SE464: Software Design and Architectures
Taught by Weiyi Shang. A continuation of CS247. Not really, this class is a shit show… Spent a total of 8 hours studying for the final and maybe 3-5 hours each for the labs.
Concepts
- Load balancing
- CDN
- …
Final Exam
Final Breakdown:
- 20 MCQ - 1% each, 20% total
- 10 True and False - 1% each, 10% total
- 10 short answers - 20% total (don’t write too much, most of his answers are about 2 sentences)
- 4 long answer questions - 50% total. These are calculations and design questions.
- Need a calculator!
Thoughts:
- I wish this course was taught better, or designed better. Didn’t care about it at all. Some labs were quite interesting since it’s letting us use the actual technology that are used in the industries.
- It has so much potential but the prof likes to go over a wide range of topics without going into details.
- By far the worst course we have to take in 3B.
Study Activity 1
- Metrics, logs and traces
- Multi-layer persistence
- Load Shedding and Graceful Degradation
- quality properties of software that are important from a customer’s perspective?
- durability, reliability, latency
Review
Given an architecture, what can we do?
- add load balancers
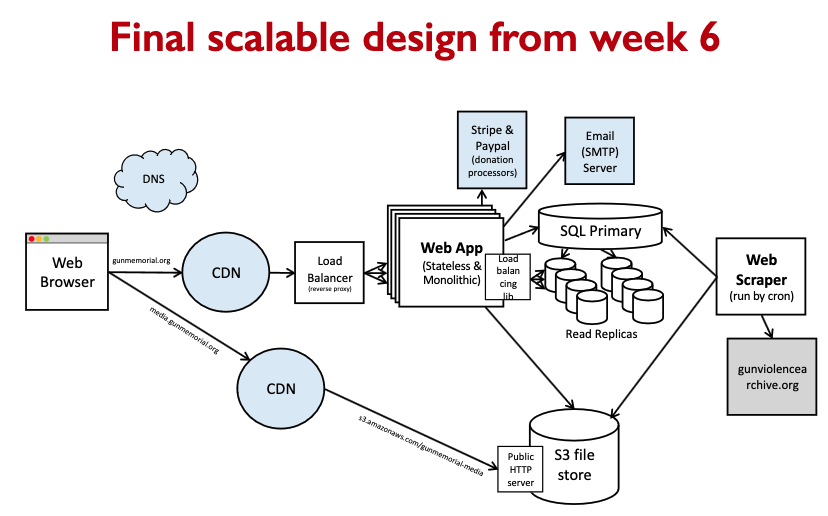
Choosing between similar architecture styles/approaches
- select most appropriate:
- publish/subscribe vs. implicit invocation
- stream vs batch
- Repository
- Pipe and Filter
- Object-oriented
- Layered
- Interpreter
- Process-control
- Client/Server
- Peer-to-peer
- Leader-follower
Queues:
M/M/3/20/1500/FCFS denotes a single-queue system with the following parameters:
- The time between successive arrivals is exponentially distributed
- The service times are exponentially distributed
- There are three servers
- The queue has buffers for 20 jobs. This consists of three places for jobs being served and 17 buffers for jobs waiting for service. After the number of jobs reaches 20, all arriving jobs are lost until the queue size decreases
- There is a total of 1500 jobs that can be serviced
- The service discipline is first come, first served
Equations
- Workload intensity
- Arrival rate:
- Service requirements
- Mean service time:
We then calculate the following average values:
- Throughput:
- Utilization: (Utilization Law)
- Residence time: (See proof later)
- Queue length: (Little’s Law)

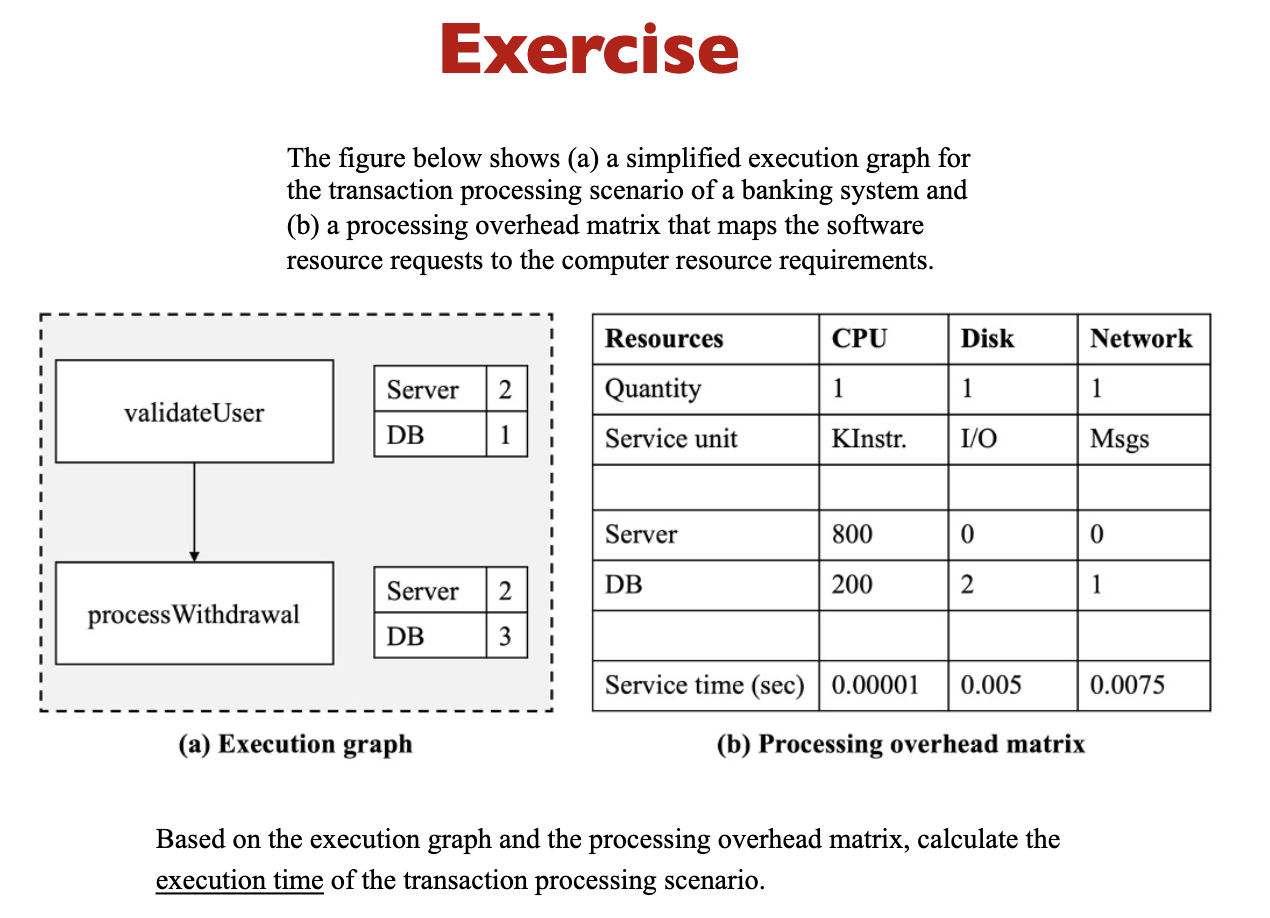






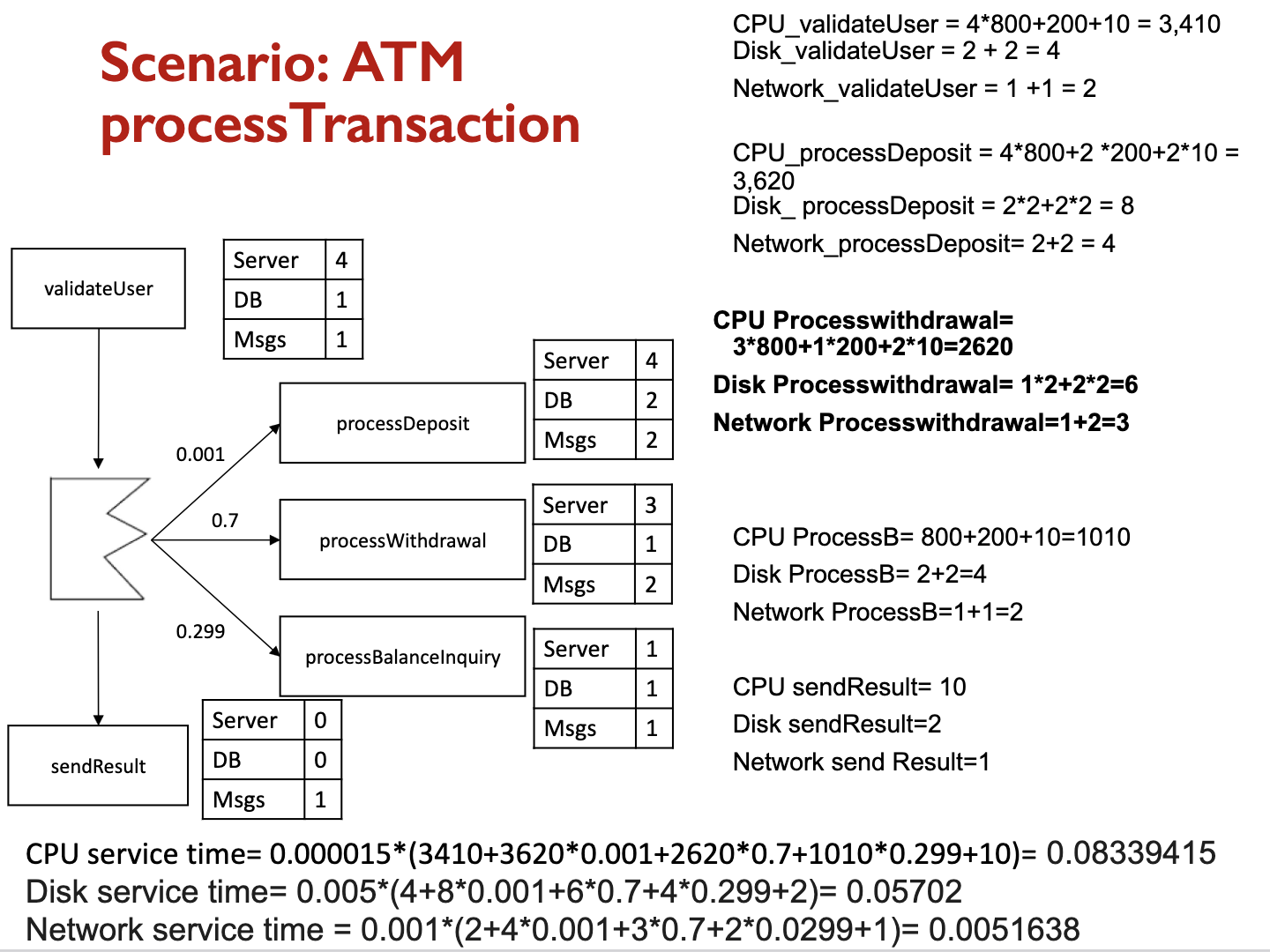
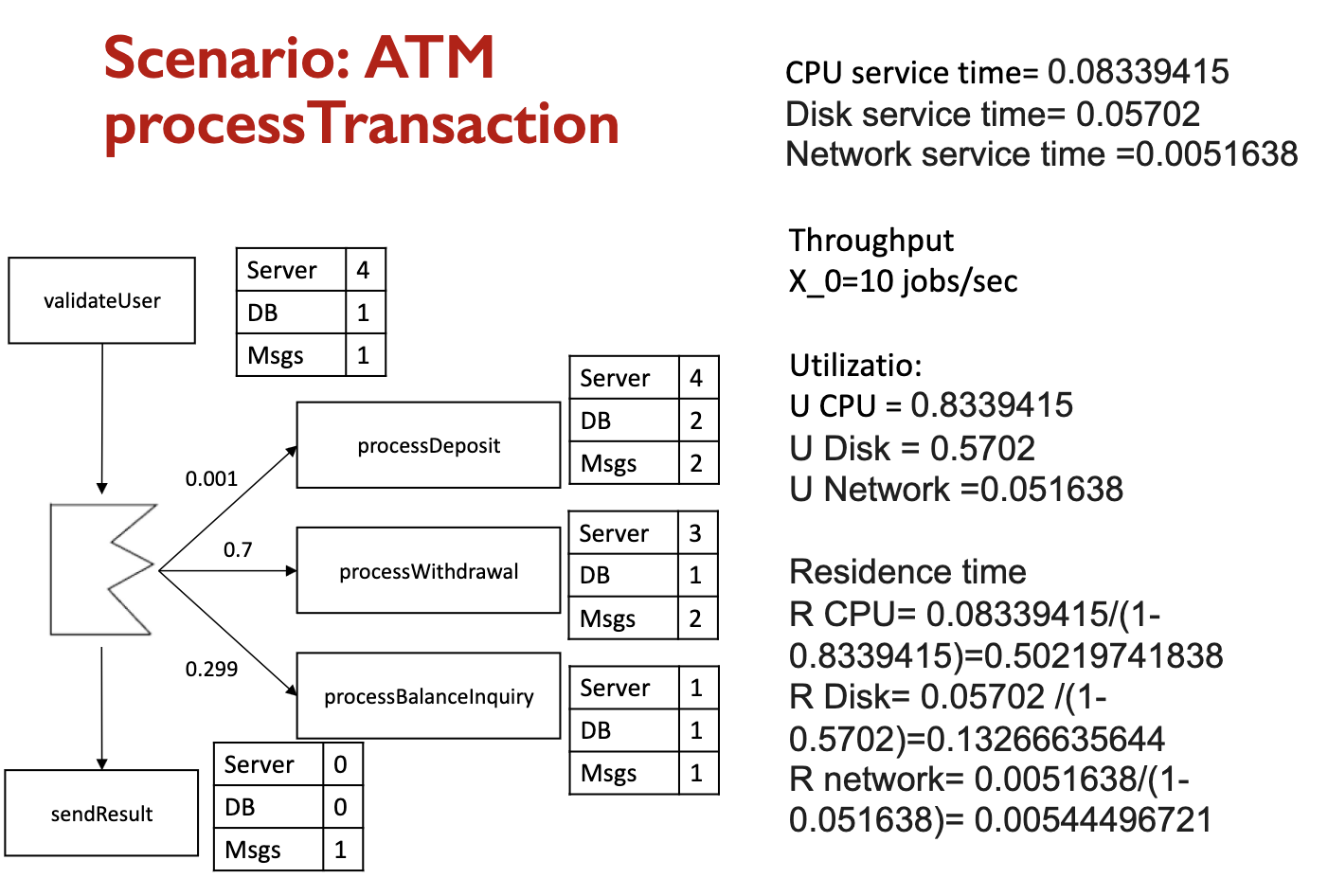
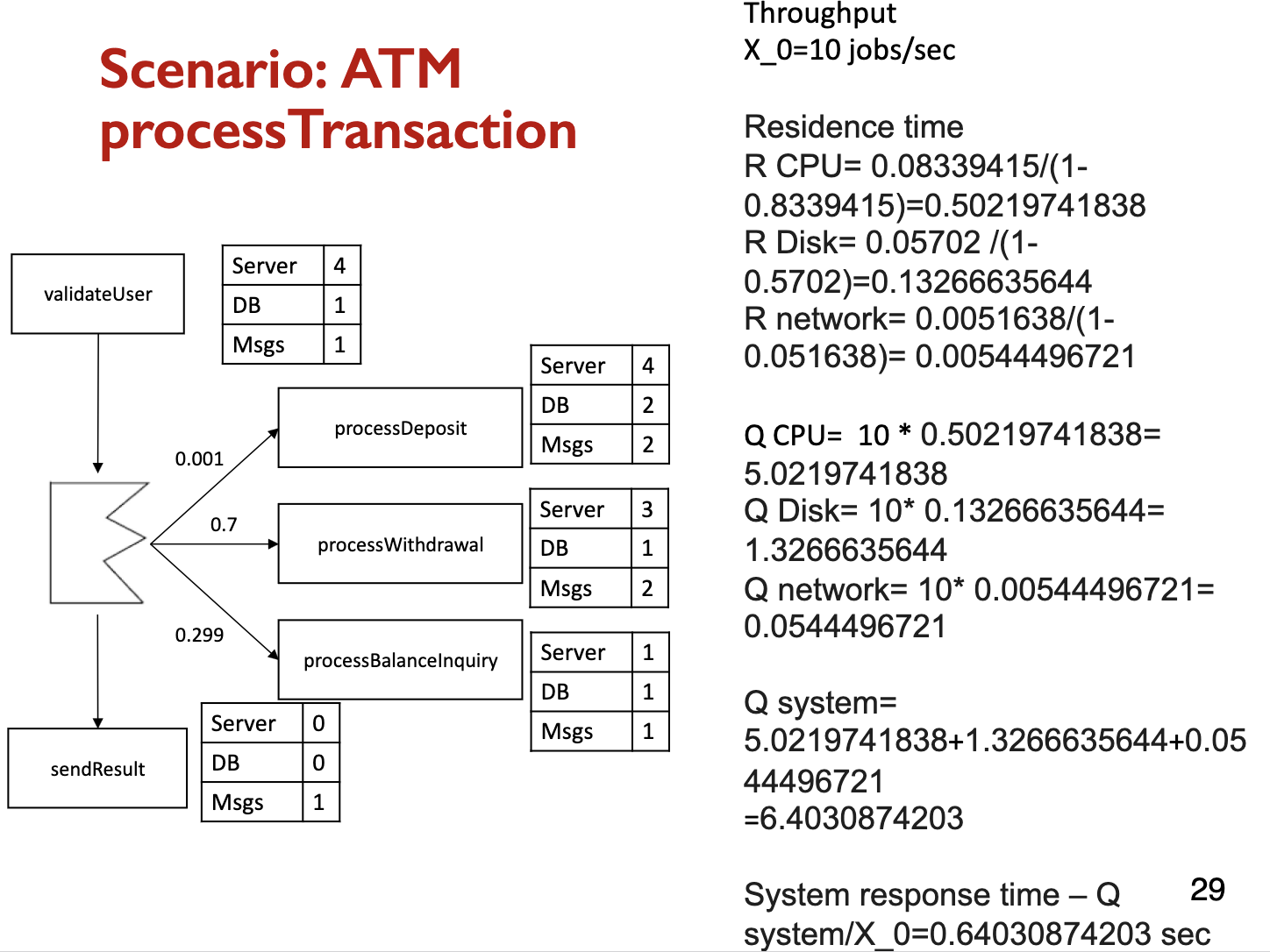
Questions:
- Vertical vs. Horizontal Scaling?
- Explain how cookies help maintain state in a stateless HTTP service
- Cookies store session-specific data on the client. When client send request, the cookie is included, allowing the server to recognize the sessions without maintaining server-side state.
- Any other way to maintain states?
- DB
- What’s CAP theorem in distributed DB?
- The CAP theorem states that a distributed system can only achieve two out of three properties: consistency, availability, and partition tolerance. This means that when a network partition occurs, the system must choose between serving all requests (availability) or ensuring data consistency
- Why are SQL databases considered less scalable compared to NoSQL databases?
- SQL databases rely on a single master for writes, making horizontal scaling challenging. Additionally, Joins and strict schemas limit partitioning flexibility.
- The choice between SQL and NoSQL databases largely depends on the specific requirements of the application. SQL databases are preferred where the reliability and integrity of data are paramount, and complex relationships need to be efficiently managed. NoSQL databases are favoured for their flexibility, scalability, and performance in applications where the data model can vary or where rapid development is required.
- Give an example of when you would choose ElasticSearch over a relational database.
- ElasticSearch is preferable for applications requiring full-text search or advanced queries over unstructured or semi-structured text, such as searching a collection of news articles by keywords.
- Explain the difference between functional partitioning and data partitioning (sharding).
- Functional partitioning separates entire tables based on their purpose, while sharding (data partitioning) divides rows of a table across multiple databases based on a sharding key.
- What are two advantages of sharding a relational database?
- Improved performance for queries that involve only a single shard
- Increased capacity by distributing data across multiple machines
- What is the purpose of read replicas in database scaling?
- Read replicas handles read-only queries to reduce the load on the primary database and improve scalability for read-heavy workloads
- Read replicas are a common scaling technique used in database management systems to handle large volumes of read-only traffic efficiently. They involve creating one or more copies of the primary database, and these replicas synchronize continuously with the primary database to reflect the most up-to-date data.
- What challenges arise when using sharding in relational databases?
- Adapting queries to the sharding design,
- maintaining balance among shards,
- and handling queries that require data from multiple shards.
- How does DNS-based load balancing achieve geographic load balancing?
- DNS servers resolve domain names to IP addresses of the closest server, often using geolocation to determine proximity.
- When a user attempts to access a service (like a website), their device sends a DNS query to resolve the domain name into an IP address. DNS-based load balancing systems use geolocation data to determine the physical location of the user making the request.
- The DNS server then responds to the query with the IP address of a server that is geographically closest to the user. This proximity generally translates into faster response times and reduced latency.
- DNS servers resolve domain names to IP addresses of the closest server, often using geolocation to determine proximity.
- What is additional benefit of using a reverse proxy load balancer?
- caching to reduce backend load → see Benefits of Caching in a Reverse Proxy
- What is the main purpose of a CDN, and how does it relate to Load balancing?
- A CDN caches HTTP responses on globally distributed servers and uses DNS-based load balancing to direct users to the nearest edge server for low latency.
- Explain why POST is not considered idempotent in REST APIs
- POST creates new resources, so repeating the request results in duplicate resources being created
- Why are push notifications considered more effective than email for real-time app updates?
- Push notifications can directly interact with the app and provide real-time updates, even if the app is not running.
- What challenges arise when trying to deliver push notifications to a client behind NAT or firewalls?
- Maintaining a long-lived connection requires the client to send periodic keepalive messages, and routing must account for changing IP addresses.
- because these security measures can prevent the direct connection necessary for real-time communications. To maintain a connection, the client must periodically send keepalive messages to keep the connection open.
- How does modern push notification services like APN (Apple Push Notifications) and GCM (Google Cloud Messaging) solve the issue of app-specific connections?
- They consolidate connections by allowing the Operating System to maintain a single connection for all apps, reducing overhead and complexity.
- This approach simplifies development and maintenance for app developers. Developers only need to integrate their apps with the respective service (APN for iOS and FCM for Android) without worrying about complexities.
- What are the trade-offs between tightly coupled (synchronous) and loosely coupled (asynchronous) services?
- Synchronous services are simpler to design but can cause bottlenecks, while asynchronous services improve scalability but complicate error handling and result tracking.
- Developers need to implement additional mechanisms to handle these aspects, such as callbacks, promises, or message queues, which can complicate the system’s architecture…
- Since synchronous services require responses before proceeding, they can create bottlenecks.
- Synchronous services are simpler to design but can cause bottlenecks, while asynchronous services improve scalability but complicate error handling and result tracking.
- How do message queues help in scaling a system?
- Queues decouple Producers and consumers, allowing each to scale independently. They also smooth demand peaks and prevent upstream services from being overloaded.
- Message queues act as an intermediary layer that separates the producers of data from the consumers. This decoupling means that producers and consumers do not need to interact directly or be online at the same time, allowing each to operate and scale independently.
- Queues can absorb sudden spikes in demand by storing messages until consumers are ready to process them. This capability helps prevent overload situations where the consumer services might otherwise be overwhelmed by a high volume of incoming data or requests at once.
- Queues decouple Producers and consumers, allowing each to scale independently. They also smooth demand peaks and prevent upstream services from being overloaded.
- How does a “request record” help clients track the status of asynchronous requests?
- The server stores the status of the request in a database, and the client can query the server later using a unique request ID.
- What are the 3 questions that should be answered before performing a requested action in the guard model?
- Authenticity (is the identity authentic?),
- Integrity (is the request untampered?),
- Authorization (is the agent allowed to perform the action?).
- guard model for security, which is used to ensure that system interactions are secure and valid!
- What are the 3 broad categories of security threats?
- Unauthorized information release
- disclosure of information without permission, breach of confidentiality
- unauthorized information modification
- tampering, altered without permission
- unauthorized denial of use
- threat involves preventing legitimate users from accessing
- Unauthorized information release
- What is the “fail-safe default” principle important in security design?
- It ensures that access is denied unless explicitly permitted, preventing unauthorized actions when system errors occur.
- concept of defaulting to the most secure state during any system failure or anomaly
- It ensures that access is denied unless explicitly permitted, preventing unauthorized actions when system errors occur.
- How does an API Gateway reduce the attack surface in microservices?
- It exposes only necessary endpoints to external clients, limiting access to sensitive internal services.
- What are the primary components and connectors in the repository style?
- The components are independent modules operating on a central data structures, and the connectors are typically procedure calls or direct memory accesses.
- The repository architectural style is characterized by the presence of a central data structure or database, known as the repository, which stores shared data and is accessible by various components of the system. This design allows multiple applications or services to work independently while sharing the same data set
- The components are independent modules operating on a central data structures, and the connectors are typically procedure calls or direct memory accesses.
- What is the main difference between batch and stream processing in terms of latency?
- Batch processing has high latency as it processes data in chunks over time, while stream processing has low latency and processes data in real time.
- How does implicit invocation differ from traditional procedure calls?
- In implicit invocation, components announce events without knowing which components will respond, while traditional procedure calls directly invoke specific functions.