can we simply generate random inputs to test?
- The chance of getting a valid URL is very low (Years to reach one valid input)
Note
- scheme is the protocol to be used, including http, https, ftp, file…
- netloc is the name of the host to connect to, such as www.google.com
- path is the path on that very host, such as search
- query is a list of key/value pairs, such as q=fuzzing
- fragment is a marker for a location in the retrieved document, such as
#result
Mutation-based Fuzzing
- Taking existing input
- Randomly modify it
- Simple string manipulation (insert, delete a character or flipping a bit)
- Pass it to the program
Examples:
- A set of image files that will be randomly mutated
- A set of logged input that will be randomly modified
- ”Milk, 3,99” “Gilk, 2.99”
Grammar-based Fuzzing
Grammars are among the most popular (and best understood) formalisms to formally specify input languages.
For example: grammar denoting a sequence of two digits:
<start> ::= <digit><digit>
<digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
A simple grammar fuzzer:
- starts with a start symbol (
<start>) then keeps on expanding it. - To avoid expansion to infinite inputs, we place a limit on the number of nonterminals.
- Furthermore, to avoid being stuck in a situation where we cannot reduce the number of symbols any further, we also limit the total number of expansion steps.
Grammar generated inputs can be seeds in mutation-based fuzzing.

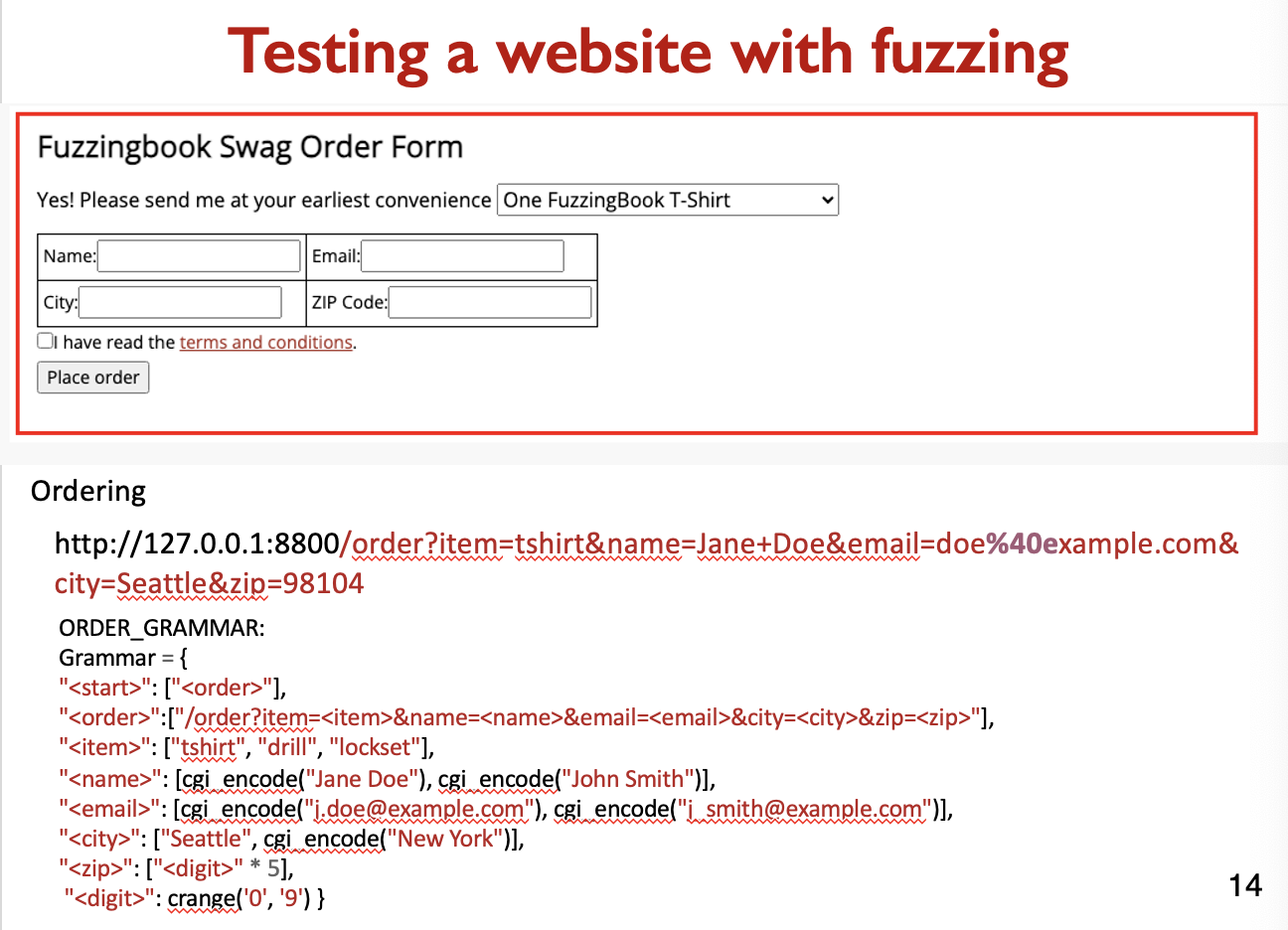
Guiding By Coverage
- Too many test cases and most of them are testing similar behaviour. How do we make sure the fuzzer tests new things?
- Since coverage is frequently measured as well to determine test quality, let us also assume we can retrieve coverage of a test run.
- Evolves input that have been successful!
- In this case, successful means a new path was find during the test execution

Greybox Fuzzing
- The power schedule. A power schedule distributes the precious fuzzing time among the seeds in the population.
- Our objective is to maximize the time spent fuzzing those (most progressive) seeds which lead to higher coverage increase in shorter time.
- We call the likelihood with which a seed is chosen from the population as the seed’s energy.
- For instance, assigns more energy to seeds that are
- shorter
- execute faster
- yielding coverage increases more often
- covering unusual paths
Note
Simply said, we do not want to waste energy fuzzing non-progressive seeds.
Directed Greybox Fuzzing
- We know a spot in the code is more dangerous.
- We can implement a power schedule that assigned more energy to seeds with a low distance to the target function.
- Build a call graph among functions in the program
- For each function executed in the test, calculate its distance (shortest path) to the target function, then do an average distance. Use the distance to calculate the power schedule.
- You can do more complex calculation by considering finer grained information
Search based Fuzzing
- Sometimes we are not only interested in fuzzing as many as possible diverse program inputs, but in deriving specific test inputs that achieve some objective, such as reaching specific statements in a program.
- Applying classic search algorithms like BFS or DFS to search for tests is unrealistic, because these algorithms potentially require us to look at all possible inputs.
- Domain-knowledge can help:
- If we can estimate which of several program inputs is closer to the one we are looking for, then this information can guid us to reach the target quicker

Simple example. Some complex programs, you would have no idea how to achieve this coverage.
- Eight neighbours
- x-1, y-1
- x-1, y
- x-1, y+1
- x, y+1
- x+1, y+1
- x+1, y
- x+1, y-1
- x, y-1
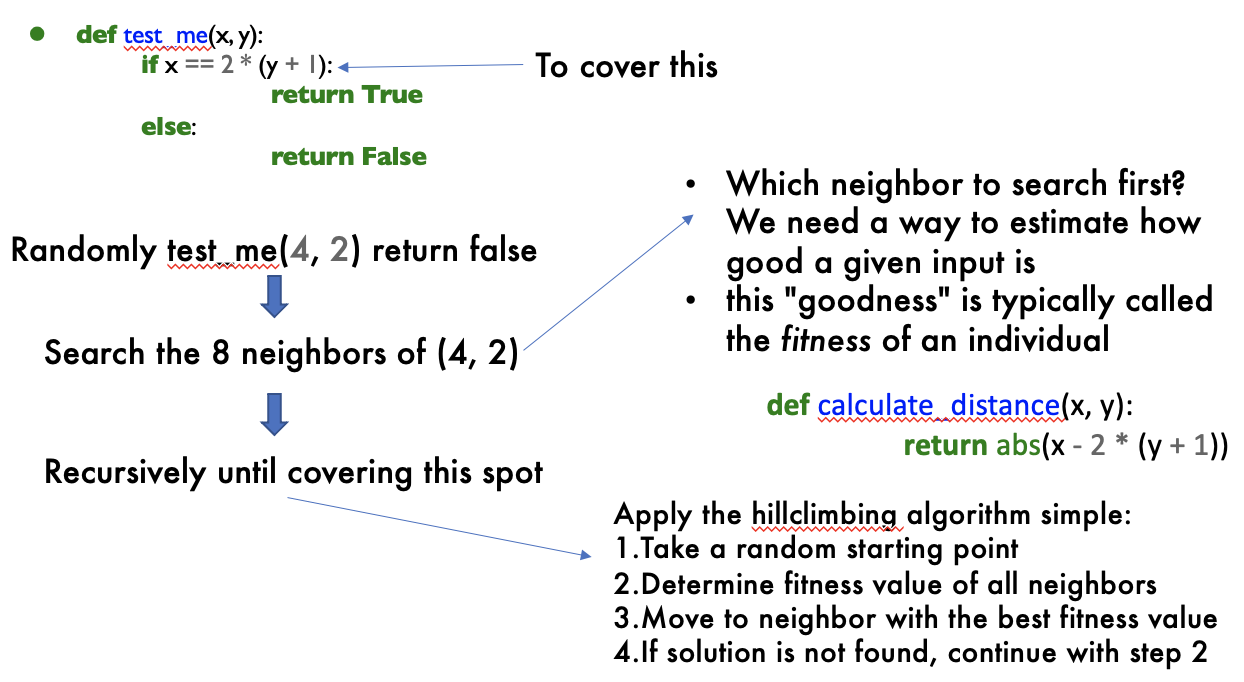
Genetic Algorithm
- A GA is based on the idea that problem solutions can be genetically encoded: A chromosome consists of a sequence of genes, where each gene encodes one trait of the individual.
- Based on a natural selection process that mimics biological evolution.
- A fitness function can take the information contained in this description, and evaluates the properties
- The GA emulates natural evolution with the following process:
- Create an initial population of random chromosomes
- Select fit individuals for reproduction
- Generate new population through reproduction of selected individuals
- Selecting parents
- Creating mutation
- Continue doing so until an optimal solution has been found, or some other limit has been reached.
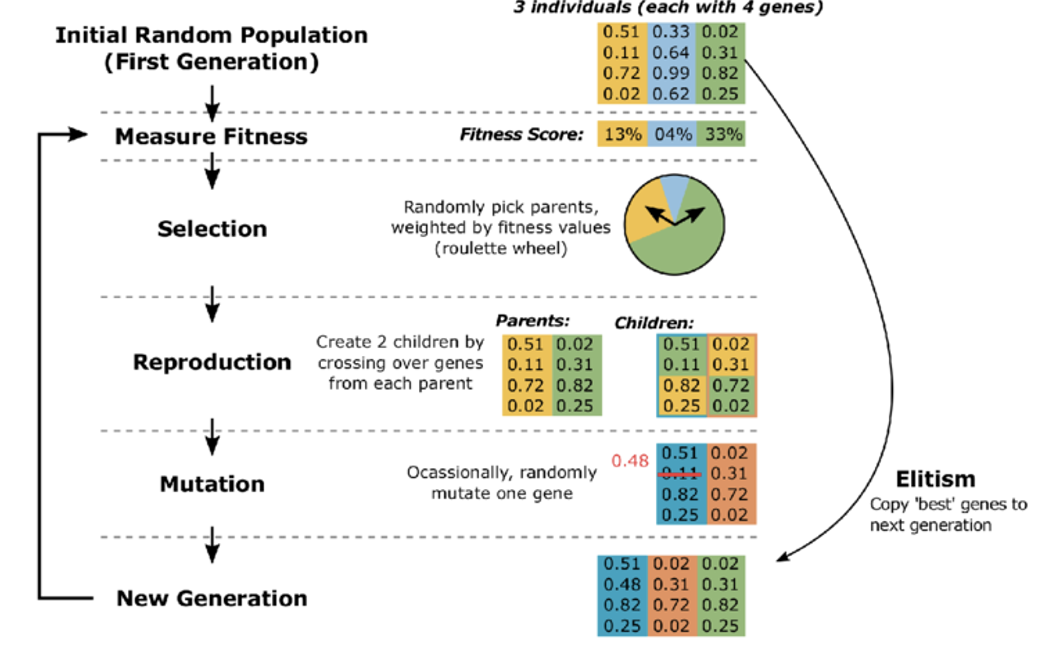
Challenge #1: Feeding in inputs
- libFuzzer — part of the LLVM project, integrated with Clang. Requires fuzz targets — entry points that accept an array of bytes.
// fuzz_target.cc
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
DoSomethingInterestingWithMyAPI(Data, Size);
return 0;
// Values other than 0 and -1 are reserved for future use.
}- The fuzzing engine will execute the fuzz target many times with different inputs in the same process.
- It must tolerate any kind of input (empty, huge, malformed, etc).
- It must not
exit()on any input. - It may use threads but ideally all threads should be joined at the end of the function.
- It must be as deterministic as possible. Non-determinism (e.g. random decisions not based on the input bytes) will make fuzzing inefficient.
- It must be fast. Try avoiding cubic or greater complexity, logging, or excessive memory consumption.
- Ideally, it should not modify any global state.
- Usually, the narrower the target the better. E.g. if your target can parse several data formats, split it into several targets, one per format.
Challenge #2: Detecting abnormal behaviour
What can ‘abnormal’ mean? We need an oracle.
- Crashes
- Triggers a user-provided assertion failure
- ‘Hangs’ — execution takes longer than anticipated
- Allocates too much memory
Early crash detection - use sanitizers:
- Address Sanitizer
- Thread Sanitizer
- Memory Sanitizer
- Undefined Behaviour Sanitizer
- Leak Sanitizer
Challenge #3: Ensuring progress
-
How can we know that fuzzing is exploring more program states over time?
-
Use coverage
-
Evolves test cases that have find a new path through the program execution
-
Greybox, search-based approaches
-
Coverage in AFL: American Fuzzy Lop, Captures branch (edge) coverage by instrumenting compiled programs. Compiler level instrumentation ⇒ fast, Coverage in LibFuzzer, Compiler level, Branches, basic blocks, functions
Challenge #4: Coming up with interesting inputs
- Generate completely random input
- a. Don’t necessarily control the input type
- b. “Milk, 3.99” → 9620
- Understand the input type
- a. “Milk, 3.99” → (is a string) → %&$#”
- Understand the input structure
- a. “Milk, 3.99” → ‘\w+, \d.\d\d’ → “HFSDMEX, 8.43”
- Formal approaches
- a. Model-, Grammar-, Protocol-based fuzz
- b. Useful when problem is well structured
- c. Often impractical for large real world programs
Challenge #5: Speed
What tricks can we use to run a tested program on as many inputs as possible?
- Avoid paying penalty for start-up time of the tested application: start one copy and clone (fork) when initialization is done
- Replace costly-to-acquire resources with cheaper ones, e.g.:
- Use a local database instead of connecting to a remote one
- Capture inessential network traffic (e.g., using WireShark) and replay
- Run many inputs on a single process
- Minimize the number of test corpuses (test cases) and their size.
- When 2 corpuses result in the same coverage, discard the bigger one
- Take an existing corpus and try to remove parts of it such that the coverage remains unchanged
- Parallel, distributed (e.g., oss-fuzz)
Problems
- An overwhelming number of false positives
- False positives are very expensive as they require manual effort
- You put garbage in, what did you expect?
- Focus on code coverage
- Especially the formal method approaches
- Coverage is less important than reasonable inputs
- Cleaning
- Make the random input more reasonable
- Minimization: eliminate redundant test failures through diffing
- Triage: finding similar outputs/stackdumps and grouping them in the same bug report
Fuzz Summary
- Test with reasonable random input
- Goal: find real bugs
- Problem: most failures are false positives that are expensive
- Used in practice
- Google(OSS-Fuzz), Microsoft, Apple, etc use it especially in well specified/controlled environments
- Should you use it?
- At a basic level it’s simple to add
- Example: instead of testing the same int, test a random int in a range
- At a basic level it’s simple to add
- Why generate random input if you have real logged input?
- Use logged input that caused field failures
- Turn this into a test case
Metamorphic Testing
Why?
- Software testing techniques generally assume the availability of a test oracle.
- This may not hold in practice.
- E.g., checking if a path in a non-trivial graph is the shortest
- Translation software
- Compiler
- Software running in production. If there is no crash, how do you know there is an mistake?
- The generation of new test cases is based on the input-output pairs of previous test cases, in particular on the successful ones.
- In other words, we always assume that there are errors inside the software in spite of the apparently correct output produced from the current input.
- We call this approach Metamorphic Testing because new test cases are evolved from the old ones that are normally selected according to some existing selection criteria.
- Giving a program P and test case x, the corresponding output is denoted by P(x).
- Assume x0 is a test case with output P(x0).
- Metamorphic testing is to construct a number of new test cases, x1, x2…xk based on the input-output pair (x0, P(x0)) and the error usually associated with P.
- These new test cases are designed to reveal the errors which go undetected by the test case x0.
Example I: Binary Search on Sorted Array
Consider a program which locates the position of a given key in a sorted array with distinct elements using binary search. The program should return the position of the key if it exists or a value of -1 otherwise.
Let us assume that the input is (x, A[i..j]) and the output is k. Depending on the input-output pair, we have the following cases:
- Case 1: A[k] != x. Obviously there is an error.
- Case 2: k = -1
- Either x does not exist in A, or there is a bug.
- If A is known, this can be verified easily. What if A is a huge database in production and impractical to scan the entire database to confirm?
Testing another randomly selected value from A[p] and verify it with test case (A[p], A[i..k]) would increase the confidence.
- Case 3: A[k] = x. There still may be bugs in the program.
Possibility one:
- Program bug that overwrites the content of A[k] with x. Check A[k-1] < x < A[k+1].
- If correct: Choose y from A[k-1] < y < A[k+1] where y != x
- Test (y,A[i..j]), output should be -1
- This is the newly generated test case by metamorphic testing
Possibility two:
- Rerun the program with
- A[k-1], A [i..j] with expected output k-1
- A[k+1], A [i..j] with expected output k+1
If not feasible to get a y from A[k-1]<y<A[k+1], choose y from A[k-r]<y<A[k+r] , y !=z, z != A[j] where k-r<j<k+r.



todo Don’t know what’s going on…
Example 2: Shortest Path in an Undirected Graph
Given a weighted graph G, a source node X and the destination node y in G. The problem is to output the shortest path and shortest distance.
Assume the output path is x, v1, v2,….vk, y and the distance is p. What are the new test cases?
(y,x,G) expected distance is p (x, vi, G)and (vi, y, G)for any 1⇐i ⇐k, the sum of the two distances = p
Testing Translation Software

Blackbox Testing
What is Black-Box Testing?
- Testing without having an insight into the details of the underlying code
- Based on a system’s specification, as opposed to its structure (does the implementation correctly implement the functionality as per the given system specifications?)
- The notion of coverage can also be applied to functional (black-box) testing
- Rigorous specifications have benefits
- Help functional testing, e.g.:
- categorize inputs
- derive expected output
- In other words, they help test case generation and test oracles
- Advantages of black-box testing
- No need for source code
- Wide applicability, e.g., can be applied for unit testing as well as system-level testing
- Disadvantages of black-box testing
- Does not test hidden functions

Error Guessing
- Ad-hoc approach based on experience
- Approach:
- Make list of possible errors or error-prone situations
- Yields an error model
- Design test cases to cover error model
- Develop and maintain your own error models
Prof's note
Developers tend to make similar mistakes often.
Testers can leverage that by creating error models that focus on common mistakes. (Example on next slide)
Example: Sorting array function
- Error model:
- Empty array
- Already sorted-array
- Reverse-sorted array
- Large unsorted array
- …
- Generate test cases for these situations
Test Case Derivation From Functional Requirements
- Involves clarification and restatement of the requirements such that requirements are testable
- Obtain a point form formulation:
- Enumerate single requirements
- Group related requirements
- For each requirement, provide
- One test case showing requirement functioning
- One test case trying to falsify something (e.g., trying something forbidden)
- Test boundaries and constraints when possible
Example Movie Rental System
1.1 The system shall allow a movie to be rented if at least one of its copies has not been rented.
1.2 At the time of a movie rental, the system shall set the due data of the movie copy to two days from the rental date.
Test situations:
- Attempt to rent an available movie when at least one copy is available (check for correct due date)
- Attempt to rent the last available movie when only one copy is available (check for correct due date)
- Attempt to rent an unavailable movie when no copy is available
1.3 At the time of a movie rental, the system shall make the movie copy unavailable for another rental.
Test situations:
- Attempt to rent the same copy again immediately after it was already rented
- Attempt to rent a different copy of the same movie immediately after another copy of the movie was rented (i.e., initially exactly two copies are available)
1.4 Upon a status request for a movie, the system shall show the current borrowers of all copies of the movie.
Test situations:
- Attempt to display the status of a movie where all copies are currently rented
- Attempt to display the status of a movie where all copies are currently not rented
- Attempt to display the status of a movie which was just returned
Just another example of error guessing…
Test Case Derivation From Use Cases
- For each use case:
- Develop a scenario graph
- Determine all possible scenarios
- Analyze and rank scenarios
- Generate test cases from scenarios to meet coverage goal
- Execute test cases
Scenario Graph
- Generated from a use case
- A node corresponds to a point where we are waiting for the next event (environment event, system reaction) to occur
- There is a single starting node
- End of use case is finish node
- An edge corresponds to an event occurrence (may include conditions, special looping edge)
- Scenario = path from starting node to a finish node


Scenario Ranking
- If too many scenarios to test all
- Ranking may be based on criticality and frequency
- Always include main scenario; should be tested first
- According to coverage goal:
- E.g.: all branches in scenario graph (minimal coverage goal)
- E.g.: all scenarios
- E.g.: n most critical scenarios
- Then, generate test cases

Equivalence Partitioning
- Motivation: we would like to have a sense of complete functional testing and we would hope to avoid redundancy
- Equivalence classes (ECs): partition of the input set according to specification
- Entire input set is covered: completeness (aim for (a))
-
Disjoint classes: avoid redundancy (avoid (b))
![[Screenshot 2024-04-21 at 2.27.17 PM.png]] - A class is expected to behave the same way, be mapped to similar output, test the same thing, reveal the same bugs
- But equivalence classes have to be chosen wisely
- Difficult in practice to find perfect equivalence classes:
- Guessing the likely underlying system behaviour …
- Use of heuristics
Weak / Strong EC Testing
- Once equivalence classes have been determined, test cases need to be generated
- E.g., three input variables of domains: A, B, C
- where
- where
- where
- Weak equivalence class testing (WECT): choose one variable value from each equivalence class
- Strong equivalence class testing (SECT): based on the Cartesian product of the partition subsets (), i.e., test all class interactions
Note
Next slide has an example
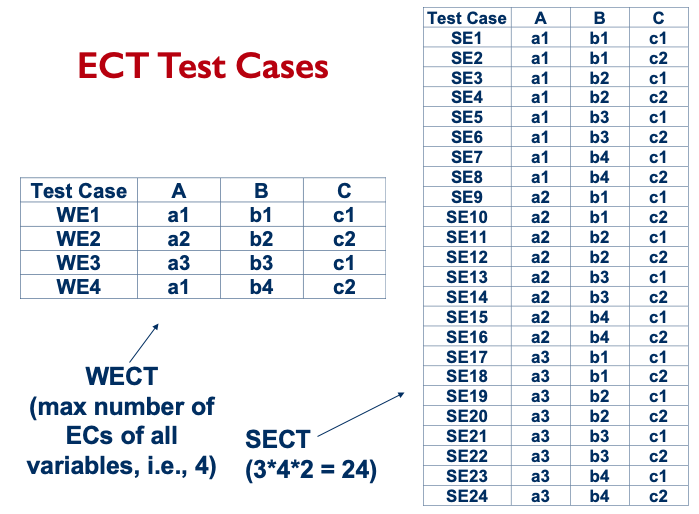
- note that apparently the max number of ECs of all variable is 4 since B has 4 variables. So only 4 WECT???
- For the number of SECT, just multiply the number in the three domains


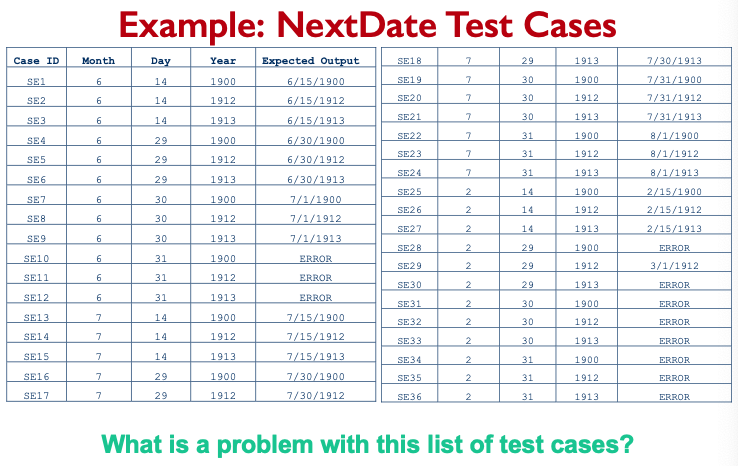
What is a problem with this list of test cases?
- Answer 1: too many errors caused by invalid inputs due to interactions among equivalence classes
- Answer 2: potentially no Feb 28 in the test set
- If we had chosen 5 day classes where D’1 would be 1-27 and D’’1 would be 28, and the other three would stay the same, we would have 45 test cases and a better coverage of the Feb 28 potential problem
- Another possibility might be that we decide that most test cases related to 1900 are not that interesting and 1900 would be merged with other non-leap years. It would bring the test cases to 24.
- Such test cases may be systematically reused/rerun after each modification of the system (maintenance): regression testing. Trying to minimize them is therefore important.
EC: Discussion
- If error conditions are a high priority, we should extend strong equivalence class testing to include both valid () and invalid inputs ()
- Equivalence partitioning is appropriate when input data is defined in terms of ranges and sets of discrete values
- SECT makes the assumption that the variables are independent - dependencies will generate “error” test cases (see category partitioning to address this issue)
- Possibly too many test cases - heuristics …
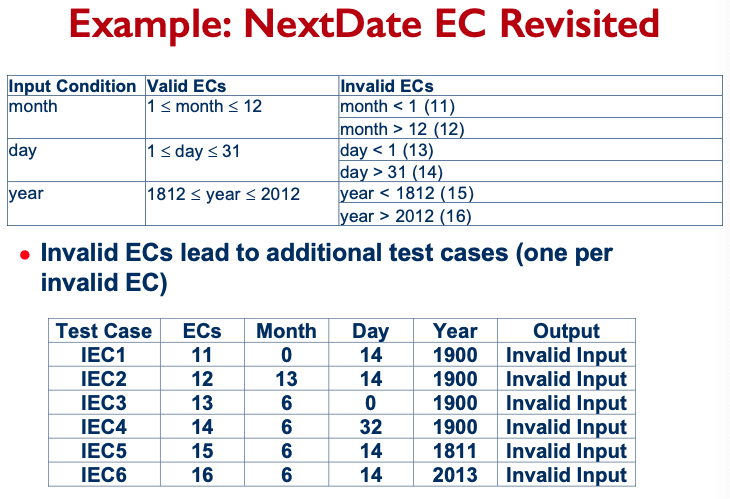
Heuristics for Identifying EC
- For each external input:
- If input is a range of valid values, define:
- One valid EC (within the range) and
- Two invalid EC (one outside each end of the range)
- If input is a number (N) of valid values, define:
- One valid EC and
- Two invalid ECs (none and more than N)
- If input is an element from a set of valid values, define:
- One valid EC (within set) and
- One invalid EC (outside set)
- If input is a “must be” situation (condition), define:
- One valid EC (satisfies condition) and
- One invalid EC (does not satisfy condition)
- If there is a reason to believe that elements in an EC are not handled in an identical manner by the program:
- Subdivide EC into smaller ECs
- Consider creating equivalence partitions that handle the default, empty, bank, null, zero or none conditions
- If input is a range of valid values, define:
Tips for identifying equivalence classes
- For ranges
- 1 valid EC within range
- 2 invalid ECs outside each end of the range
- N with valid values
- 1 valid EC
- 2 invalid ECs (none case, more than N case)
- Set of valid values
- 1 valid EC within set
- 1 invalid EC outside set
- Condition
- 1 valid EC (satisfying the condition)
- 1 invalid EC (does not satisfy)
- Recursive partitioning
- Special cases
Test Selection Approach
- Until all valid ECs have been covered by test cases:
- Write a new test case that covers as many of the uncovered valid ECs as possible
- Until all invalid ECs have been covered by test cases:
- Write a test case that covers one, and only one, of the uncovered invalid ECs (allows tester to observe response to single invalid input)
Prof's note
- Cover valid ECs with a few test cases as possible
- Cover invalid ECs with individual tests (why? Failure to fault diagnosis is much easier)
Equivalence Partitioning
- Advantages:
- Small number of test cases needed
- Probability of uncovering defects with the selected test cases higher than that with a randomly chosen test suite of the same size
- Limitations:
- Strongly typed languages eliminate the need for the consideration of some invalid inputs
- Specification does not always define expected output for invalid test cases
- Test selection approach is not working well when input variables are not independent (so input needs to be independent)
- Brute-force definition of test case for every combination of the inputs ECs provides good coverage, but impractical when number of inputs and associated classes is large
A Summary
Pros:
- Reduces the number of test cases that are needed
- Better than a randomly generated test suite
Cons:
- Strong typing helps already
- Specs may not define behaviour of invalid tests (system crash? Error reported? Log statement printed?)
- Independence assumption
- Impractical for large input spaces and classes with many dependencies
Boundary Value Analysis
- We have partitioned input domains into suitable classes, on the assumption that the behaviour of the program is “similar”
- Some typical programming errors tend to occur near extreme values (boundaries between different classes)
- This is what boundary value testing focuses on (on the edge of the planned operational limits of the software)
- Simpler but complementary to previous techniques
- While equivalence partitioning selects tests from within equivalence classes, boundary value analysis (BVA) focuses on tests at and near the boundaries of equivalence classes
Prof's note
- So far, we’ve identified ECs, but have treated all values as the same
- Programming errors tend to cluster near EC boundaries
- To deal with this, boundary value testing focuses on tests at and near boundaries of ECs
- Data types with boundary conditions:
- Numeric, character, position, quantity, speed, location, size, …
- Boundary condition characteristics:
- First/last, start/finish
- Min/max, under/over, lowest/highest
- Slowest/fastest, smallest/largest, shortest/longest
- Next-to/farthest-from
- Soonest/latest
Example: findPrice()
- Visualization on next slide
- Point out boundaries and points near boundaries

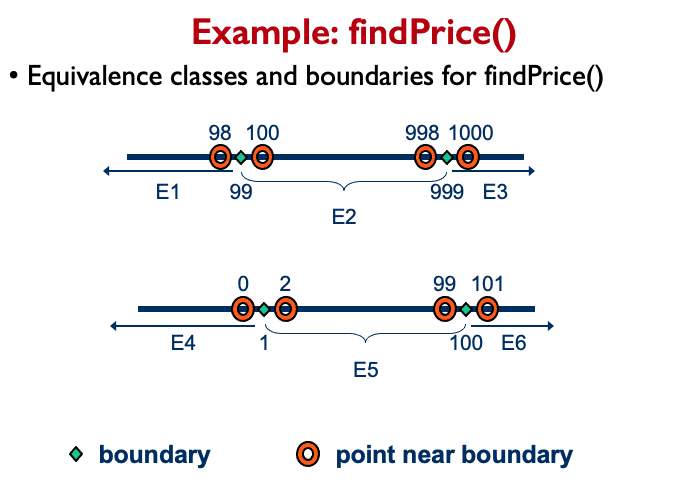
BVA: Guidelines
- Use input variables value (within a class) at their minimum, just above the minimum, a nominal value, just below their maximum, and at their maximum
- Convention: min, min+, nom, max-, max
- Hold the values of all but one variable at their nominal values, letting one variable assume its extreme values
- For each boundary condition: (emphasize this last bullet point)
- Include boundary value in at least one valid test case
- Ensure that each boundary condition is covered in at least one valid test case.
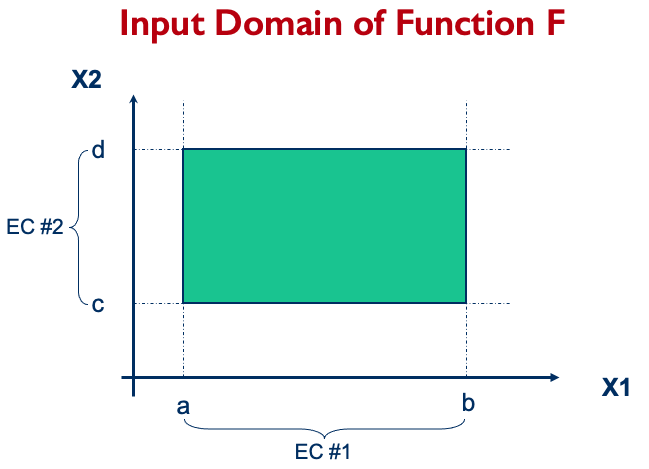
- Let’s visualize a 2-variable testing problem
- You end up with a rectangular space of valid inputs (Continued on the next slide)
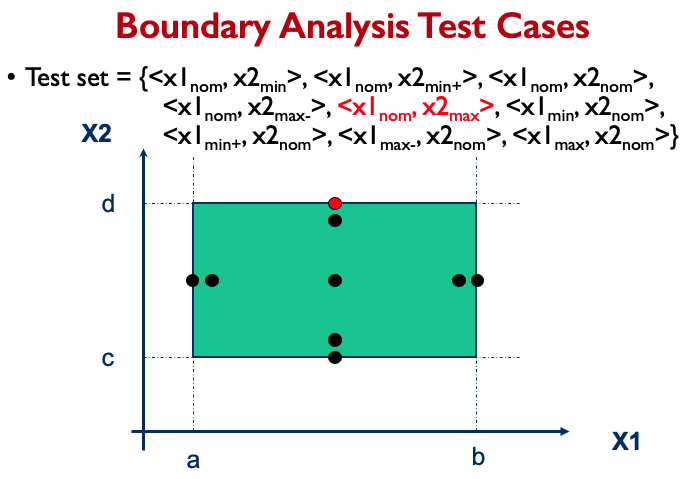
- Using BVA, we will select tests like this. The read font indicates the red dot, not meaning there is anything wrong with it.
General Case and Limitations
- A function with n variables will require 4n+1 test cases
- Works well with variables that represent bounded physical quantities
- No consideration of the nature of the function and the meaning of variables
- Rudimentary technique that is amenable to robustness testing (requires 6n+1 test cases)
- For each boundary condition:
- Additionally include value just beyond boundary in at least one invalid test case (min-, max+)
Prof's note
More broadly, with more variables, we will require plenty of tests (read point 1)
Ignores meaning of variables (point 3)
Robustness testing, which includes tests just beyond the valid hyperplane (next slide)
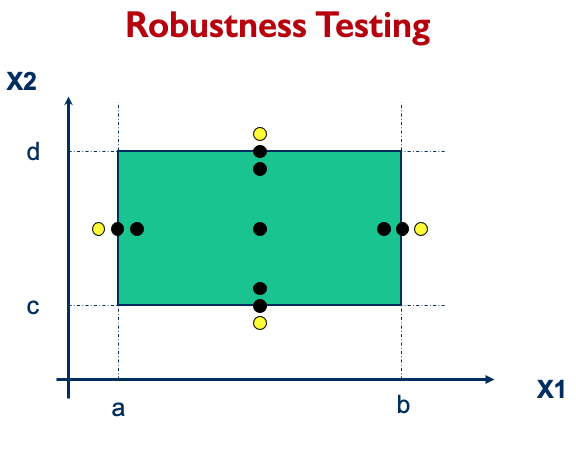
- Yellow circles are robustness tests
Worst Case Testing
- Boundary value analysis makes the common assumption that failures, most of the time, originate from one fault related to an extreme value
- What happens when more than one variable has an extreme value?
- Idea comes from electronics in circuit analysis
- Cartesian product of {min, min+, nom, max-, max}
- Clearly more thorough than boundary value analysis, but much more effort: test cases
- Good strategy when physical variables have numerous interactions, and where failure is costly
Note
Try all combinations of sketchy vlaues Visualization on the next slide
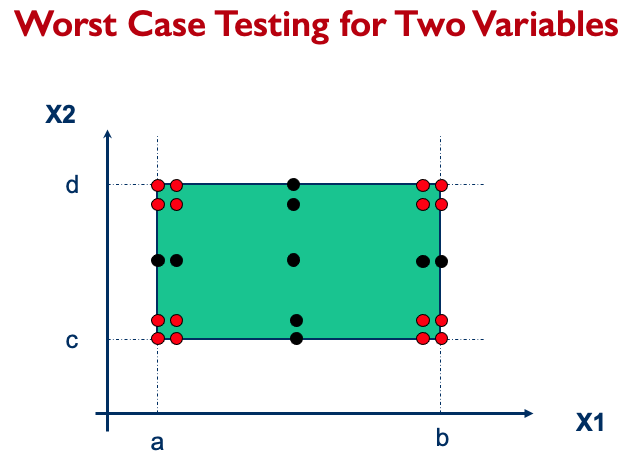
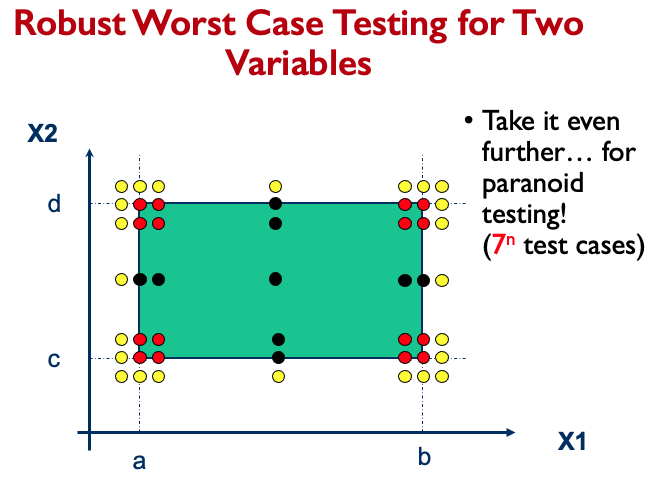
- Can inject robustness tests for worst case
Category Partitioning
- Systematic, specification-based methodology that uses an informal functional specification to produce a formal test specification
- Integrates equivalence class testing, boundary value analysis, and adds a few refinements (i.e., constraints between classes)
- Consists of:
- Identification of categories
- Partitioning each category into choices
- Creating test frames as selection of choices
- Creating test cases (i.e., test frames with concrete test data)
Steps:
- Decompose the functional specification into functional units that can be independently tested
- Examine each functional unit
- Identify parameters (i.e., explicit input to the functional unit)
- Identify environmental conditions (i.e., characteristics of the system’s state)
- Find categories for each parameter & environmental condition (i.e., major property or characteristic of a parameter / condition)
- E.g.: array size, browsers, operating systems
- Subdivide categories further into choices in the same way as equivalence partitioning is applied (value sub-domains)
- E.g.: array size (100, 0, 1)
- browsers (IE, Firefox, Safari, Chrome)
- Operating systems (Windows, Linux, MAC OS, iOS, Android)
- Determine constraints among the choices (i.e., how the choices interact, how the occurrence of one choice can affect the existence of another, and what special restrictions might affect any choice)
- E.g.: OS must be Windows if browser is IE
- Create test frames (i.e., a set of choices, one from each category but only according to the allowable combinations of choices)
- Test specifications
- Create test cases (test frame with specific values for each of the choices)
Prof's note
- Break spec down into units that can be tested INDEPENDENTLY
- For each functional uni:
- Spot the parameters (explicit inputs)
- Identify environmental dependencies (implicit inputs). Could be:
- Global variable settings
- Configuration file settings
- Data file/database values
- Sensor data values
- …?
- Break categories up into choices using equivalence partitioning
- Spot interactions among choices - how choices influence each other
- Create test frames based on valid choices and their interactions, produces test specs
- Test cases are instances of test frames with actual values
Example on next slides

Prof's note
<Flip back to slide 44 and explain that step 1 is ok, no need to break down further>
What are the parameters?
- Pattern
- File
What are the categories?
- Pattern size
- Embedded quotes
- Quoting
- Embedded blanks
- File name
Next slide has answers

Prof's note
<after reading this off, ask question below>
What are the environmental conditions?
- Number of occurrences of pattern in file
- Pattern occurrences on the target line

Note
Next, we will need to define the test frame

- Are there conflicts?

- Example on next slide

Prof's note
By adding explicit constraints and properties, we can have them reviewed or discussed by other team members

Note
Note that adding theses constraints reduces the number of required test frames to 678

- Example on next slides will clarify


Note
You can try to list these 40 test frames as an exercise!
Criteria For Using Choices
- All combinations (AC): this is what was shown in the previous exercise, what is typically done when using category partitioning; one value for every choice of every parameter must be used with one value of every (possible) choice of every other category
- Number of test cases:
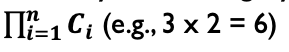
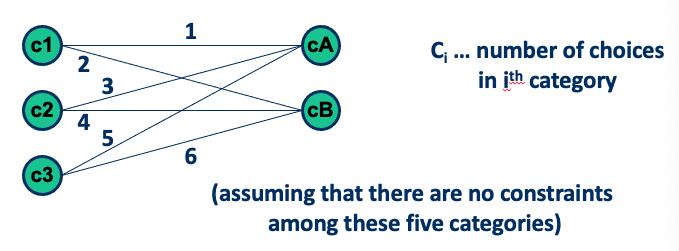
Note
AC type for using choices: (Pretty straightforward)
- Each choice (EC): this is a weaker criterion; one value from each choice for each category must be used at least in one test case
- Number of test cases:
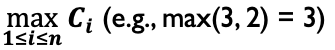
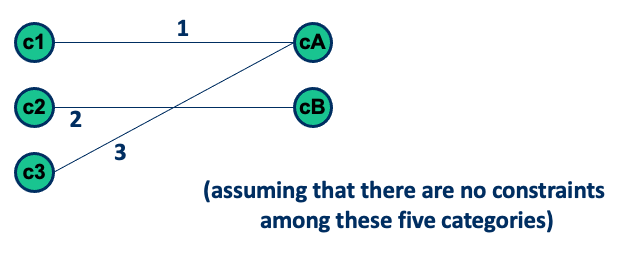
- Base choice (BC): this criterion is a compromise; a base choice is chosen for each category, and a first base test is formed by using the base choice for each category
- Subsequent tests are chosen by holding all but one base choice constant (i.e., we select non-base choices for one category) and forming choice combinations by covering all non-base choices of the selected category
- This procedure is repeated for each category
- Number of test cases: (e.g., 3 + 2 – 2 + 1 = 4)
- The base choice can be the simplest, smallest, first in some ordering, or the most likely from an end-user point of view
- E.g., in a String Search example: a character c occurs in the middle of the string, length x is within 2-19
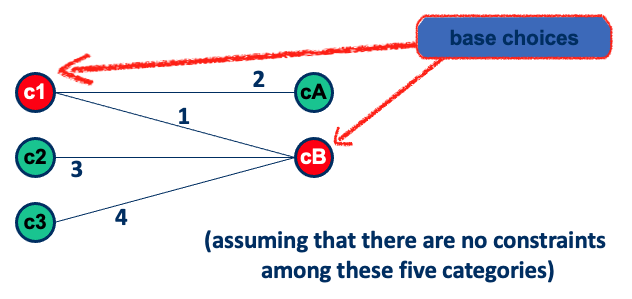

-
important???
-
All combinations, each choice, and base choice are general criteria for reducing the number of combinations that need to be considered for test cases
-
They are not only applicable to category partitioning
Where have we already seen one of these criteria in action?
Prof's note
WECT: each choice SECT: all combinations Boundary Value Analysis: base choice (several variables - keep all but one variable at their nominal values)
Category Partitioning - Summary
- Identifying parameters, environmental conditions, and categories is heavily relying on the experience of the tester
- Makes testing decisions explicit (e.g., constraints), open for review
- Combine boundary value analysis, robustness testing, and equivalence class partitioning
- Once the constraints have been identified, the technique is straightforward and can be automated
- The technique for test case reduction makes it useful for practical testing
Decision Tables
- A precise yet compact way to model complicated logic
- Associate conditions with actions to perform
- Can associate many independent conditions with several actions in an elegant way
https://en.wikipedia.org/wiki/Decision_table
Decision Table - Format

Decision Table Terminology
-
Condition entries restricted to binary values
- We have limited entry table
-
Condition entries have more than two values
- We have extended entry table
-
”don’t care” values in decision tables help reduce the number of variants
-
”don’t care” can correspond to several cases:
- The inputs are necessary but have no effect
- The inputs may be omitted
- Mutually exclusive cases (type-safe exclusions)
-
Do not confuse a “don’t care” condition with a “don’t know” condition
- Reflects an incomplete model
- Most of the time, this indicates specification bugs
- Tests are needed to exercise these undefined cases

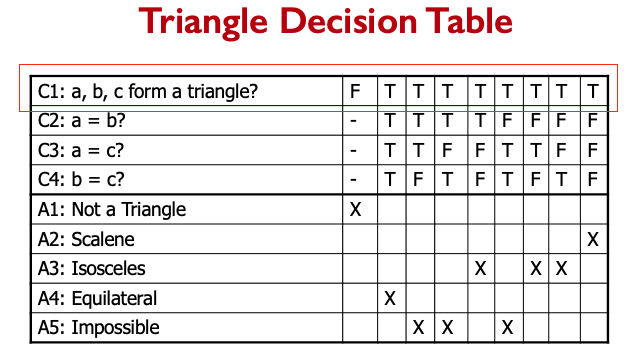
- The choice of conditions can greatly expand the size of a decision table.
- Need to have a more detailed view of the three inequalities of the triangle property (c1).
- If any of the three fails,
<a,b,c>won’t constitute sides of a triangle
- If any of the three fails,
Note
Firs rule, if it’s not a triangle, then we don’t care the others, hence we don’t care the conditions for c2, c3, c4
Explain the cases why a = b, b = c, it has to be a = c; it is impossible to get a != c.
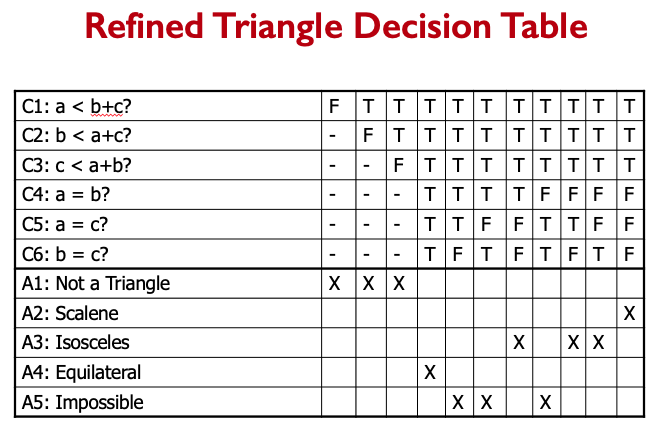
- Can be expanded further, as there can be two possibilities of a < b + c fail either a = b + c or a > b + c
How to use decision table in software testing?
- Condition entries in a decision table are interpreted by a computer program as
- input
- equivalence classes of input
- Action entries in a decision table are interpreted as
- output
- major functional processing portions
- The rules are then interpreted as test cases.
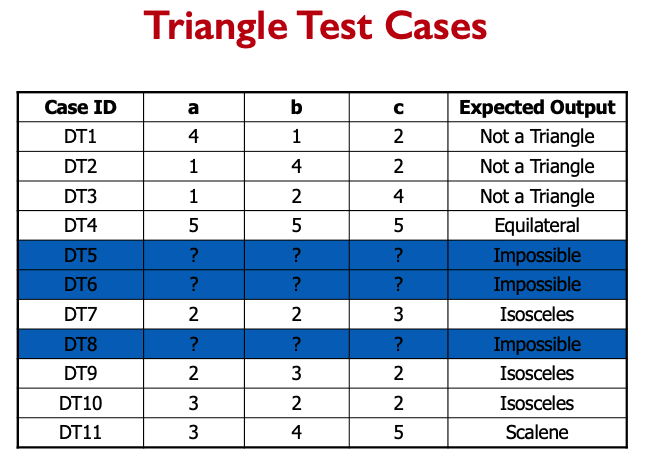
Note
Since the previous DT has 11 columns, that translates to 11 test cases.
Go back and explain why DT5, DT6 and DT8 are impossible to get the concrete values
Don’t care entries and rule counts
- Limited entry tables with N conditions have rules
- Don’t care entries reduce the number of explicit rules by implying the existence of non-explicitly stated rules
- Each don’t care entry in a rule doubles the count for the rule
- For each rule determine the corresponding rule count
- Total the rule counts
Note
Limited entry tables boolean
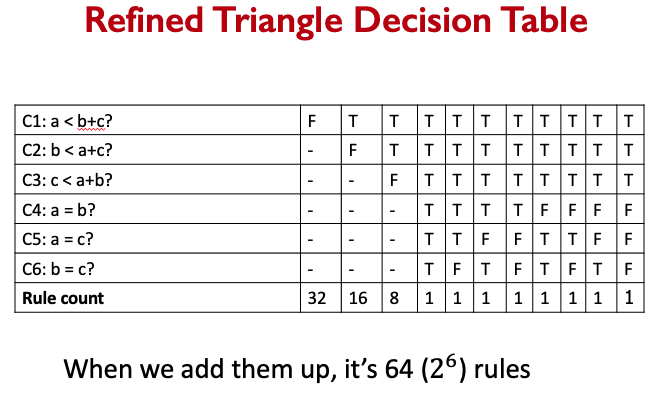
Count the rules in a decision table
- Less rules than combination rule count
- Indicates missing rules
- More rules than combination rule count
- Could indicate redundant rules
- Could indicate inconsistent table
Note
Redundant rules table 7.9 page 107 Jorgenson book

Which rule(s) is redundant?
Prof's note
We have total . This is bigger than
Rule 9 is identical to rule 4.
As long as the actions in a redundant rule are identical to the corresponding part of the decision table, we do not have much of a problem. Otherwise, we have a bigger problem.
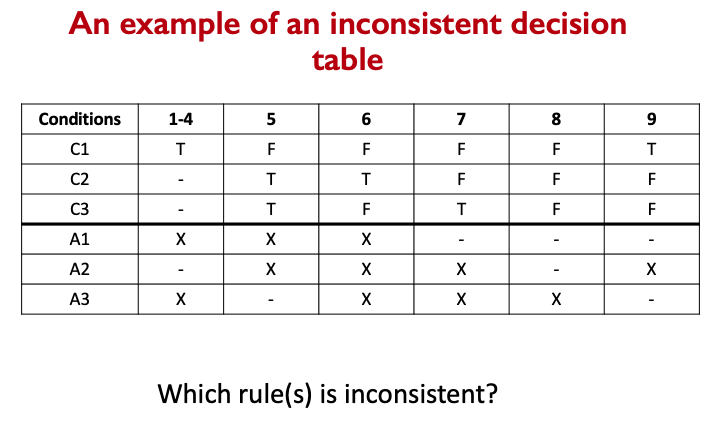
Which rule(s) is inconsistent?
Prof's note
We have in total , which is bigger than
Rules 4 and 9 are inconsistent action sets are different.
The decision table is nondeterministic, since there is no way to decision when to apply rule 4 or rule 9.
EXAMPLE: NEXTDATE DTtodo
Decision Table Applicability
- The specification is given or can be converted to a decision table .
- The order in which the predicates are evaluated does not affect the interpretation of the rules or resulting action.
- The order of the rule evaluation has no effect on the resulting action .
- Once a rule is satisfied and the action selected, no other rule need be examined.
- The order of executing actions in a satisfied rule is of no consequence.
- In reality, the restrictions do not eliminate many potential applications.
- In most applications, the order in which the predicates are evaluated is immaterial.
- Some specific ordering may be more efficient than some other but in general the ordering is not inherent in the program’s logic.
Decision Tables - Issues
- Before deriving test cases, ensure that
- The rules are complete
- Every combination of predicate truth values is explicit in the decision table
- The rules are complete
- The rules are consistent
- Every combination of predicate truth values results in only one action or set of actions
Guidelines and Observations
- Decision Table testing is most appropriate for programs where
- There is a lot of decision making
- There are important logical relationships among input variables
- There are calculations involving subsets of input variables
- There are cause and effect relationships between input and output
- There is complex computation logic
- Decision tables do not scale up very well
- May need to
- Use extended entry decision tables
- Algebraically simplify tables
- May need to
- Decision tables can be iteratively refined
- The first attempt may be far from satisfactory
- Look for redundant rules
- More rules than combination count of conditions
- Actions are the same
- Too many test cases
- Look for inconsistent rules
- More rules than combination count of conditions
- Actions are different for the same conditions
- Look for missing rules
- Incomplete table
Note
To simplify rules
(not A) and (not B) ó not (A or B) (not A) or (not B) ó not (A and B)
Week 8
Test Driven Development (TDD)
Working replit: https://replit.com/join/lanlzewvte-swy351041603
TDD algorithm
- Write a failing test case
- Get it to compile
- Make it pass
- Remove duplication (i.e. Refactor)
- Repeat
Reflection on TDD
- Looking at the requirements first
- Full control over the pace of writing production code
- Quick feedback
- Testable code
- Feedback about design
To TDD or not to TDD
- I can get the same benefits without doing TDD. I can think more about my requirements, force myself to only implement what is needed, and consider the testability of my class from the beginning. I do not need to write tests for that!
- TDD gives you the rhythm to follow
- Reminder of reviewing code often
- Forces you to use the code developed from the beginning
- If you write the tests after the code, and not before, as in TDD, the challenge is making sure the time between writing code and testing is small enough to provide developers with timely feedback. Don’t write code for an entire day and then start testing—that may be too late.
- I use TDD when I don’t have a clear idea of how to design, architect, or implement a specific requirement.
- I use TDD when dealing with a complex problem or a problem I lack the expertise to solve.
- I do not use TDD when there is nothing to be learned in the process. If I already know the problem and how to best solve it, I am comfortable coding the solution directly.
Problems with TDD
- It distracts from writing the code
- You must always think negatively about getting the code to fail
- It takes a lot of discipline to write the test first
- You write a lot of simple, useless tests
- You have to maintain all these tests
- Often involves re-writing the tests as the system evolves
- Your architecture is designed around making it easier to test
- You need lots of mock objects to decouple yourself from the DB and UI
- Maintenance tests are not the same as development tests
- Sometimes it’s best to consolidate your unit tests and remove tests that are low value
A compromise
- Ensure that every commit has a test associated with it
- This means you don’t need to write the test first
- But you do need to write it before you add it to the git repo
- If you don’t add it at commit, you will never add it because writing tests isn’t fun
TDD Legacy Code Algorithm
- Get the class you want to change under test
- Write a failing test case.
- Get it to compile
- Make it pass (Try not to change existing code as you do this.)
- Remove duplication
- Repeat
TDD and Legacy Code
- One of the most valuable things about TDD is that it lets us concentrate on one thing at a time.
- We are either writing code or refactoring; we are never doing both at once.
- That separation is particularly valuable in legacy code because it lets us write new code independently of old code.
- After we have written some new code, we can refactor to remove any duplication between it and the old code.
Test Minimization, Selection and Prioritization
Read the notes on my IPAD
Most tests don’t fail
- Of 850k test executions at Google 0.29%
- Of 120M test executions on Firefox 1.6% fil
- Of 4.4M test executions on Chrome 13% tests failed Executing all tests wastes resources. Not all tests are equal. Test suite minimization, test case selection and test case prioritization.
Test suite minimization
- Given: A test suite, T, a set of test requirements , that must be satisfied to provide the desired ‘adequate’ testing of the program, and subsets of , one associated with each of the ‘s such that any one of the test cases belonging to can be used to achieve requirement .
- Problem: Find a representative set of test cases that will satisfy all of the ‘s

- A NP-Hard problem
Test case minimization heuristics
- If a test requirement can be satisfied by one and only one test case, the test case is an essential test case.
- If a test case satisfies only a subset of the test requirements satisfied by another test case, it is a redundant test case.
- GE heuristic: first select all essential test cases in the test suite; for the remaining test requirements, use the additional greedy algorithm, i.e. select the test case that satisfies the maximum number of unsatisfied test requirements.
- GRE heuristic: first remove all redundant test cases in the test suite, which may make some test cases essential; then perform the GE heuristic on the reduced test suite.

https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=131378






Test case selection
- While test case selection techniques also seek to reduce the size of a test suite, the majority of selection techniques are modification-aware. That is, the selection is not only temporary (i.e. specific to the current version of the program), but also focused on the identification of the modified parts of the program.
- Test cases are selected because they are relevant to the changed parts of the SUT, which typically involves a white-box static analysis of the program code.
REGRESSION TESTING
What is regression testing?
Given a program P, its modified version of P’, and the test set T used previously to test , find a way, making use of T, to gain sufficient confidence in the correctness of P’.
regression testing aims to ensure the correctness of a modified version of a program (P′) compared to its original version (P). It leverages the previously used test set (T) to gain confidence in the correctness of the modified version.
https://dl.acm.org/doi/pdf/10.5555/257734.257767
Regression Testing Steps
- Identify the modification that were made to P.
- Select , the set of tests to re-execute on P’.
- This step may make use of the results of step 1.
- Retest P’ with T’, establishing P”s correctness with respect to T’.
- If necessary, create new tests for P’.
- Create a new complete test set for P’, including the tests from step 2 and 4, and old tests that are not selected, provided they remain valid.
Step 2 addresses the tests selection problem.
Test case selection: what to select
- To reduce the time involved in re-testing, we want to choose only tests from T that will produce different output when run on P’.
- We call these tests “modification-revealing”.
A test Ti ∈ T is modification-revealing if it produces different outputs in P and P’.
Test case selection: modification-traversing
- We cannot decide if a test is modification-revealing.
- But we can identify all the necessary condition for a test to be modification-revealing.
- In order for a test to produce different output in P and P’, it must execute some code modified from P to P’
- We define tests that execute modified code as “modification-traversing”.
- A test Ti ∈ T is modification-traversing if it executes a new or modified statement in P’, or misses a statement in P’ that is executed in P.
- Modification-revealing tests are necessarily modification-traversing, not the other way around.
Test case selection: evaluation criteria
- Inclusiveness
- Suppose T contains n modification-revealing tests and S selects of those tests. The inclusiveness of S is calculated as .
- For example, if T contains 50 tests, 8 of which are modification-revealing and S selects only 2 of the 8. S is 25% inclusive.
- If a method S always selects all modification-revealing tests, we call S safe.
- Precision
- Measure the extent to which a selective strategy omits tests that are non-modification-revealing.
- Suppose T contains non-modification-revealing tests and S omits of these tests. The precision of S is .
- For example, if T contains 50 tests, 44 of which are non-modification-revealing and S omits 33 of these 44. S is 75% precise.
Test case selection: what about fault-revealing
- It is possible to identify the fault-revealing test cases for P′ by finding the modification-revealing test cases for P and P ′, given the following two assumptions:
- P -Correct-for-T Assumption : It is assumed that, for each test case t ∈ T , when P was tested with t, P halted and produced the correct output.
- Obsolete-Test-Identification Assumption: It is assumed that there exists an effective procedure for determining, for each test case t ∈ T , whether t is obsolete for P ′ . From these assumptions, it is clear that every test case in T terminates and produces correct output for P , and is also supposed to produce the same output for P ′ . Therefore, a modification-revealing test case t must be also fault-revealing.
- A weaker criterion: use modification-traversing
A third assumption:
Controlled-Regression-Testing Assumption :
When P ′ is tested with t, all factors that might influence the output of P ′ , except for the code in P ′ , are kept constant with respect to their states when P was tested with t.
Given that the Controlled-Regression-Testing assumption holds, a non-obsolete test case t can thereby be modification-revealing only if it is also modification-traversing for P and P′.
If the P -Correct-for-T assumption and the Obsolete-Test-Identification assumption hold along with the Controlled-Regression-Testing assumption, then the following relation also holds:
Test case selection based on data flow
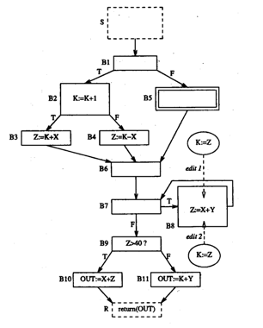
- Use of Z
- B3 to B8
- B4 to B8
- Define of K
- B8 to B11
- Does the define of K stops any du path between B2 and B11?
- No.
Test case selection based on code

Test case selection based on slicing

- Triangles that are equilateral or right will not be affected
Not every statement that is executed under a test case has an effect on the program output of the test case. (Think about RIP)
-
Slicing:
- A program slice consists of all statements, including conditions in the program, that might affect the value of variable V and point P.
-
Backward slices S(v, n): refer to statement fragments that contribute to the value of v at statement n
- Statement n is a Use node of variable v, Use (v, n)
Backward slicing example
It is easy to see that the line
r = x; cannot affect the final value of z. And this is why it is not included in the slice. Slightly less obvious is That the assignment z = y-2; also has no effect upon the final value of z, And so it too is not included in the slice. This is because, although this statement Updates the value of z in the middle of the program, the value assigned Is overridden by the last line, thereby losing the effect of the first assignment.
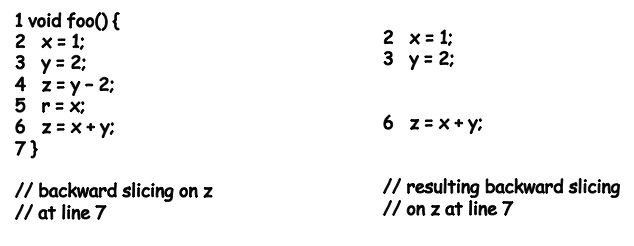
Backward slicing example (2)
The program is intend to compute the sum and product of numbers from 1 to n (some input). Sum is stored in s and product is stored in p Computation on s is correct, but not correct in p Since s is correct, hence we only slice on p
The resulting slice is much simpler to look at than the original program and yet it still contains all the statements which could possibly affect the final (and incorrect) value of the variable p. Examining the slice will allow us to find the bug faster than examining the original. In this case, the bug lines in line 3, it should be p =1 instead.


- Forward slices S(v, n): refer to all the program statements that are affected by the value of v and statement n
- Refers to the predicate uses and computation uses of the variable v
Forward slicing example
See how forward slicing works in the simple program. Suppose the first line of the program needs altering. As this line assigns a value to the variable x, any subsequent part of the program which ultimately depends upon the value of x may behave differently after the modification.
It contains the lines of the program which are affected by a change to the first line. Notice that the line r++; has to be included in the forward slice, as its execution is controlled by the predicate
p==0which is affected by the slicing criterion.
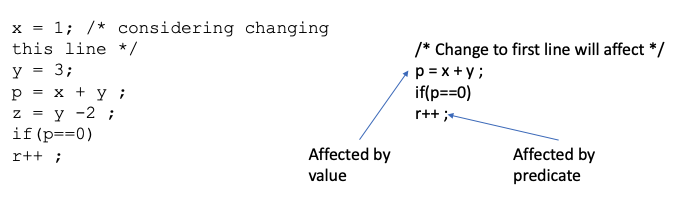


Dynamic Slicing
Static slicing can be used to assist debugging by simplifying the program. However, the slices constructed by slicing can be very large.
Dynamic Slice
A dynamic slice is constructed with respect to the traditional static slicing criterion together with dynamic information (the input sequence supplied to the program, during some specific execution). Three piece of information (dynamic slicing criterion)
- Variables to be sliced (same as static slicing)
- The point of interest within the program (same as static slicing)
- Sequence of input values for which the program was executed
- A dynamic slice for a variable at statement n, on an input I
Dynamic slicing example
Dynamic slicing for p at line 9 for input
<0>is much much simpler and can highlight the bug in the original program. In practice, it can be more complicated.
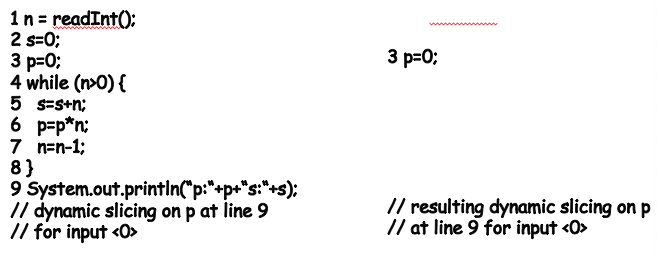
Slicing Precision
-
There are two main properties desirable in slicing algorithms, which we call soundness and completeness.
-
In order to be sound an algorithm must never delete a statement from the original program which could have an effect upon the slicing criterion. It is this property that allows us to analyse a slice in total confidence that it contains all the statements relevant to the criterion.
-
Soundness on its own, however, is not enough: a trivial slicing algorithm could refuse to delete any statements from a program, thereby achieving soundness by doing nothing.
-
In order to be complete a slicing algorithm must remove all statements which cannot affect the slicing criterion. In general, completeness is unachievable (for theoretical reasons to do with undecidability).
-
Therefore, the goal of slicing algorithms is to delete as many statements as possible, without giving up soundness. The closer an algorithm approximates completeness, the more precise the slices it constructs will be.
-
It has been proven that a dynamic slice constructed for some variables at a certain point will always be at least as thin as the corresponding static slice, and in practice we find that dynamic slices are often a great deal simpler.
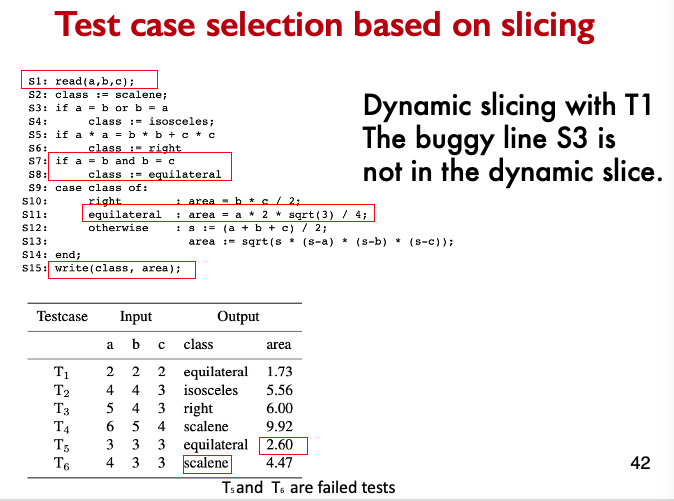
Test case prioritization
Test case prioritisation concerns ordering test cases for early maximisation of some desirable properties, such as the rate of fault detection.
It seeks to find the optimal permutation of the sequence of test cases. It does not involve selection of test cases, and assumes that all the test cases may be executed in the order of the permutation it produces, but that testing may be terminated at some arbitrary point during the testing process.

-
If the goal of prioritization is to maximize early fault detection. It is obvious that the ordering A-B-C-D-E is inferior to B-A-C-D-E.
-
In fact, any ordering that starts with the execution of C-E is superior to those that do not, because the subsequence C-E detects faults as early as possible; should testing be stopped prematurely, this ensures that the maximum possible fault coverage will have been achieved.
-
Coverage is a metric that is often used as the prioritization criterion. The intuition behind the idea is that early maximization of structural coverage will also increase the chance of early maximization of fault detection.
-
Therefore, while the goal of test case prioritization remains that of achieving a higher fault detection rate, prioritization techniques actually aim to maximize early coverage.
-
Different algorithms are used to search for optimal prioritization: random, hill climbing, genetic, greedy, etc.
Using Test History to Prioritize Tests
slide 47/99
Quantifying Flaky Tests to find Test Instabilities
A flaky test passes and fails on the same build
Why would I keep a flaky test
- Some tests have inherent non-determinism
- Hardware/Environmental noise
- Asynchronous properties
- Decision is not rule based, but based on an AI model of data
- Broken tests
- Some tests can be very expensive to fix
Google’s Solution: “Know flaky”
- Run it three times, only report a fault if it fails three times in a row
- Developers start ignoring flaky tests unless they fail three times
- Expensive
- Integration test that runs in 15 minutes
- Requires three runs or 45 minutes to determine the outcome
Microsoft’s solution
- Run test 1000 times and determine the outcome
- If below a flaky threshold
- Quarantine the test and report a bug
Steps for quantifying flaky tests
- Measure of the degree of test flakiness (FlakeRate = flakes/runs)
- Establish the FlakeRate baseline on stable build or release
- How flaky are my tests?
- a. Number of runs to have statically confident StableFlakeRate
Test outcomes
Good outcomes
- Test fails and finds a fault (TP)
- Test passes and there is no fault (TN)
Flaky Outcomes
- A test fails, but no fault is found in the software (FP)
- Wasted effort to investigate flaky failure
- A test passes, but a fault slips through to production (FN)
- Potential end user crash (slipthrough)
How accurate vs. flaky is a test?
Accuracy = (TP+TN)/runs = (fail_with_fault + pass_no_fault)/runs
FlakeRate = (FP + FN)/Runs = 1-accuracy = (fails_no_fault + slipthroughs)/runs
- We can say at test is 99% accurate or we can say it flakes 1/100 times
- We can measure the FlakeRate over a period of time
Which tests are flaky?
Flaky Test
- Definition: A flaky test passes and fails on the same build
- Examples of stable builds
- A build that has successfully been running in production
- The previous stable release to a customer
- Need a stable build so that
- Any test failure is a FlakyFailure (ie a false positive)
- Any test pass is a good pass (ie true negative)
A passing test is not enough!
Flaky tests add extra runs, which add extra expense.
Quantifying
- Measure of the degree of test flakiness (FlakeRate = flakes/runs)
- Establish the FlakeRate baseline on stable build or release
- How flaky are my tests?
- Number of runs to have statically confident StableFlakeRate
Prioritizing 4. Likelihood of change in stable state (binomial distribution) 5. Prioritizing re-runs to find instabilities (probability of a set of runs)
A bunch of binomial and bernoulli distribution crap…
Example: Given the following test distribution

How likely is all fails?

A noisy pass

- P value = 0.041632 with 4 runs
Alternating Pass/Fail
- p value = .0.03715
All passes
- p = .04779.
Prioritizing Re-runs
Noise vs. Signal
Signal
- The test starts failing much more than expected
- Likely someone changed the code and there is a fault
Noise
- The test fails at expected levels
- Likely just the normal interference (async or environmental issues)
A running example of prioritization....
From slide 91 to 98

…
Should I fix my flaky test?
- Test are no longer binary, we are doing anomaly detection
- Changes in the stable FlakeRate (instabilities)
- So long as behaviour of the system is stable, then maybe not
- You still get signal from the test by re-running and examining
- However making a test less flaky will mean less noice
- Any failure will become more unlikely and require fewer re-runs
- Tradeoff the cost to fix the test vs. the cost to re-run and calculate
Week 9
Automated Debugging
Statistical Fault Localization
Producing Ranked Bug report
- We use the Tarantula toolkit.
- Given a test-suite T

- fails(s) = # of failing executions in which s occurs
- pass(s) = # of passing executions in which s occurs
- allfail = Total # of failing executions
- allpass = Total # of passing executions
- allfail + allpass = |T|
- Can also use other metric like Ochiai
Overall, statistical fault localization techniques help automate the process of identifying possible fault locations in a program, aiding developers in focusing their debugging efforts more effectively.
Example 1
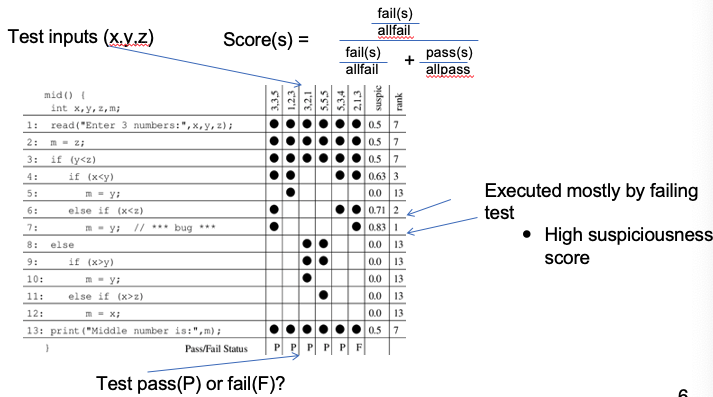
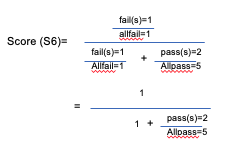
Example 2


Delta Debugging
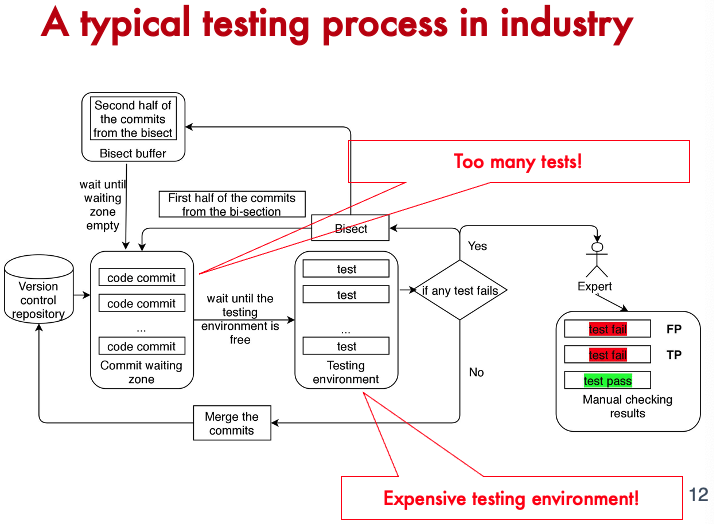
Background: Test All vs. Batch Testing
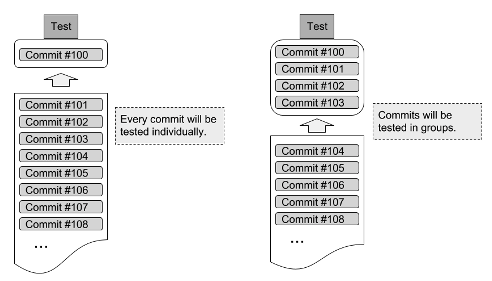
- If tests pass, we can just merge the commits.
- What if test failed?
- Do we need to go back to testing every commit?
Simplification
Once we have reproduced a program failure, we must find out what’s relevant:
- Does failure really depend on 10,000 lines of code?
- Does failure really require this exact schedule of events?
- Does failure really need this sequence of function calls?
Prof's note
A typical bug report contains a lot of information that the developer can use to reproduce the program failure. Once we have reproduced a program failure, we must find out what information is relevant. For instance,
Does the failure really depend on 10,000 lines of code?
Does the failure really require this exact schedule of events?
Does the failure really need this sequence of function calls?
Why Simplify?
- Ease of communication: a simplified test case is easier to communicate
- Easier debugging: smaller test cases result in smaller states and shorter executions
- Identify duplicates: simplified test cases subsume several duplicates
Prof's note
- Simplifying the information in a bug report down to only what is relevant is important for several reasons.
- First is ease of communication: a simplified test case is easier to communicate to members of the development and testing team.
- Second is that simpler test cases lead to easier debugging: a smaller test case results in smaller states and shorter executions.
- Third is that it allows us to identify and collapse duplicate issues: a simplified test case can subsume test cases in several bug reports.
Real World Scenario
Let’s look at a real-world scenario which should help motivate the necessity for bug minimization.
Bugzilla, the Mozilla bug database, had over 370 unresolved bug reports for Mozilla’s web browser. These reports weren’t even simplified, and the bug queue was growing by the day. Mozilla’s engineers became overwhelmed with the workload.
Under this pressure, the project manager sent out a call for volunteers for the Mozilla BugAThon: volunteers to help process the bug reports. Their goal was to turn each bug report into a minimal test case, in which each part of the input is significant in reproducing the failure. The volunteers were even rewarded with perks for their work: volunteers who simplified 5 reports would be invited to the launch party, and those who simplified 20 reports would receive a T-shirt signed by the engineering team.
Clearly, Mozilla would have benefitted from an automated bug minimization process here!

Let’s look at a concrete bug report in the Mozilla bug database.
Consider this HTML page. Loading this page using a certain version of Mozilla’s web browser and printing it causes a segmentation fault. Somewhere in this HTML input is something that makes the browser fail. But how do we find it?
If we were the developers of the Mozilla web browser that crashes on this input, we would want the simplest HTML input that still causes the crash.
So how do we go from this large input to …
this?
- this simple input — a mere select tag — that still causes the crash?
Your Solution:
- How do you solve these problems?
- Binary Search
- Cut the test-case in half
- Iterate
- Brilliant idea: why not automate this?
Prof's note
What do we as humans do in order to minimize test cases?
One possibility is that we might use a binary search, cutting the test case in two and testing each half of the input separately. We could even iterate this procedure to shrink the input as much as possible. Even better, binary search is a process that can be easily automated for large test cases!
Binary Search
- Proceed by binary search. Throw away half the input and see if the output is still wrong.
- If not, go back to the previous state and discard the other half of the input.

- This bar here represents the original failure-inducing input to a program.

- If one half of the input causes the program to fail, then we can eliminate the second half of the input and attain a smaller, failure-inducing input.

- We can repeat the procedure on the new, smaller failing input; in this case, the first half of the halved input causes the program to fail, so we can throw away the second half. We are left with an input that induces a failure but which is a quarter of the size of the original input.

- Repeating the procedure, we might find that the first half of the new input does not crash the program …

- … but that the second half does cause the program to fail. In this case, we’d remove the first half and keep the second half to obtain yet a smaller failure-inducing input.

- Iterating again, we might find that the first half of the new input does not crash the program …

- … and so does the second half.
- In this case, binary search can proceed no further. The simplified input is this dark green portion of the bar, one-eighth the size of the original input, which is good progress!

We can apply the binary search algorithm to minimize the number of lines in the HTML input we saw earlier: the one that crashed Mozilla’s web browser. We’ll assume line granularity of the input for this purpose; that is, we only partition the input at line breaks.
Simplified Input

- The algorithm outputs the following line, simplifying from 896 lines in the original input to this single line, in only 57 tests.

Suppose that we wish to further simply this input using character-level granularity to obtain the desired output comprising only the <Select> tag. Let’s see how the binary search algorithm works this time.

- The initial input consisting of the entire line causes the browser to crash.

- The first half of the line doesn’t cause the browser to crash.

- And the second half of the line also doesn’t cause the browser to crash. At this point, binary search says we’re stuck, since neither half of the input induces a failure on its own. Is there some other way we can minimize the input?
Two Conflicting Solutions
Prof's note
Let’s generalize the binary search procedure a bit. Instead of requiring ourselves to divide inputs strictly in half at each iteration, we could allow ourselves more granularity in dividing our input.
Perhaps we could divide up our input into many (possibly disconnected) subsets at an iteration and only keep those which are required to cause a failure. In particular, we can break up the input into blocks of any size, called “changes” from the original input. (The traditional use of the Greek letter “delta” for change is the origin of the name “delta debugging.”) We can then use subsets formed from these blocks. Perhaps we just use a single block, perhaps we use several blocks concatenated together, or perhaps we use noncontiguous blocks (for example, block delta-1 and block delta-8) to form subsets for testing.
Impact of Input Granularity
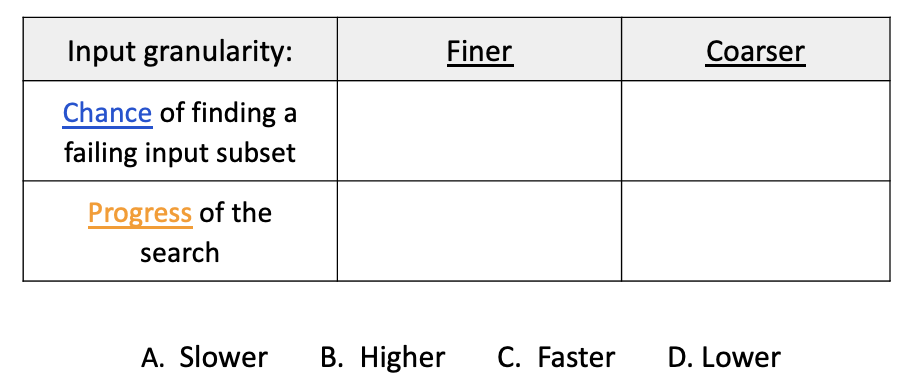
- This gives us two opposing strategies with their own strengths and weaknesses.
- Take a moment to consider what might happen if we allow the granularity of the input changes we use to be finer or coarser.
- Finer granularity means our input is divided into more, smaller blocks; coarser granularity means our input is divided into fewer, larger blocks.
- What would happen to the chance of finding a failing subset of the input? And how much progress would we make if we found a failing subset of the input?
- Fill in each box with the appropriate letter: A for slower progress, B for higher chance of finding a failing subset, C for faster progress, and D for lower chance of finding a failing subset.
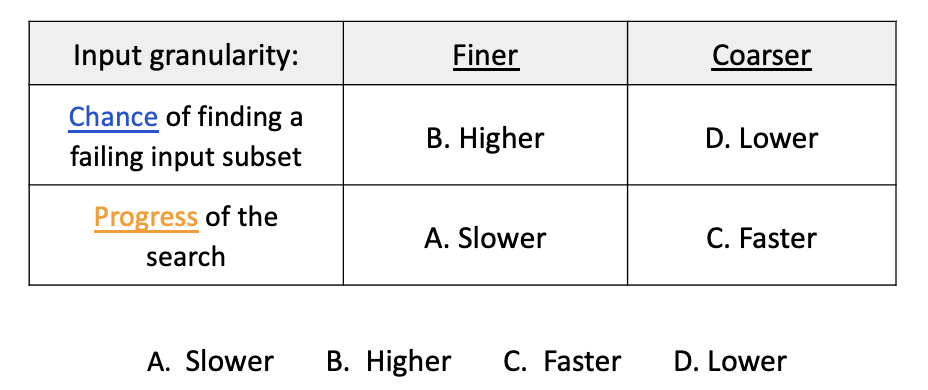
-
By testing subsets made up of larger blocks (coarser granularity), we lower our chance of finding some subset of the blocks that fails a test, but we have fewer subsets that we need to test. Additionally, upon finding a subset of blocks that fails, we can eliminate a large portion of the input string. This means our progress toward a minimal test case is faster.
-
On the other hand, by testing subsets made up of smaller changes (finer granularity), we have more subsets that we have to test; and upon finding a subset of changes which causes failure, we typically can only remove small portions of the input string. These both slow our progress towards finding a minimal failing test case. However, the tradeoff is that by testing more subsets, we increase our chance of finding a smaller subset that actually does cause a failure. Indeed, we could go so far as to making the granularity of the input changes one character in size, which would guarantee we find the minimum failing test case, but this strategy in the worst case would take exponential time in the length of the input.
General Delta-Debugging Algorithm

Prof's note
The delta-debugging algorithm combines the best of both approaches. At first, it divides the input into larger blocks, and it tests all subsets of these changes for failure. As the algorithm becomes unable to find subsets that fail the test, delta debugging increases the granularity of its changes, testing subsets formed from smaller blocks for failure.
Example: Delta Debugging
Let’s see how delta debugging would proceed with our example from earlier. Recall that neither half of the original input string caused a crash in Mozilla’s browser.
Using delta debugging, we increase the granularity of the blocks we will use to create subsets, by decreasing their size by a factor of two. We first test the subset formed from the second, third, and fourth blocks: this subset doesn’t cause a crash since it does not include the
<SELECT>tag.
Next we test the subset formed from the first, third, and fourth blocks. This does cause a crash, since it includes the
<SELECT>tag, so we can eliminate the second block from consideration altogether.
Next, let’s see what happens if we keep only the first and fourth blocks. Again, this causes a crash, since it includes the
<SELECT>tag, so we can eliminate the third block from consideration.
Removing the fourth block causes the input to pass the test, as the closing bracket of the
<SELECT>tag is missing in this input. So we would end up keeping the first and fourth blocks and increasing the granularity before continuing to test subsets …





Continuing Delta Debugging
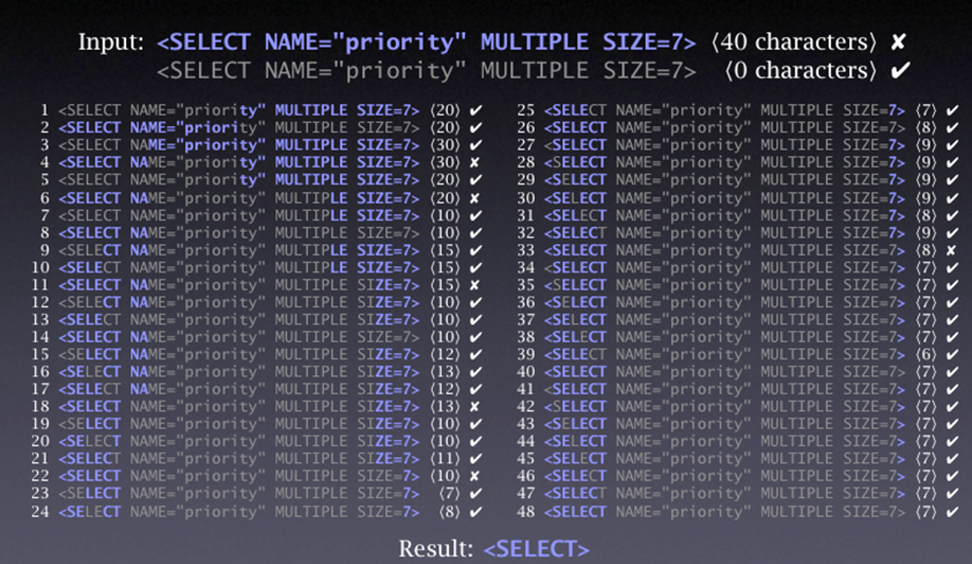 … until we eventually end up with the minimal failing input, comprising only the
… until we eventually end up with the minimal failing input, comprising only the <SELECT> tag, after 48 iterations.
Inputs and Failures
- Let be the set of possible inputs
- corresponds to an input that passes
- corresponds to an input that fails
Prof's note
Now that we’ve seen an example of how delta debugging would work in practice, let’s formally define the algorithm so that we can analyze its properties and prove that it will work as expected.
Let R be the set of all possible inputs that we wish the delta debugging algorithm to consider. We’ll use to denote an element of R on which the program passes, and to denote an element of R on which the program fails.

- An example of r_p is any of the following passing inputs, such as [hand-circle any input with a tick mark].
- An example of r_f is any of the following failing inputs, such as [hand-circle any input with a cross mark].
Changes
- Let R denote the set of all possible inputs
- We can go from one input r1 to another input r2 by a series of changes
- A change 𝛅 is a mapping R ⟶ R which takes one input and changes it to another input
Prof's note
The key building block in the delta debugging algorithm is the concept of a change, which is how one input is transformed into another.
Formally, a change is a mapping from the set of all test inputs to itself. In other words, it’s a function that takes a test input and returns another test input .
In the Mozilla example from earlier, applying δ means to expand a trivial (empty) HTML input to the full failure-inducing HTML page.
Example: insert ME=” priori at input position 10
r1 = <SELECT NAty" MULTIPLE SIZE=7>
𝛅’(r1) = <SELECT NAME="priority" MULTIPLE SIZE=7>
Prof's note
The operation of inserting the string ME=”priori between the 10th and 11th character positions of the input would be an example of a change function relevant to the Mozilla example from before.
Other examples of change functions are the operation of concatenating a semicolon at the end of a string, removing the first character of a nonempty string, and reversing the order of a string. Even the function that simply returns its input string is a change: it serves as the identity change function.
Decomposing Changes
- A change 𝛅 can be decomposed to a number of elementary changes 𝛅1, 𝛅2, …, 𝛅n where 𝛅 = 𝛅1 o 𝛅2 o … o 𝛅n and (𝛅i o 𝛅j)(r) = 𝛅j(𝛅i(r))
- For example, deleting a part of the input file can be decomposed to deleting characters one by one from the file
- In other words: by composing the deletion of single characters, we can get a change that deletes part of the input file
Prof's note
We next introduce the concept of decomposing a change function into a number of elementary change functions such that applying each elementary change in order to an input r has the same effect as applying the original change to that input r all at once.
For example, suppose deleting a line from an input file results in a failure. We can decompose this deletion to a sequence of individual character deletions.

Looking again at our Mozilla example from before, we can decompose the change denoted by delta’, which represents inserting this string at input position 10, into elementary changes as follows.
delta’ = delta_10 composed with delta_9 composed with so forth down to delta_1, where
delta_1 is the change that inserts the character M at position 10
delta_2 is the change that inserts the character E at position 11
… and so on.
Note that what we consider an elementary change can depend on the context of the problem. We could consider insertions and deletions of lines in a file to be elementary. Or if we are using delta debugging on a set of binary parameters for a program, an elementary change might be switching one bit on or off.
Summary
- We have an input without failure:
- We have an input with failure:
- We have a set of changes such that:
- Each subset of of is a test case
Prof's note
Let’s review the setup we have going into the delta debugging algorithm.
We have an input on which our program passes: . We have an input on which our program fails: . And we have a set of elementary changes, which we’ll call , such that applying the changes in order to yields .
Note that is typically a simple input on which the program trivially passes, such as the empty input, and is typically a complex input on which the program fails, and that we would like to minimize. In the case of Mozilla web browser, could be a blank HTML file, and is the full HTML file that causes the browser to crash.
Subsets of will be important in the delta debugging algorithm, so we will distinguish them henceforth by calling them test cases.
Running Test Cases
- Given a test case c, we would like to know if the input generated by applying changes in c to rP causes the same failure as rF
- We define the function test: Powerset(cF) ⟶ {P, F, ?} such that, given c = {𝛅1, 𝛅2, …, 𝛅n} ⊆ cF test(c) = F iff (𝛅1 o 𝛅2 o … o 𝛅n)(rP) is a failing input
Prof's note
Given a test case, that is, a subset of the changes, we want the ability to apply that subset of changes to the passing input r_p and determine if the resulting input causes the program to fail in the same manner as the failing input r_f.
To formalize this notion, we define the function test which takes a subset of c_f and outputs one of three characters based on the outcome of our test.
We distinguish these three test outcomes following the POSIX 1003.3 standard for testing frameworks.
- If the test succeeds, the test function outputs PASS, written here as P.
- If the test produces the failure it was intended to capture, the test function outputs FAIL, written here as F.
- And if the test produces indeterminate results, the test function outputs UNRESOLVED, written here as ‘?’.
Minimizing Test Cases
- Goal: find the smallest test case c such that test(c) = F
- A failing test case c ⊆ cF is called the global minimum of cF if:
- for all c’ ⊆ cF , |c’| < |c|⇒ test(c’) ≠ F
- The global minimum is the smallest set of changes which will make the program fail
- Finding the global minimum may require performing an exponential number of tests
Prof's note
The goal of delta debugging is to find the smallest test case c such that test(c) = F. In other words, to find the smallest set of changes we need to apply to passing input in order to result in the same failure as the failing input .
We call a failing test case a global minimum of if every other smaller-sized test case from does not cause the test to output F. In other words, any smaller-sized set of changes either passes the test or causes the test to be unresolved.
The global minimum is the smallest set of changes which makes the program fail; but finding the global minimum may require performing an exponential number of tests: if has size , we’d need to perform in the worst case tests to find the global minimum.
Search for 1-minimal Input
- Different problem formulation: Find a set of changes that cause the failure, but removing any change causes the failure to go away
- This is 1-minimality
Prof's note
Instead of searching for the absolute smallest set of changes that causes the failure, we can approximate a smallest set by reformulating our goal.
We will find a set of changes that causes the failure but removing any single change from the set causes the failure to go away.
Such a set of changes is called 1-minimal.
Minimizing Test Cases
- A failing test case is called a local minimum of if:
- for all , tests(c’) F
- A failing test case is n-minimal if:
- for all , test(c’)
- A failing test case is 1-minimal if:
- for all , test(c-)
Prof's note
More formally:
Define a failing test case C to be a local minimum of C_F if for every proper subset C’ of C, applying the test function to C’ doesn’t produce a failure. This is in contrast to a global minimum in the following way: for a local minimum, we only restrict our attention to subsets of the local minimum test case; for a global minimum, there must be no smaller test case that causes a failure.
Define a failing test case C to be n-minimal if for every proper subset C’ of C, if the difference in size between C’ and C is no more than n, then the test function applied to C’ does not cause a failure. In other words, C is n-minimal if removing between 1 and n changes from C causes the test function to no longer fail. Just as local minimality is a weakening of the notion of global minimality, n-minimality is a weakening of the notion of local minimality.
And 1-minimality is the weakest form of n-minimality: a failing test case is 1-minimal if removing any single change from that test case causes the test function to no longer fail.
Even though 1-minimality is not nearly as strong as global or even local minimality, we focus on it because it is still a strong criterion: it says that the test case cannot be minimized incrementally. And we can program an efficient algorithm for applying and testing incremental changes.
Exercise: Minimizing Test Cases
A program takes a string of a’s and b’s as input. It crashes on inputs with an odd number of b’s AND an even number of a’s. Write a crashing test case (or NONE if none exists) that is a sub-sequence of input babab and is:
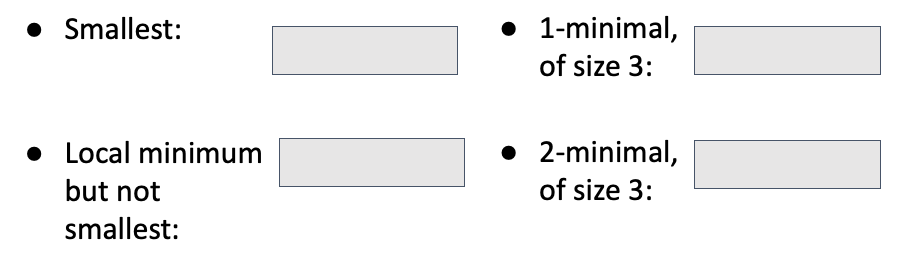
Prof's notee
{exercise SLIDE}
Let’s stop here to check your understanding of the different types of minimality with a quiz.
Suppose a program takes a string of ‘A’s and ‘B’s as input, and it crashes if given an input with an odd number of ‘B’s AND an even number of ‘A’s.
Because ‘BABAB’ has an odd number of ‘B’s and an even number of A’s, it is a failing input to the program. If we take to be the empty input and to be ‘BABAB’ and consider inserting each character to be a separate change, then will be a set of five elementary changes.
Previously we defined a test case to be a subset of these changes, which was a set of delta functions. For brevity, we won’t use the delta notation in this quiz; instead, we’ll slightly abuse terminology and just consider test cases to be the subsequences of ‘BABAB’ that result from applying those changes in a subset of .
Here, I’d like you to enter four failure-inducing test cases that are subsequences of the input ‘BABAB’ satisfying the following constraints:
- First, find the the global minimum test case (that is, the smallest possible failing subsequence)
- Second, find a local minimum that is not the global minimum
- Third, find a 1-minimal failing test case of size 3
- And lastly, find a 2-minimal failing test case of size 3
If no subsequence of ‘BABAB’ exists satisfying the constraints, enter the word “NONE” instead.
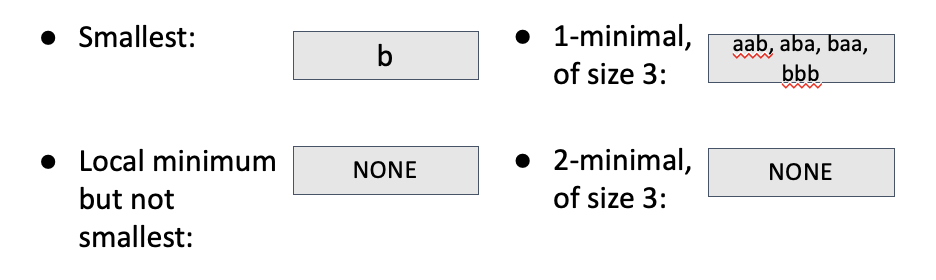
Prof's note
{SOLUTION SLIDE}
Let’s start with the global minimum. Notice that the program crashes only on nonempty inputs (since we need to include at least one ‘B’ to have an odd number of ‘B’s), we start by considering subsequences of size 1. The only input of size 1 with at least one ‘B’ is the string consisting of just ‘B’. This subsequence fails the test (it has 1 ‘B’ — an odd number, and 0 ‘A’s — an even number). Since ‘B’ is the smallest possible failing subsequence of ‘BABAB’, it is the global minimum failing test case.
Next, let’s try to find a local minimum that is not a global minimum. Remember that no proper subsequence of a local minimum can fail. But earlier we said that all failing subsequences will need at least one ‘B’. So every failing subsequence of ‘BABAB’ itself has a failing subsequence: ‘B’. So the only local minimum is ‘B’ itself, so there are no local minima that are not global minima.
Now, let’s try to find a 1-minimal failing subsequence of ‘BABAB’ of size 3. First, we’ll list all failing subsequences of size 3: we need at least one ‘B’, and we need an even number of ‘A’s. This means we can either have 2 ‘A’s and 1 ‘B’ or 3 ‘B’s. There are four subsequences of ‘BABAB’ that satisfy this criterion: ‘AAB’, ‘ABA’, ‘BAA’, and ‘BBB’.
Now let’s see which of these are 1-minimal. Remember that a failing test case is 1-minimal if, no matter which change we remove, we get a passing test case. Now, removing one character from any of these strings results in changing the parity of either the ‘A’s or the ‘B’s, meaning that the new subsequence will not cause a crash. Thus, all of these subsequences are 1-minimal.
Are any of them 2-minimal, however? This means that, in addition to removing one character, removing any two characters arbitrarily still causes the subsequence to pass. In this case, however, by removing two characters and leaving just a single ‘B’, we obtain a failing input. So none of these test cases are 2-minimal.
Naive Algorithm
- To find a 1-minimal subset of c:
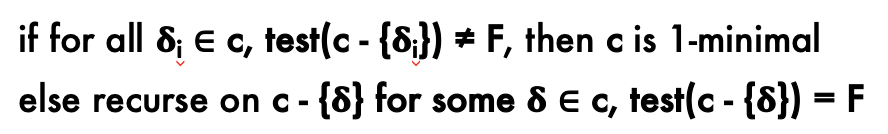
Prof's note
Now, let’s think about how to build an algorithm to find a 1-minimal subset of a given set of changes c; we would then apply this algorithm to find the 1-minimal subset of the set of all changes by setting c to .
One straightforward approach that might occur to us is to do the following: Iterate through each change in , testing whether the set c minus delta_i fails or not. If we find a change delta such that c without delta still induces failure, then we call the algorithm recursively on . On the other hand, if every change’s removal causes the test to stop failing, then c is 1-minimal, so we return c.
Running-Time Analysis
- In the worst case,
- We remove one element from the set per iteration
- After trying every other element
- Work is potentially
- This is
Prof's note
How well does this naive approach work? Well, in the worst case, we would remove the last change in the list per iteration after testing all previous changes.
If we start with N elements, then we perform up to N-i tests on the ith iteration (starting from iteration 0). The total number of tests in the worst case would then be N plus N-1 plus N-2 and so forth.
For large values of N, this is approximately one-half N^2, or O(N^2) in asymptotic notation.
Work Smarter, Not Smarter
- We can often do better
- It is silly to start removing one element at a time
- Try dividing the change set in two initially
- Increase the number of subsets if we can’t progress
- If we get lucky, search will converge quickly
[!Note ] Prof’s note We can often attain better performance than the first, simplest algorithm we thought of. Let’s try to see if we can improve our algorithm’s performance by making some modifications.
What’s one place where we are losing time in our algorithm?
Recall our discussion earlier about the strengths and weaknesses of coarser versus finer granularity. Checking one change at a time is very fine granularity, which allows for a greater chance of success in finding a failure-inducing subset of changes. But it is also more time-consuming. If we start with very coarse changes at first, we might be able to save a lot of time; only if we can’t make any progress should we refine our granularity and increase the number of subsets we test.
Exercise: Minimization Algorithm
A program crashes when its input contain 42. Fill in data in each iteration of the minimization algorithm assuming character granularity.
Week 10
Software Reviews and Inspections

- What are some example techniques for static V&V?
- Static analysis tools
- Compiler warnings
- Some examples of dynamic V&V?
Software inspections & reviews: Advantages over dynamic V&V
Cascading errors can obfuscate test results:
- Once an error occurs, later errors may be new, or are the cascading effect of the prior error Incomplete versions can be inspected:
- Tests require an executable version of the system, while inspections do not Good inspections are more than “bug hunts” :
- Inspections uncover inefficiencies and style issues
- Inspections are a form of knowledge sharing and collaborative problem solving
Inspections: Roles
- Moderator
- Recorder
- Reviewer
- Reader
- Producer
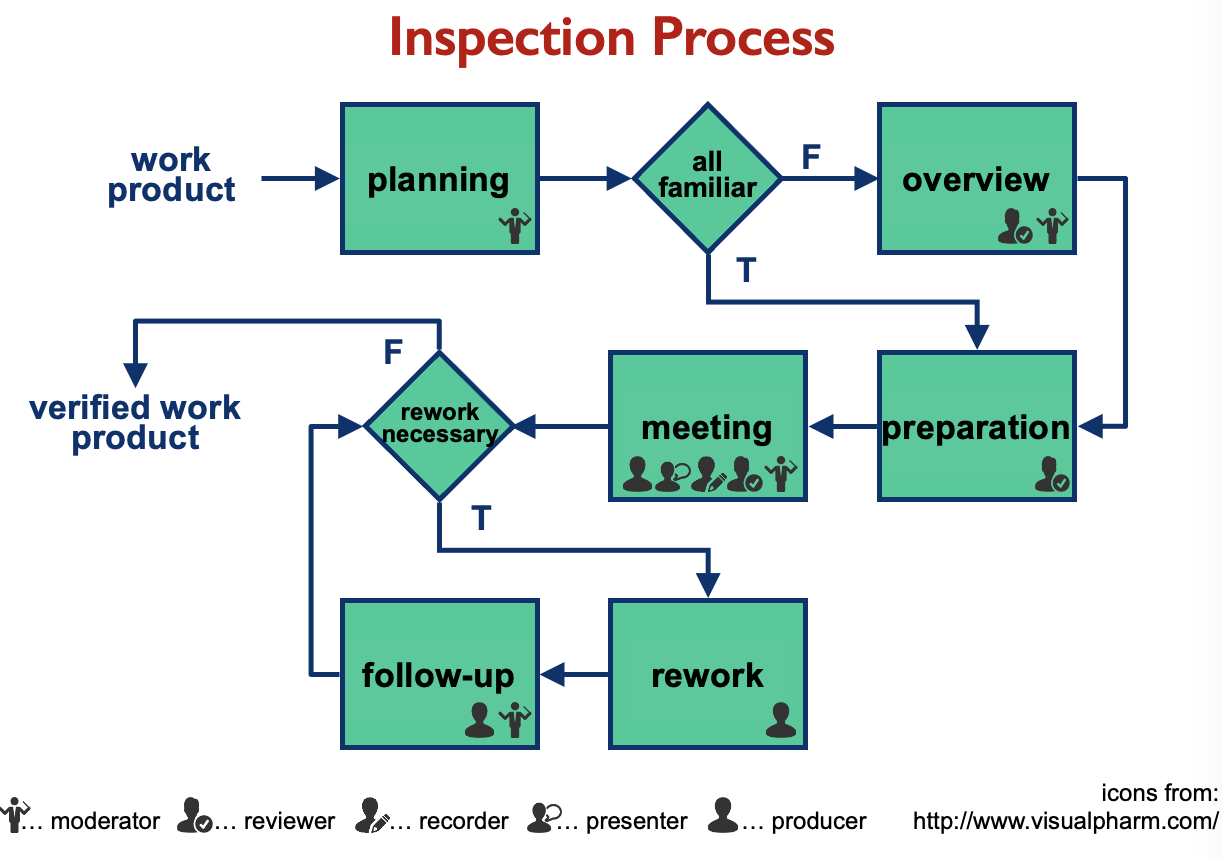
Inspection Process:
- Planning
- Overview
- Preparation
- Inspection meeting
- Third hour
- Rework
- Follow up
Buddy Check
- Code walkthrough by one or more reviewers:
- Rad code and report errors back to developer
- Pair programming:
- Includes a form of buddy check
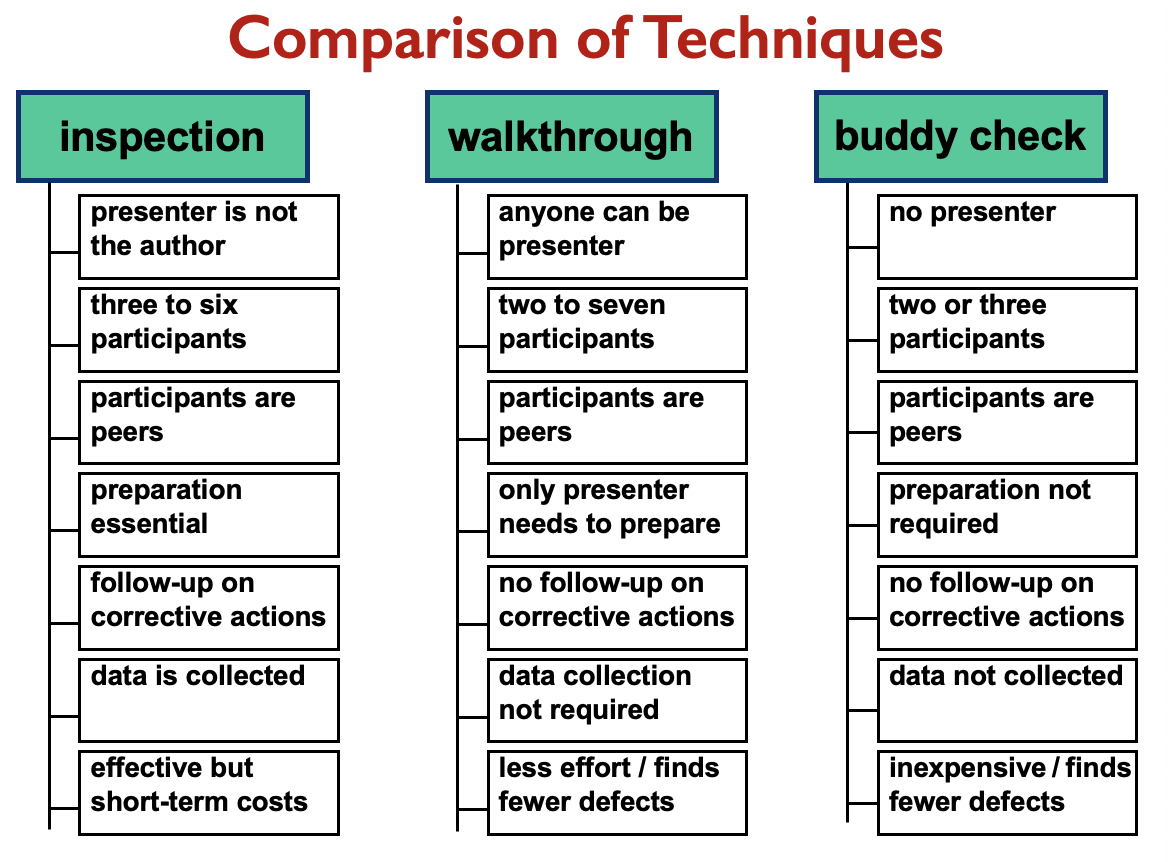
Modern Reviews: Roles
- Author
- Reviewer
Software Quality Metrics
Quality Metric
quantitative measure of the degree to which an item possesses a given quality attribute
Quality Metric
a function whose inputs are software data and whose output is a single numerical value that can be interpreted as the degree to which the software possesses a given quality attribute
Introduction to SQ Metrics
- Indicator:
- Metric that provides insight into software process, project or product (compared against a standard or threshold, e.g., target defects per year)
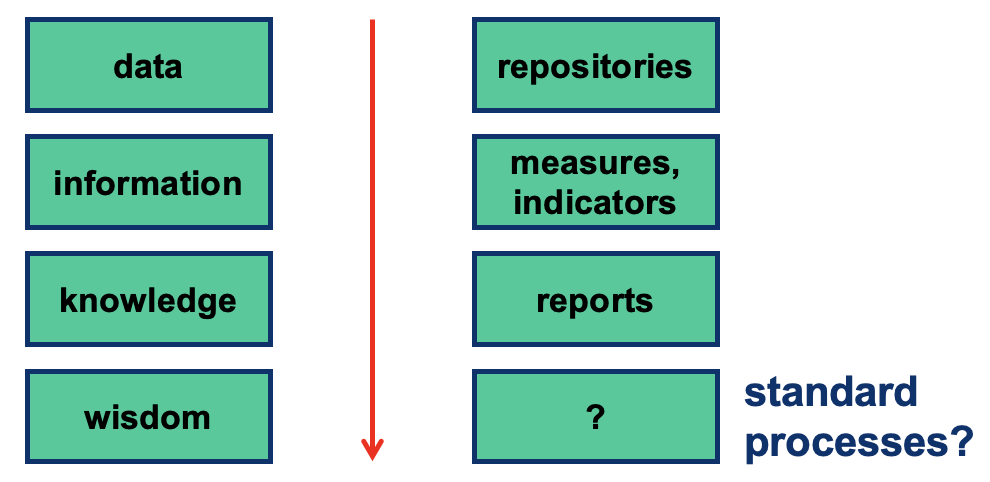
Software Size (Volume) Measures
- KLOC: classic measure of the size of software by thousands of lines of code
- Function Points (FP): a measure of the development resources (human resources) required to develop a program, based on the functionality specified for the software system
Types of Metrics
- Process metrics (refer to development)
- Product metrics (refer to operational phase)
- Project metrics (project characteristics & execution)
Week 11
Refactoring
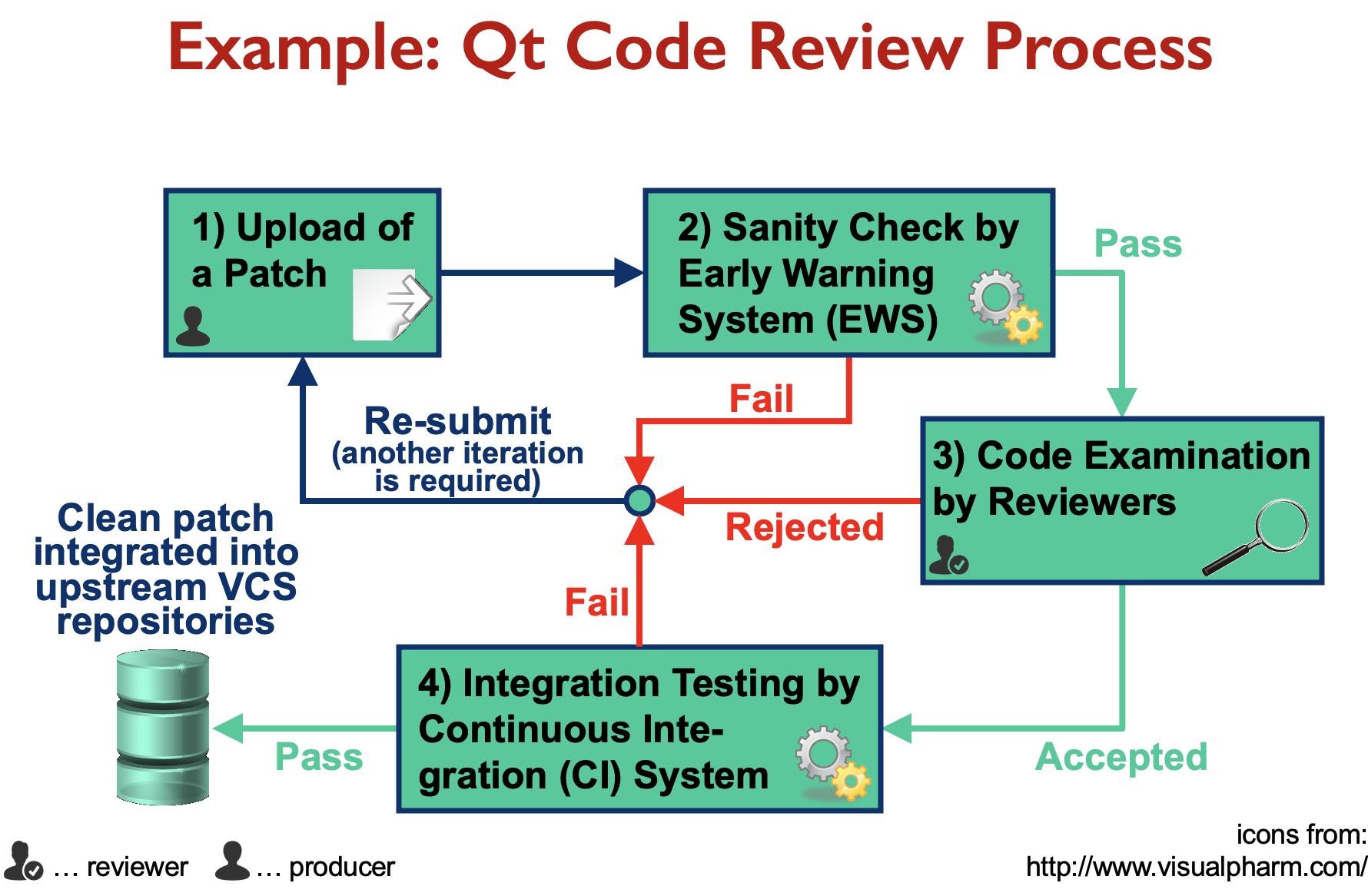
Refactoring constitute the main form of preventive maintenance and are source code transformations that can improve the design quality of a system and gradually bring it back to its original design state.
Refactoring Definition [Fowler, 1999]
”Refactoring is the process of changing a software system in such a way that it does not alter the external behaviour of the code yet improves its internal structure"
"It is a disciplined way to clean up code that minimizes the chances of introducing bugs."
"In essence when you refactor you are improving the design of the code after it has been written.”
Code smells
Essentially design flaws. Use refactorings to resolve them
For every code smell there is a list of refactorings that could be applied to remove it.
Detection Strategy
A detection strategy is a composition of various metric rules (i.e., metrics that should comply with proper threshold values) combined with AND/OR operators into a single rule that expresses a violation of a design heuristic.
Limitation: Threshold values should be manually determined and are project-specific. Different threshold values return different results.
DECOR
A method for the specification and detection of code and design smells based on a DSL (domain-specific language)
DETEX
A detection technique that instantiates DECOR
Long Method
- The longer a method is, the more difficult it is to understand.
- Larger modules are associated with higher error-proneness and change-proneness.
- Extracting code fragments having a distinct functionality into new methods can improve the understandability.
Prof's note
The extracted code is replaced with a method call. The name of the extracted method explains the purpose of the extracted code
In this way, the original method requires less time and effort for comprehension.
Slice-based cohesion metrics????todo
Duplicate Code (aka Software Clones)
- Is believed to be the worst code smell.
- In case of a bug or a new feature, all duplicate instances in the source code have to be found and updated.
- Inconsistent updates may lead to errors in the program.
Clone detection community defined 4 types of clones:
- Type 1: code fragments are identical except for variations in white space, layout, and comments.

- Type II: code fragments are structurally and syntactically identical except for variations in identifiers, literals, types, in addition to Type I differences.
- Generalize Type
- Parameterize Object Creation
- Parameterize Number Literal
- Type III: code fragments are copies with further modifications. Statements can be changed, added, or removed in addition to Type II differences.
- Type IV: two or more code fragments perform the same computation, but are implemented through different syntactic variants.
Ops vs DevOps
Developers add monitoring code to their software.
When software is deployed and under operation, it produced monitoring data (e.g., logs) that capture the runtime behaviour of the software.
Then, the monitoring data is analyzed. The results can provide insights for developers to identify potential problems or opportunities for improvement.
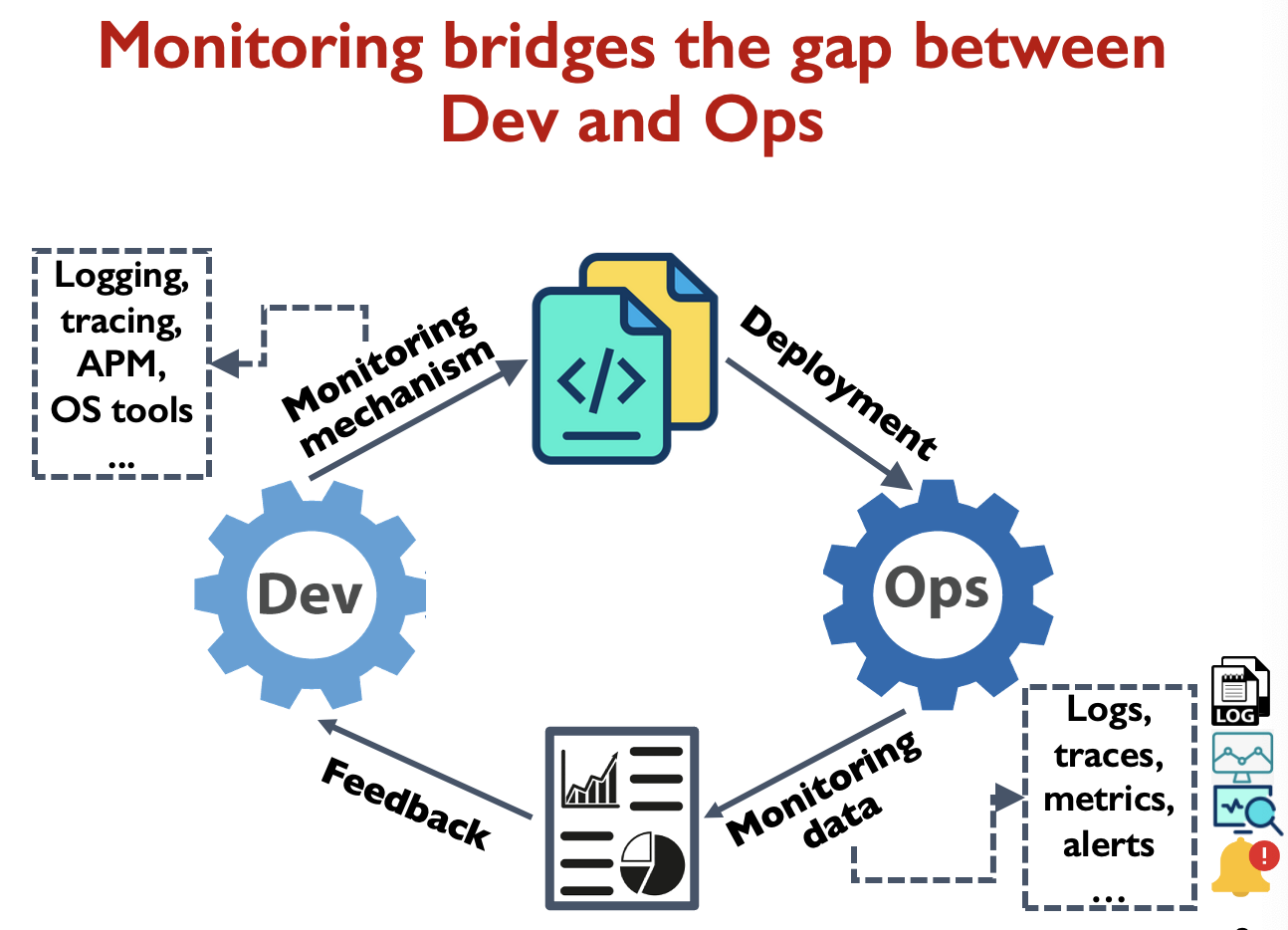
Why is logging related to software quality?
Inserting log statements into code can help:
- Debugging
- Anomaly detection
- System comprehension
- Auditing
- Etc. It may be the only way because debuggers are not always available or applicable
Why log and what to log?
- DevLogs are the “inner voice of your application”
- Performance metrics
- Timestamp, level/severity , thread name, method name, message
- Log more because
- You can’t diagnose a problem without data
- Distributed systems, logs are a must
- Legal compliance
- Performance overheads
- Log everything == log nothing
What should be logged?
- A log message should tell what happened and why it happened.
- Who was involved?
- What happened?
- Where did it happen?
- When did it happen?
- Why did it happen?
- How did it happen?
Log Structure
- Unstructured logs
- Logs contain “real data” from the context instead of purely messages
- Think about who is consuming it
Use file system for log files??
Modern log architecture
- Syslog (old)
- Forward logs to an aggregator
- Single central place, don’t have to watch that individual machines run out of storage
- Still files and “primitive” unix tools
- Aggregate into a search engine
- Single interface to all log data
- Language of search is more expressive than grep/regexp
- Most people don’t actually understand regexp
- Analytics not just finding things
- Lucene has basic stats built in
- Full text index
- Lucene has basic stats built in
Some simple analytics
- New version released
- Unique values of any of the fields
- See the behaviour overtime
- Traffic patterns overtime
Logging Library
Code basic setup
- private static Logger
logger = LogManager.getLogger(); logger.debug("Debug log message");logger.info("Info log message");logger.error("Error log message");
Log Level Hierarchy
- If the LogLevel is defined in the config
- Otherwise use parent’s level
Names must match exactly
- Appenders allow Log4j to print logs to multiple destinations
- For example, one destination as raw file, another destination into csv
- Appenders are inherited additively from the LoggerConfig hierarchy
- Log requests are forwarded down the hierarchy
- Additivity is on by default
- Stop the forwarding
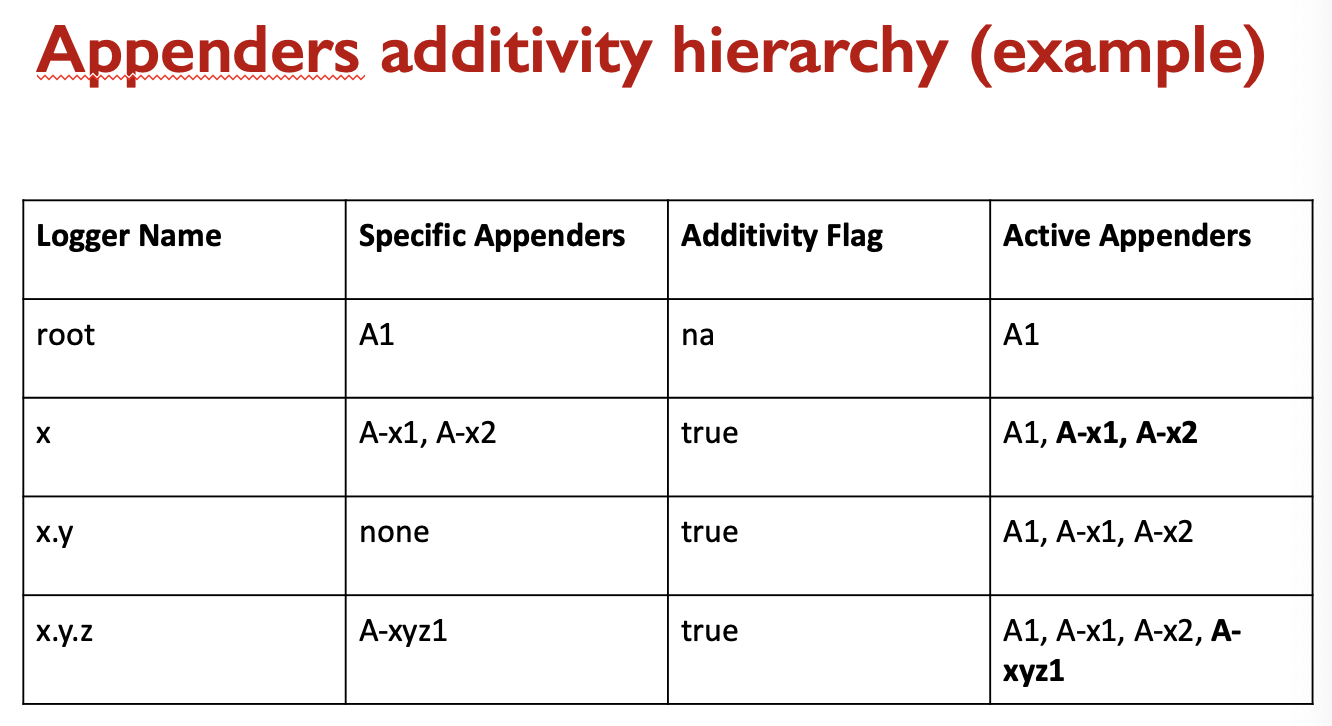
IMPORTANT

Log analysis
Filtering
- Keeping or discarding log data you care about.
- Parsing the raw log message into a common format so you can more easily analyze the data.
- More details later in log parsing.
Week 12
Load Testing
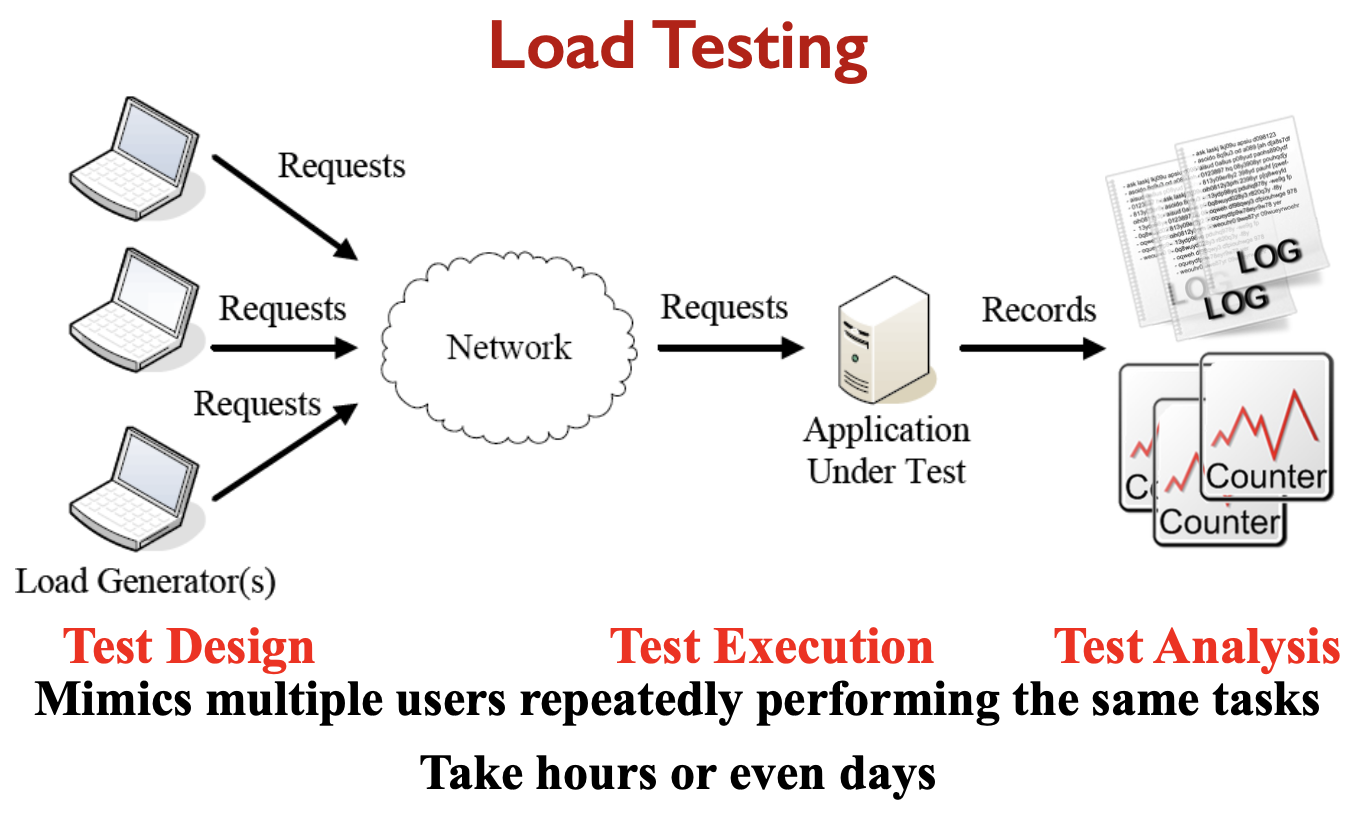
Designing a Load Test
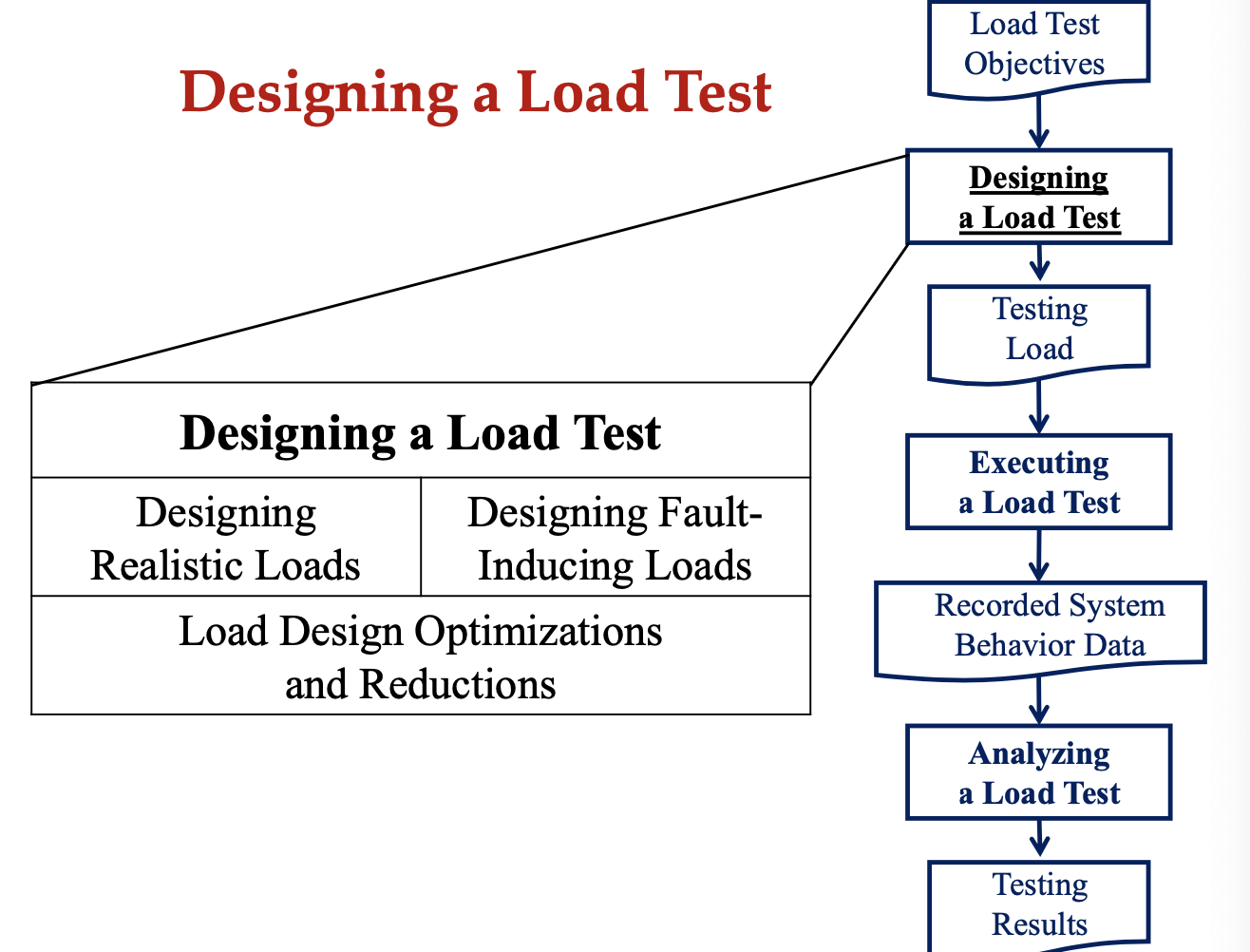
Designing Realistic Loads
- Aggregate Workload
- Use-Case
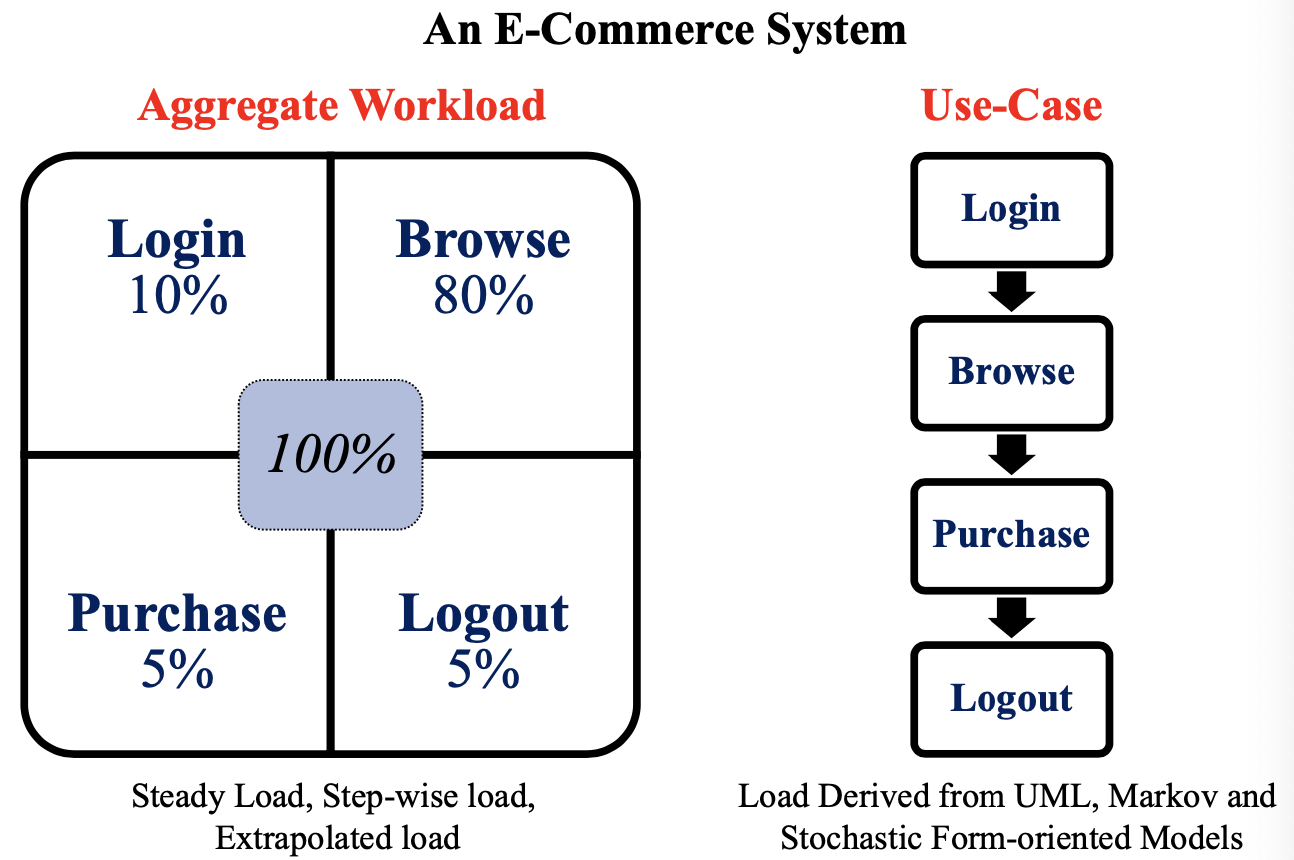
Designing Fault - Inducing Loads
- Source Code
- Identifies potential load sensitive modules and regions for load sensitive faults (e.g., memory leaks and incorrect dynamic memory allocation
- Annotating the Control Flow Graph of malloc()/free() calls and their sizes
- Load Sensitivity Index (LSI): indicates the net increase/decrease of heap space used for each iteration: the difference of the heap size before/after each iteration
- Write test cases which exercise the code regions with high LSI values
- Identifies potential load sensitive modules and regions for load sensitive faults (e.g., memory leaks and incorrect dynamic memory allocation
- System Models
- Genetic Algorithms
Load Design Reductions - Extrapolation
- Question: Can we reduce the load testing effort and costs, when there is limited time and hardware/software resources?
- Extrapolation for step-wise load testing
- Only examine a few load levels
- Extrapolate the system performance for the other load levels
Executing a Load Test
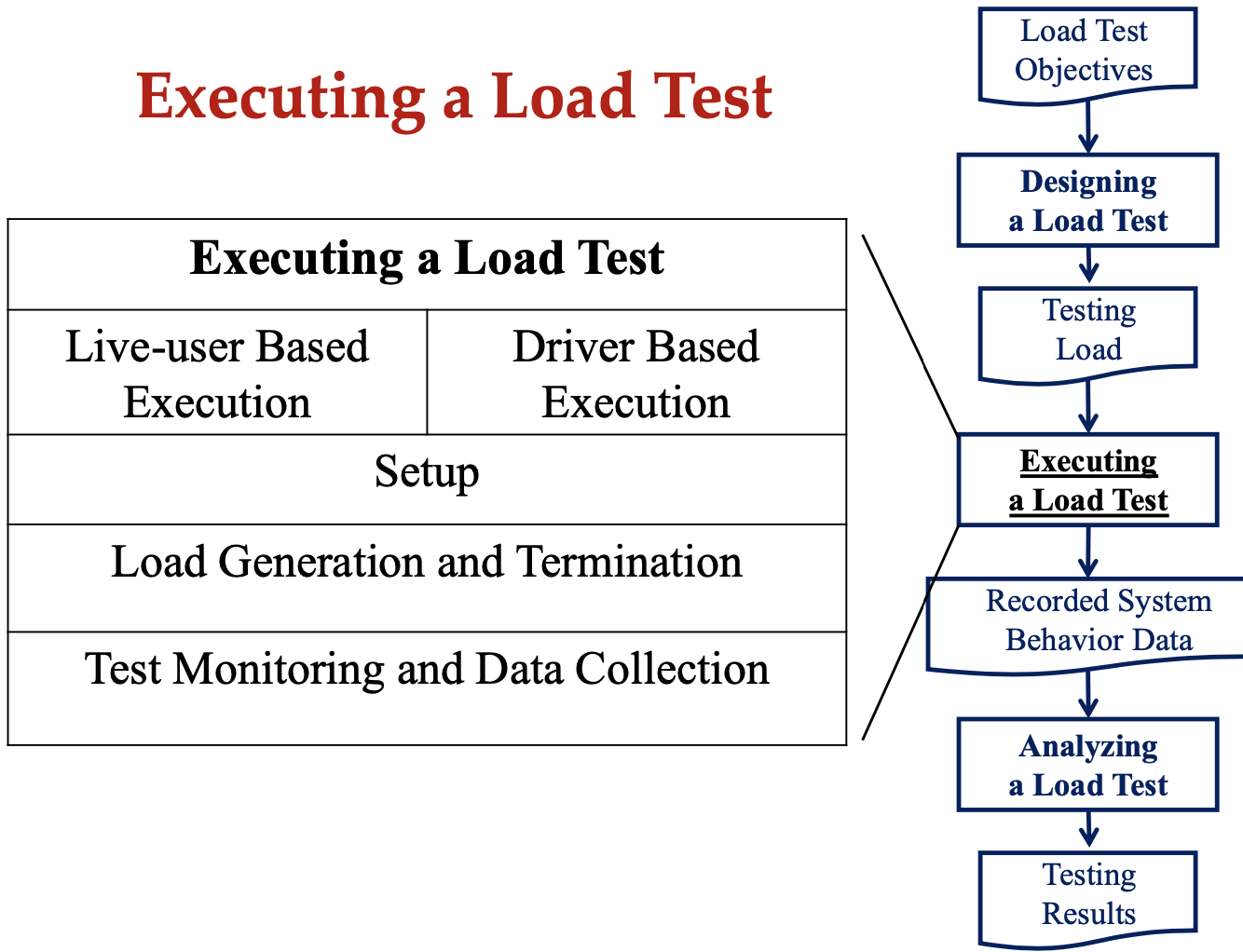
Test Execution setup
- Live-user-based executions
- Tester recruitment, setup and training
- Driver-based executions
- Programming
- Store-and-replay configuration
- Model configurations
Dynamic Feedback (I) - System Identification Techniques
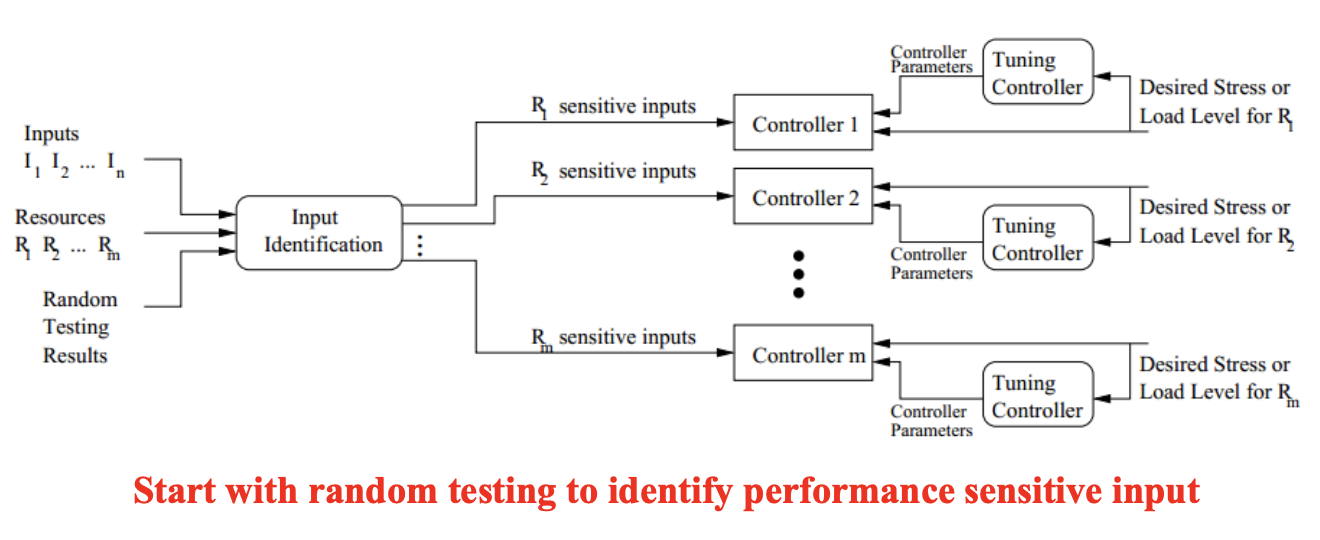
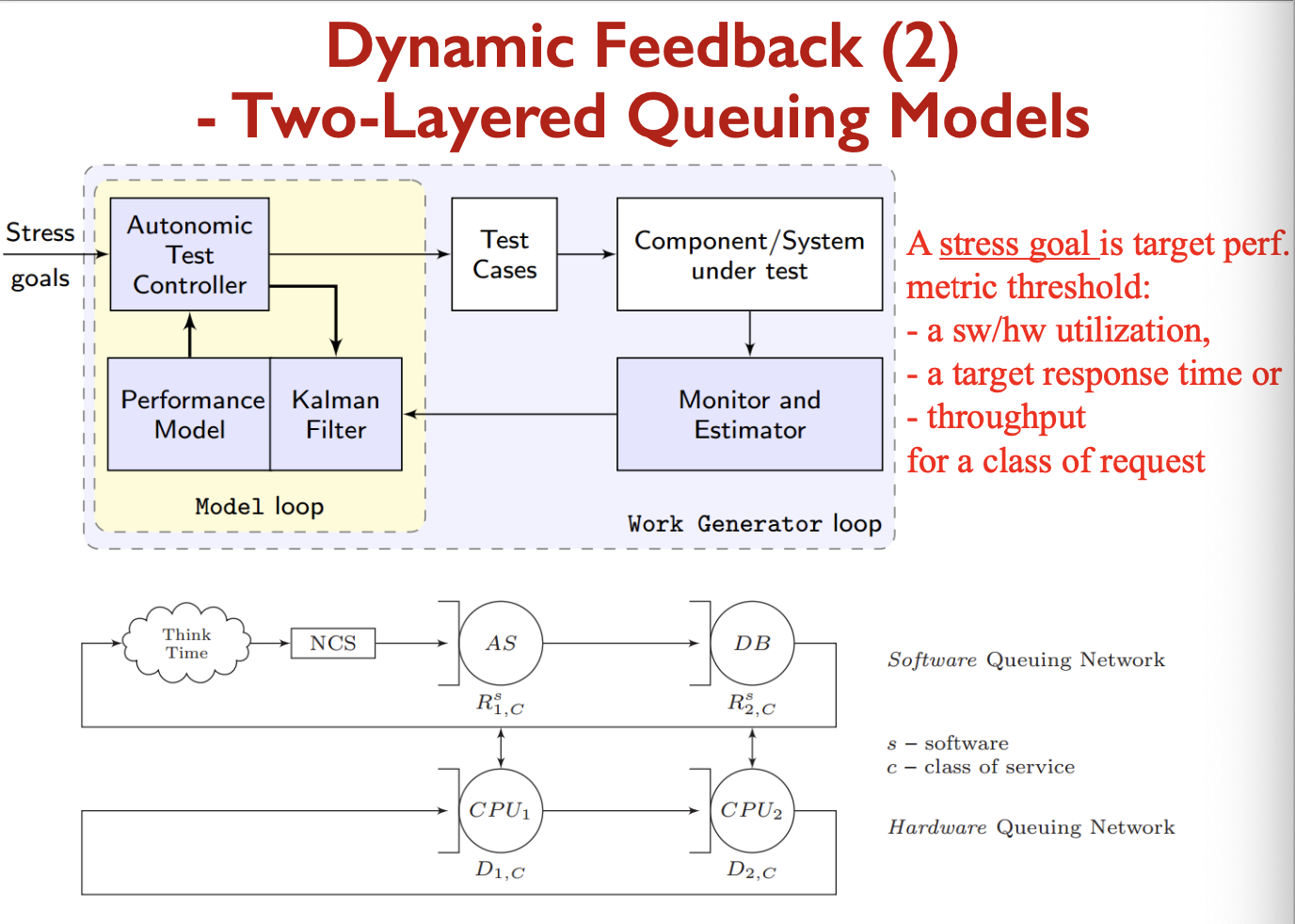
Analyze a Load Test
Detecting Known Problems Using Patterns
- Patterns in the memory utilizations
- Memory leak detection
- Patterns in the logs
- Error keywords
I give up…