Boyer-Moore Algorithm
Example with paper in the lecture slides:

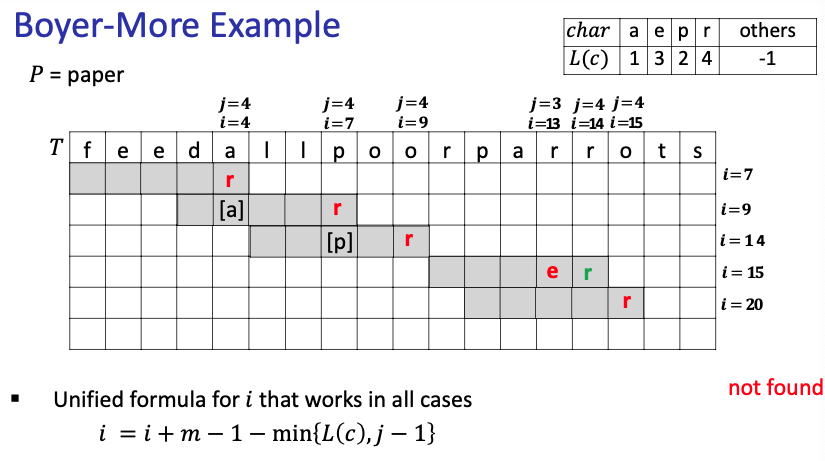
The gist is to start with the last letter of the pattern and try to match with . If, the letter we are matching does not appear in at all, we shift pass the letter, if we found a letter that doesn’t match, we align the guess until the letter in aligns with the letter in . If the letter appears twice in our , we shift the guess to align with the second occurrence in .

Note
Worst-case runtime to execute the Boyer-Moore algorithm, with only the bad character heuristic is .
Question: Is the best case when c is not found because we get to skip over the segment of length m? And is the worst case when , for , because we have to shift by 1 unit each time, where is the length of the string? Answer: For the best case, yes, it is because we move length of . With the worst, it may be a case that where we can only shift our guess by index of 1.
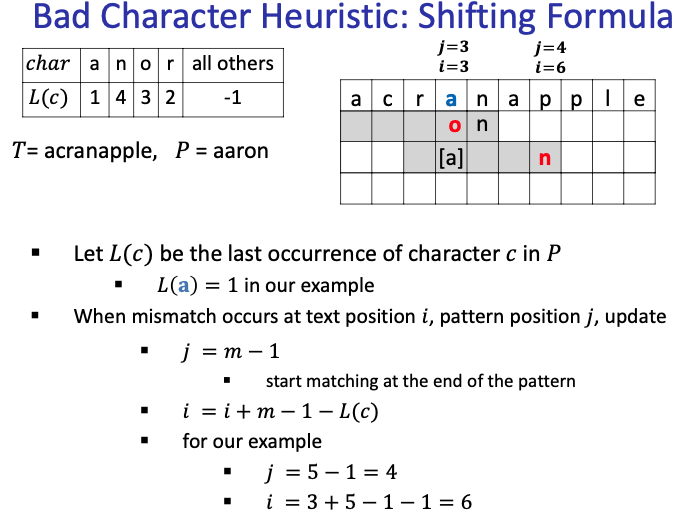 When
Remember:
When
Remember:
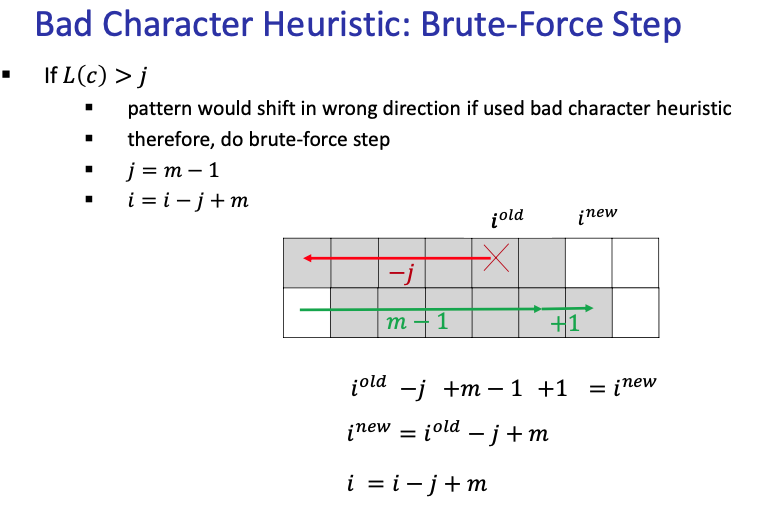
If , we use brute force step:

Pseudocode:

Example of Boyer-More:
Questions
- For the pattern , in the last-occurrence function , we have:
- Given a pattern of length and text of length , the worst-case runtime to execute the Boyer-Moore algorithm, with only the bad character heuristic is ?
- True. But why??? I thought it was . So the sum is to account for running over occurrence array. is there to account run-time to compute last occurrence array. is there as we may check all characters in sub-text and only can shift our guess by index of 1 (or something similar).!
- In the Boyer-Moore algorithm, its possible to shift pattern ahead characters with a single check.
- False, in the bad character heuristic, when mismatch occurs, it allows to shift the pattern to the rightmost occurrence of the mismatched character in the pattern is aligned with the mismatched character in the text. So it is less than .
- Suppose you are given a text of length and a pattern of length . What is the pre-processing time of the Boyer-Moore algorithm?
- To apply the bad character heuristic, we need to create a “bad character” table that records the rightmost occurrence of each character in the pattern. This preprocessing step takes time, where m is the length of the pattern P, and |Σ| is the size of the alphabet (the number of unique characters). In the worst case, |Σ| is a constant factor, so the bad character heuristic preprocessing takes O(m) time. In this case, it would be .
- Assume you are given a pattern of length and text of length and that any pre-processing steps have been completed. The best-case runtime of the Boyer-Moore algorithm when the pattern is not found in the text is:
- , but why??



