SE350: Operating Systems
Everything is on Learn. Taught by Sebastian Fishmaster. His github: https://github.com/sfischme/suspendme
Resources:
- https://github.com/smajidzahedi/SE350 Fishcmeister uses different slides though
- UC Berkeley exam bank: https://inst.eecs.berkeley.edu/~cs162/su20/static/exams/
Course format:
- 1 final
- 4 quizzes
- Labs: 3 deliverables
Also see Real-Time Operating System.
Final
Chapter 1 - 10
- Chapter 1 “Computer System Overview”: 1.1 up to including 1.8
- Chapter 2 “Operating System Overview”: 2.1 up to including 2.6
- Chapter 3 “Process Description and Control”: 3.1 up to including 3.3
- Chapter 4 “Threads”: 4.1 up to including 4.3
- Chapter 5: “Concurrency: Mutual Exclusion and Synchronization”: 5.1 up to including 5.7
- Chapter 6: “Concurrency: Deadlock and Starvation: 6.1 up to including 6.6
- Chapter 7: “Memory Management: 7.1 up to including 7.4
- Chapter 8: “Virtual Memory: 8.1 up to including 8.2
- Chapter 9: “Uniprocessor Scheduling”: 9.1 up to including 9.3
- Chapter 10: “Multiprocessor, Multicore, and Real-time Scheduling”: 10.1 up to including 10.2 but excluding Priority Inversion
- Chapter 11: “I/O Management and Disk Scheduling”: 11.1 up to including 11.7 (excluding 11.6 RAID)
- Chapter 12: “File Management”: 12.1 up to including 12.7
- No question on RAID (11.6)
- No question on readers/writers problem (5.7)
Thoughts on final (04-27-2024):
- Relatively easy, thank god I gambled and didn’t study semaphores
- Clock policy asked
- Disk Scheduling Policies asked
- File system easy question
- Deadlock, livelock, mutual exclusion type of question, similar to quizzes
- Multiprocessor, multithreading
- Pretty similar questions to quizzes
Quizzes
Quiz 1
- forgot a bit on PCB, only got partial marks
- Even though I got to the right answer for the last question, TA said something like to find the maximum of instructions used by the dispatcher you should allocate 1 instruction for a process.
Quiz 2
- Didn’t have time to finish the last question
- Kernel-level what? Need to look into it
- Turns out I got that question right, because I had a different copy.
- Review to make sure I understand
- Review on deadlock and livelock. (lost marks)
- Deadlock didn’t exist because no infinite loop
- livelock did not happen because both couldn’t have had the same value
- What’s the difference between deadlock and livelock?
- You sell a single-process, single multi-threaded application for a multi-processor system using a single-programming OS with kernel-level threading and concurrency support using binary semaphores. Your CTO claims that migrating your highly parallelizeable, mixed IO&CPU-use application to multiple threads will make the application run at least 20% faster on the same hardware. Provide exactly one technically-founded argument related to material covered in this course whether this is or is not believable (Note: More than one argument will result in zero points)
- Since we are using multiple threads, then we will have a single-process, multiple-threaded application. Therefore, in this one application that has a single process, it could run multiple threads which will make it faster. The reason being it does not have to switch between processes and pass through the kernel. Threads could switch between each other without involving the kernel. Thus, improving the speed.
- In at most two sentences, explain why system calls often need to execute in kernel mode.
- System calls need to be more often executed in kernel mode since it accesses some sensitive information that you don’t want the user to modify and have access to.
- Look at the example code below and explain whether the following statements are true or false: (1) mutual exclusion is achieved, (2) deadlocks can occur, (3) livelocks can occur. The critical section contains no bugs and no loops. The array
flag[]is initialized withfalse.
/* Process P1 executes the following in an infinite loop */
while (flag[1] == true ) { /* do nothing */}
flag[0] = true;
/* critical section */
flag[0] = false;
/* Process P2 executes the following in an infinite loop */
while (flag[0] == true) {/* do nothing */ }
flag[1] = true;
/* critical section */
flag[1] = false;
- Mutual exclusion is not achieved
- Deadlocks doesn’t occur
- Livelocks cannot occur
- They asked user thread level advantages over kernel thread level.
- Static partitioning with 4 parts, and give an example when you allocate, but can’t anymore even if there would be enough place with dynamic compaction
- LRU Replacement Algorithm
- Overall easier than expected. Should be happy enough with my grand total of 2-3 hours of studying. Got side tracked by Beartown and Dune.
- Update: got full marks. It was fairly simple. Hopefully the final is like that.
Quiz 4
- Chapter 6: 6.4 up to including 6.6
- Chapter 7: 7.1 up to including 7.4
- Chapter 8: 8.1 up to including 8.2
- Chapter 9: 9.1 up to including 9.3
- Chapter 10: 10.1 up to including 10.2 but excluding Priority Inversions
- No question related to queuing theory
I guess focus on Chapter 8, 9 and 10. Virtual memory, uniprocessor scheduling and multiprocessor, multicore and real-time scheduling.
Labs
Full marks on the labs, thanks for Emre for the carry: SE350 Labs
Concepts
Chapter 1
Chapter 2
Chapter 3
- Two-State Model
- Five-State Model
- Process Table
- Process Image
- Process Control Block
- Trap (OS)
- Supervisor Call Instruction
- System Call
- Exception Handling (OS)
- Execution of Operating System
Chapter 4
- Multithreading
- Thread Functionality
- Microkernel Architecture
- Microkernel
- User-Level Thread
Chapter 5 - Chapters 5 and 6 deal with concurrency in multiprogramming and multiprocessing systems.
- Concurrency
- Interaction Among Processes
- Race Condition
- Mutual Exclusion
- Semaphore
- Producer and Consumer Problem
- Semaphore
- Monitors (SE350)
- Message Passing
- Reader-Writers Problem
Chapter 6
- Deadlock
- Starvation
- Livelock
- Need to review 6.4 Deadlock Detection!
- Review 6.6 Dining Philosophers Problem!
- Also 6.7 UNIX concurrency mechanisms
Chapter 7
- Logical Organization
- Physical Organization
- Memory Partitioning
- Fixed Partitioning
- Dynamic Partitioning
- Placement Algorithm
- Best-fit - less internal segmentation (worse performer)
- First-fit - simple
- Next-fit - fast
- External Fragmentation
- Internal Fragmentation
- Replacement Algorithm
- Buddy System
- Paging
- Segmentation
Chapter 8
Chapter 9
Read the Book!
Book is divided into 5 parts
- Background
- Processes
- Memory
- Scheduling
- Advanced topics (embedded OSs, virtual machines, OS security, and distributed systems)
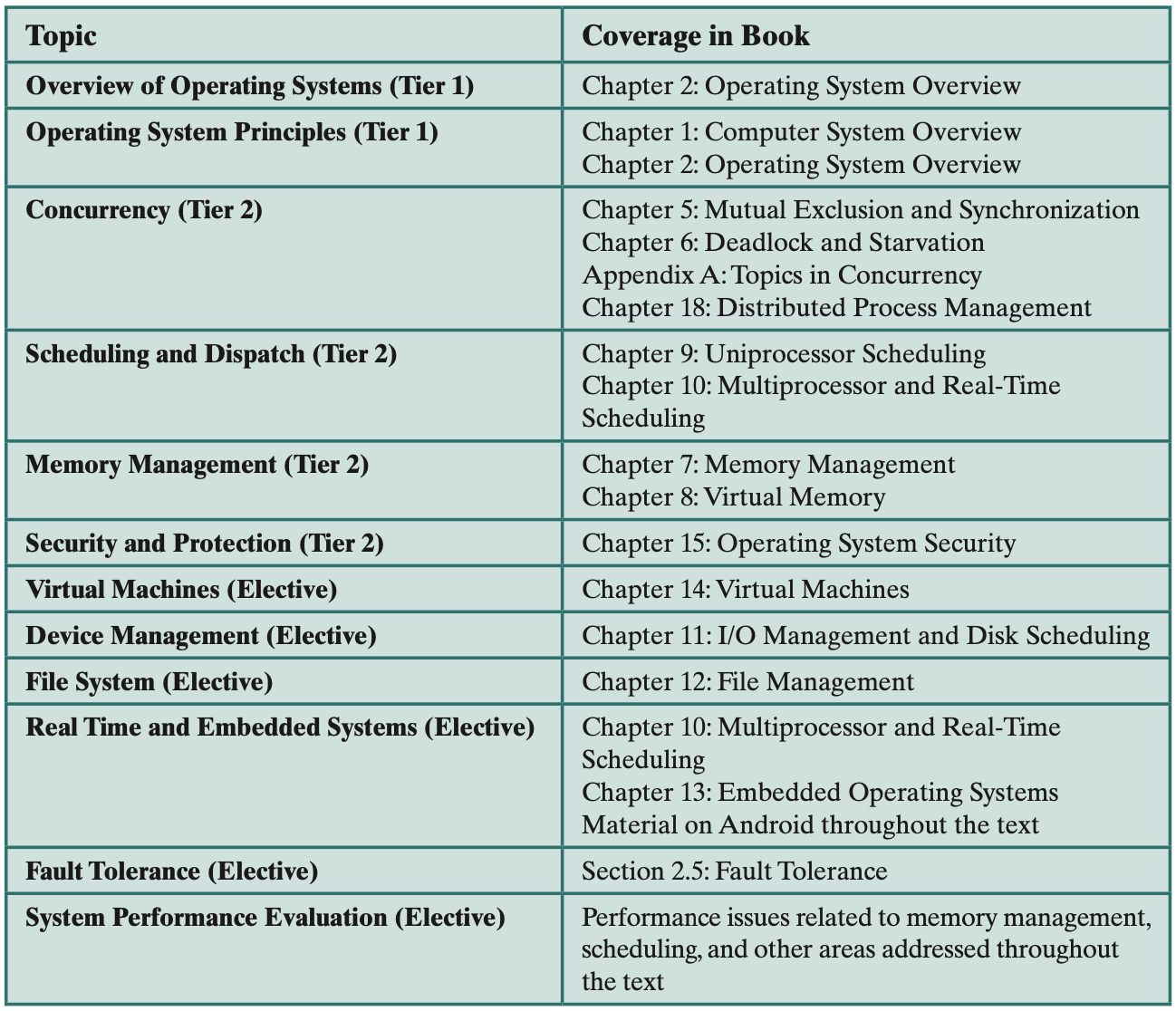
Chapter 1
What is an Operating System?
Main structural elements of a computer:
Chapter 2
Major achievements:
- Processes
- Memory Management
- Information protection and security
- Scheduling and resource management
- System structure
- (Virtualization)
- Kernel
- Fault Tolerance
Chapter 3
How Does the OS Manage Processes
Process Creation and termination.
Example:
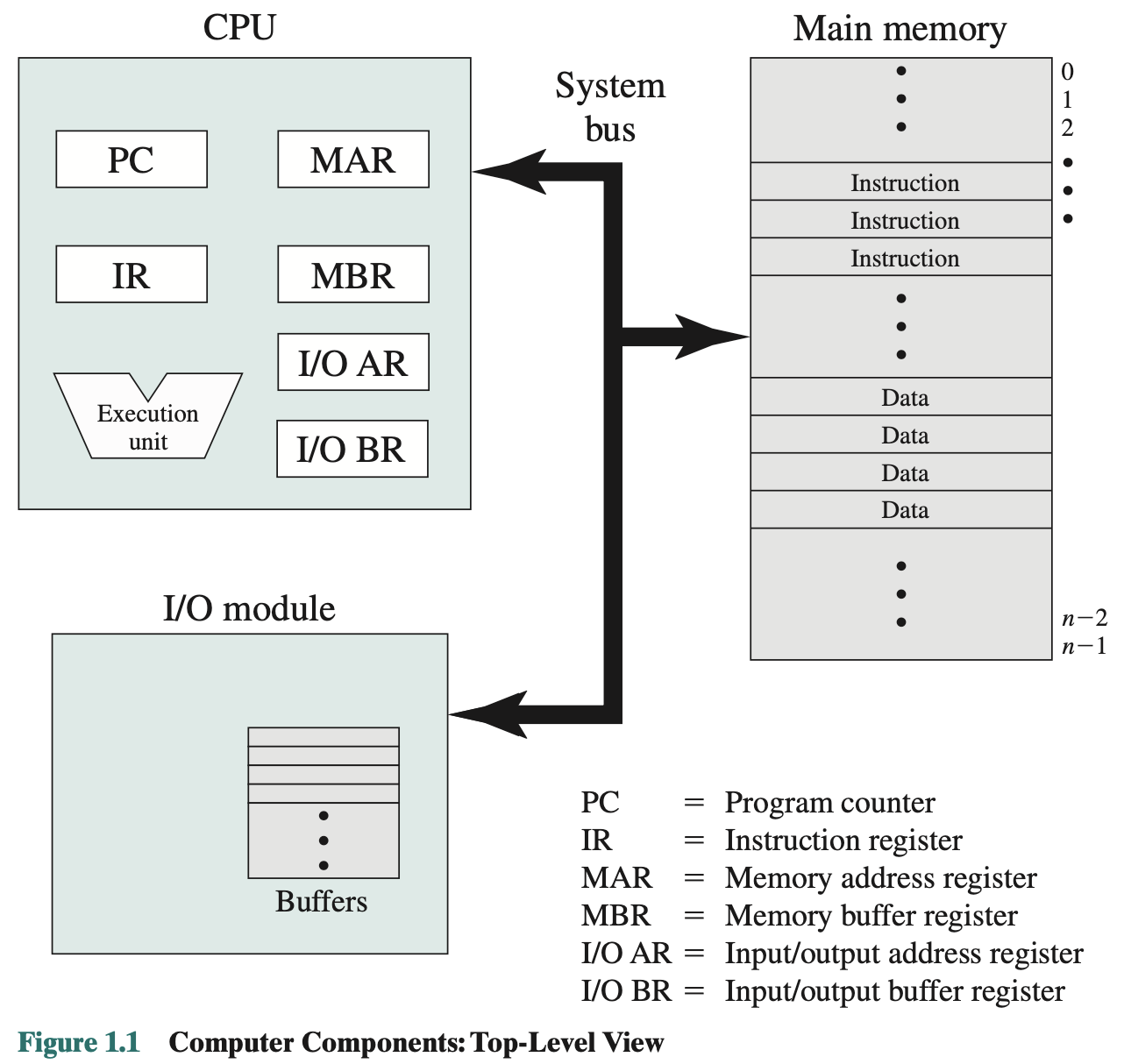
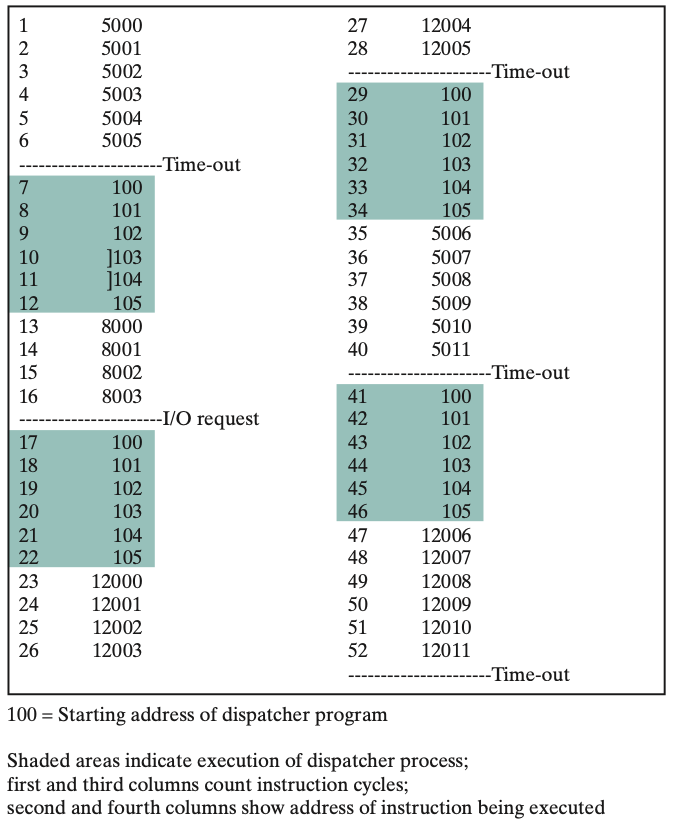
Assume no virtual memory, all three processes are represented by programs that are fully loaded in main memory. There is a small Dispatcher program that switches the processor from one process to another. First 12 instructions executed in processes A and C are shown. Process B executes 4 instructions and we assume that the fourth instruction invokes an I/O operation for which the process must wait.
Processor’s point of view (Figure 3.4): Interleaved traces resulting from the first 52 instruction cycles (instruction cycles are numbered). The shaded areas represent code executed by the dispatcher. We assume that the OS only allows a process to continue execution for a maximum of six instruction cycles, after which it is interrupted; this prevents any single process from monopolizing processor time. Figure 3.4 shows, the first six instructions of process A are executed, followed by a time-out and the execution of some code in the dispatcher, which executes six instructions before turning control to process B. After four instructions are executed, process B requests an I/O action for which it must wait. Therefore, the processor stops executing process B and moves on, via the dispatcher, to process C. After a time-out, the processor moves back to process A. When this process times out, process B is still waiting for the I/O operation to complete, so the dispatcher moves on to process C again.
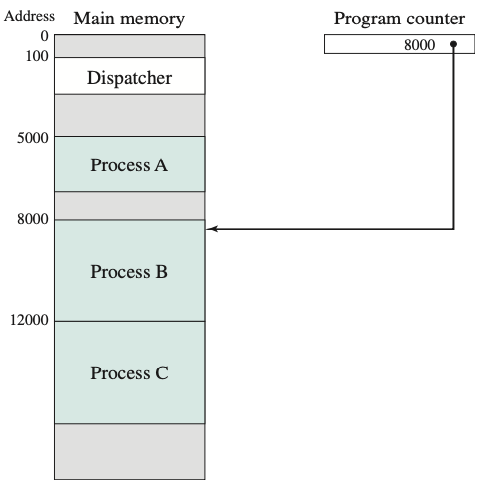
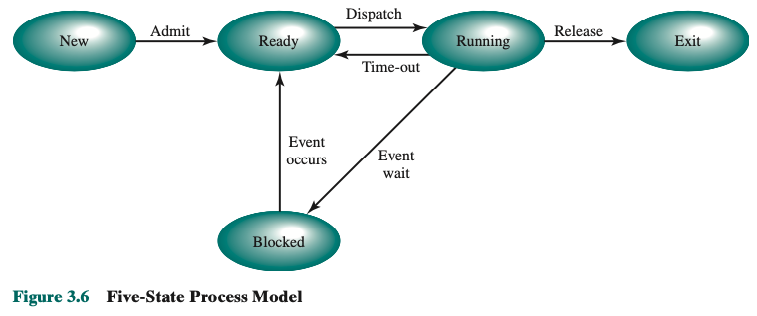
Introduce a Two-State Process Model
Process Creation: When a new process is to be added to those being currently managed,, the OS builds the data structures that are used to manage the process and allocates address space in main memory to the process.
Process Termination:
- Halt instruction
- User terminates a program
- Error and fault conditions
Introduce a Five-State Model.
Split the Not Running state into two states: Ready and Blocked.
We now have 5 states:
- Running
- Ready
- Blocked/Waiting
- New
- Exit

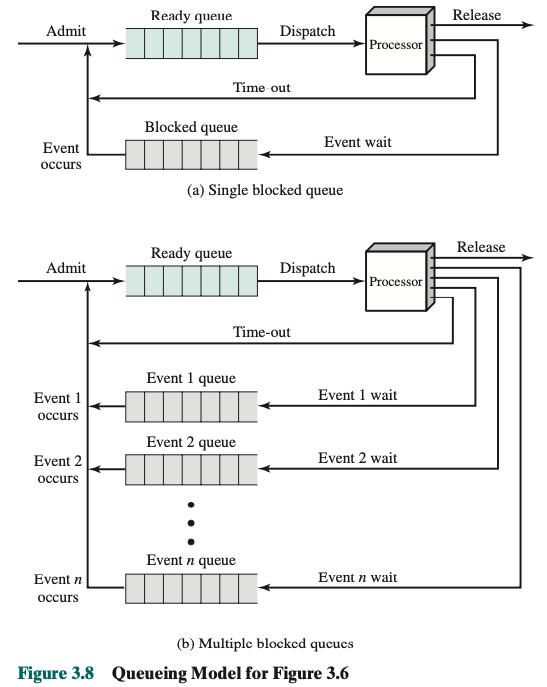
Upgrade schema
Todo…
Steps in Process Creation
- Assign a unique process identifier
- Allocate space for the process
- Initialize process control block
- Set up appropriate linkages
- Ex: add new process to linked list used for scheduling queue
- Create of expand other data structures
- Ex: maintain an accounting file
Possible choices when to switch
- Clock interrupt
- process has executed for the maximum allowable time slice
- I/O interrupt (= I/O complete)
- Memory fault
- memory address is in virtual memory so it must be brought into main memory
- cannot access the memory rn
- Trap
- Supervisor Call
Why would we want to switch task when we have a memory fault?
Steps for a process switch
- Save context of processor including program counter and other registers
- Update the process control block of the process that is currently in the Running state
- Move process control block to appropriate queue read; blocked; ready/sustpend
- Select another process for execution
- Update the PCB of the process selected
- Update memory-management data structures
- Restore context of the selected process
Change of Process State
- Update the PCB of the process selected
- Update memory-management data structures
- Restore context of the selected process
Similar to an interrupt!
_sched, Part 1
- Use
call PostTaskHookeasier to debug in our system.
Execution of the OS
Exception Handling
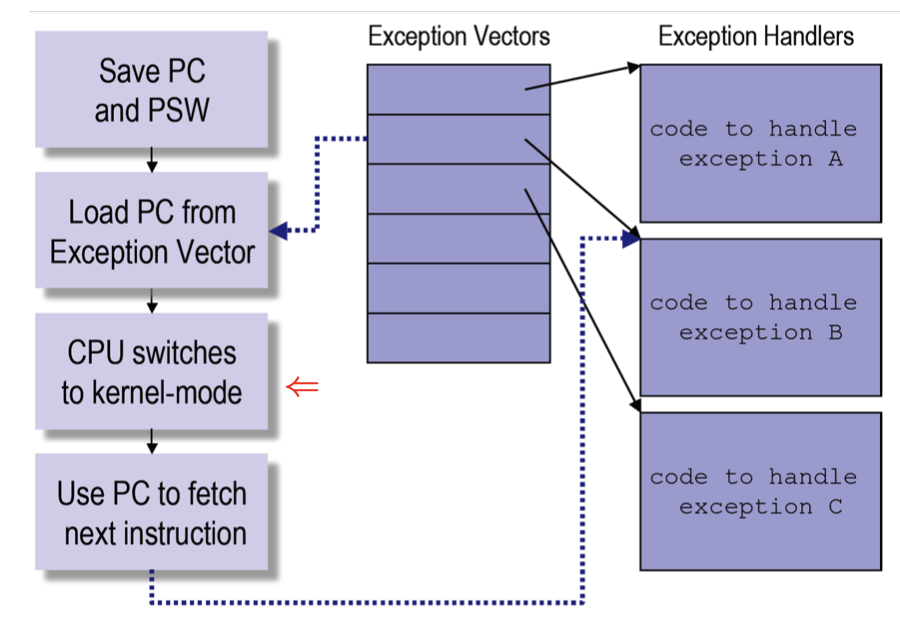
User Exception Handling
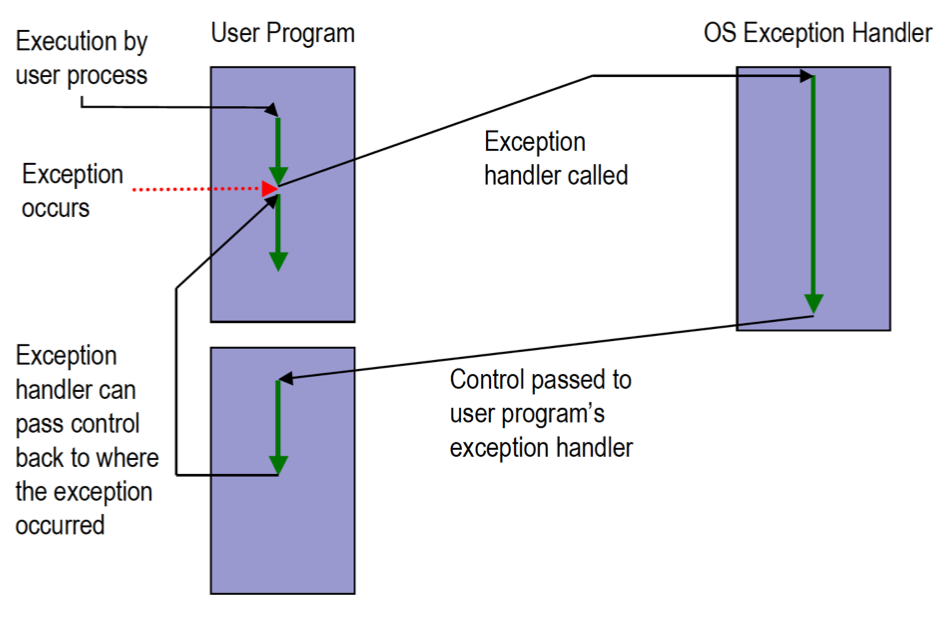 There are two different exception, external and internal.
There are two different exception, external and internal.
Processing a System Call
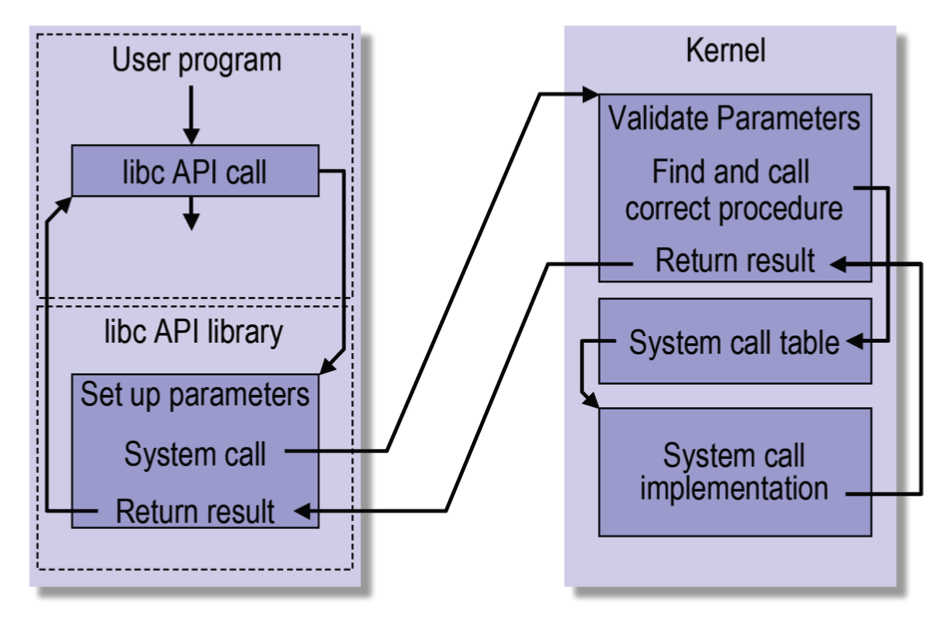
How do you move from the system call to the kernel?
Steps in Making a System Call
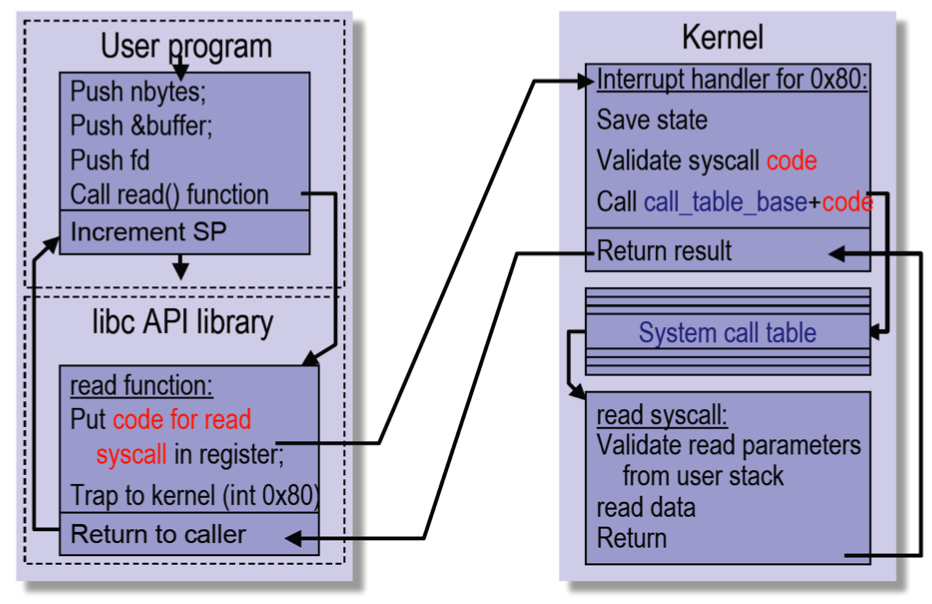
Push onto the stack. And read it from the kernel.
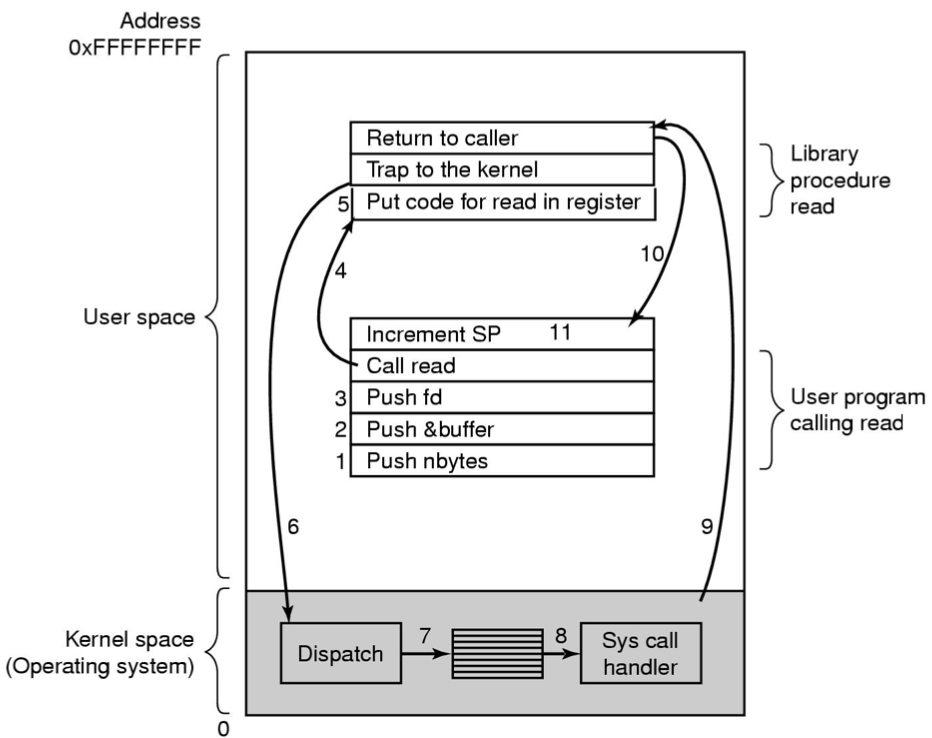
Look up how to call assembly routines from c. → Explained in a lot of details.
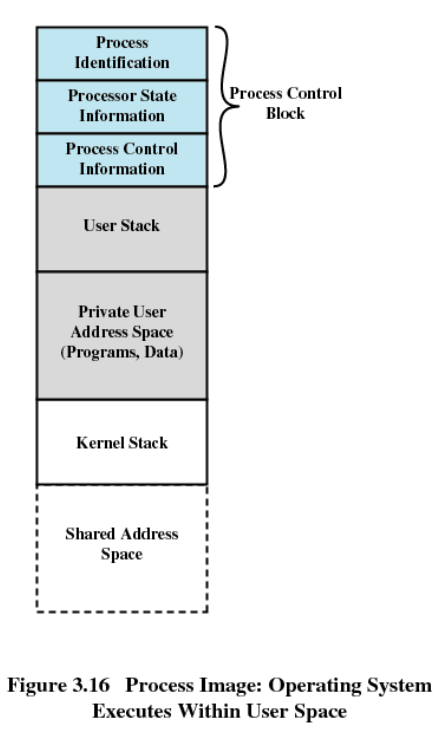
Why do we need a kernel stack in the Process image?
- The process image needs to store the kernel stack separately from the user stack because we might want to keep things hidden from the user.
- Safer, because we can make this region not accessible to the user, since it’s only used for user calls.
Chapter 4
When you terminate a process, it automatically suspends and terminates all threads within that process.
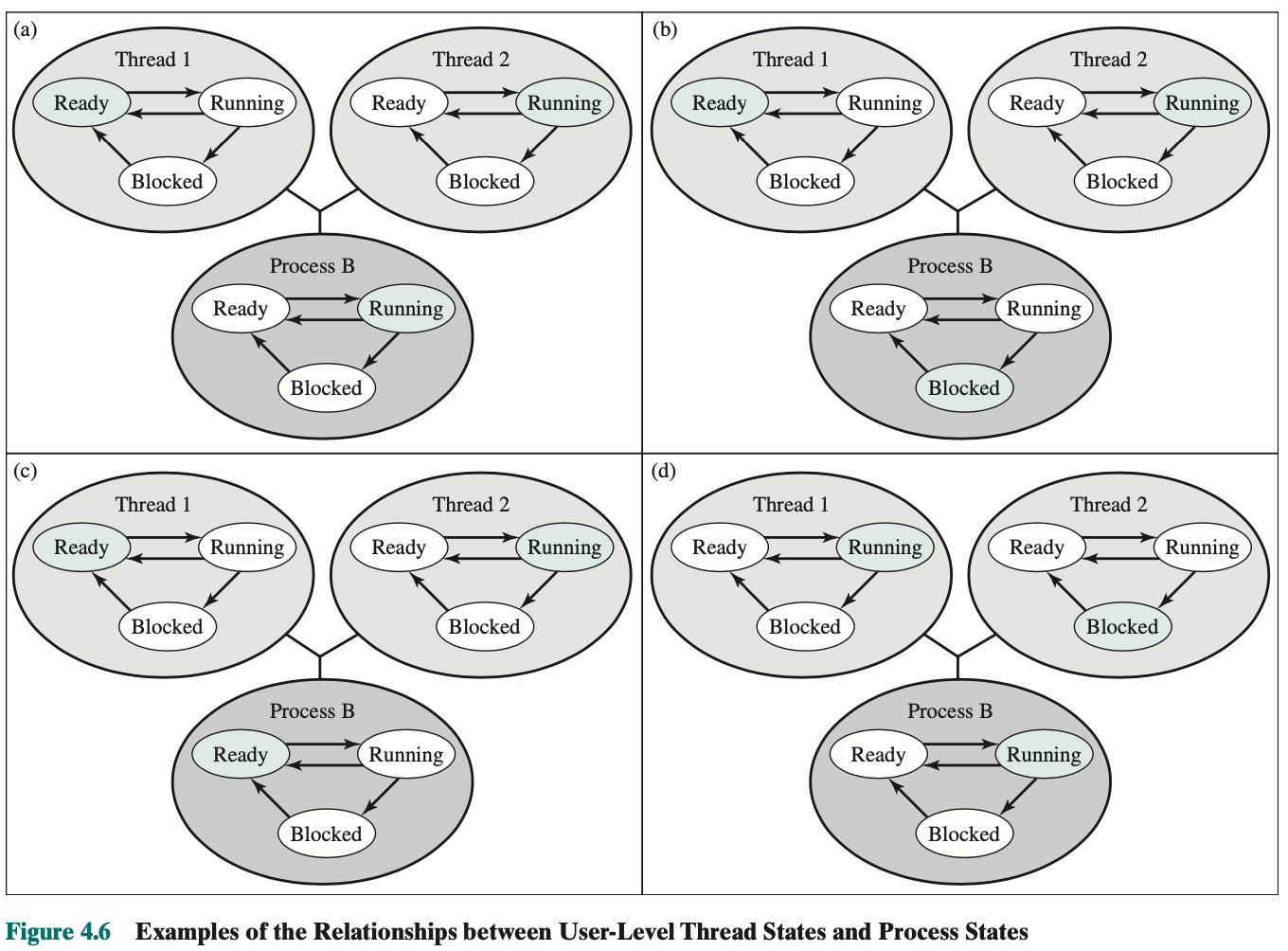 a)
b) Thread too made request to block, and the OS blocked the whole process. When the kernel switches control back to process B, execution resumes in thread 2.
c) OS decided to remove process B from the processor, the threads
d) process can still running, but thread 2 is blocked on an output???
a)
b) Thread too made request to block, and the OS blocked the whole process. When the kernel switches control back to process B, execution resumes in thread 2.
c) OS decided to remove process B from the processor, the threads
d) process can still running, but thread 2 is blocked on an output???
Look at textbook to undrestand
Demo: lsmod
Lecture 5

the incrementation of the semaphore needs to be protected and the access to the queue also. semWaitB
Review
What do we need to implement semaphores?
When does a semaphore gets blocked?
When the value is less than or equal to 0 at the start of semWait().
Can a semaphore get a negative value?
Yes, when we have a queue.
If semaphores are used to protect code sections; what does the initial number control?
.. what does the current value indicate?
Positive value, how many processes es can allow processes in. = 0 critical section full, less than 0 processes are waiting to enter.
Mon Feb 5, 2024 p38 - p41 look at the textbook
Program 5.9 will crush.
consume() // if consume takes long, the n == 0 might not be representative of the n-- that is being decremented earlier
if(n==0)
Fix by introducing a local variable. For the consumer so the global variable does not affect the local variable. Figure 5.10
Figure 5.13: Infinite buffer. n control how many items on the shelf.to-understand
Number to control to the using semaphores to control it.
Consumer are producers of empty spots. Producer are creators of full spots semSignal(n). For example, the consumer has semWait(n) in the while loop, it waits on the consumer to provide some spots.
Isn’t there a deadlock over here? But there is not. Why? Answer: We initialize e to the size of the buffer. If you initialize it to 0, so initially there is no spots and no n is cakes, no cake at the beginning. e is the number of spots
Different way to synchronize: Monitors You can only enter the monitor if you call a specific function. (only get through the controlled entry)
Java implements monitors to ensure on thread entering method during multithreading. With the keyword synchronized
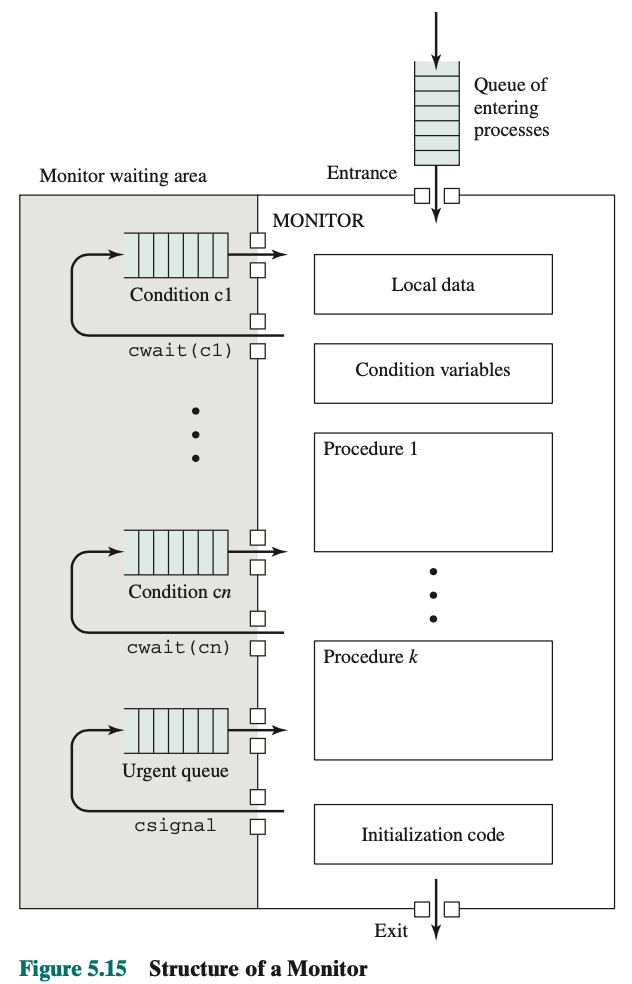
p.230 is the implementation. Notice the consumer and producer is very simple. Put all the complexity in the function taking and appending.
cwait() gets a signal that is not full, if one of them gets a signal, they immediately execute.
You need to have tight control of the scheduling of processing.
Introduce the Mesa Monitor (while loop).
He rarely tests monitors
Semaphores and messages.
Message Passing Useful so the processes can interact with each other, by sending and receiving messages.
- Sender and receiver may or may not be blocking (waiting for message)
- Blocking send, blocking receive
- Both sender and receiver are blocked until message is delivered
- Called a rendezvous (you have the baker send the cake, and wait until cats takes the cake and accepts it. Baker doesn’t do anything else befor ethe cat comes and takes the take. If cat comes at the place and waits for the baker to produce the cake)
- Nonblocking send, blocking receive
- Sender continues on
- Receiver is blocked until the requested message arrives
- e.g. any kind of service where you do not wait for a repsonse is in this area
- Nonblocking send, nonblocking receive
- Neither party is required to wait
How to address data you send in your system?
- Direct addressing
- Send primitive includes a specific identifier of the destination process
- Receive primitive could know ahead of time from which process a message is expected
- Receive primitive could use source parameter to return a value when the receive operation has been performed
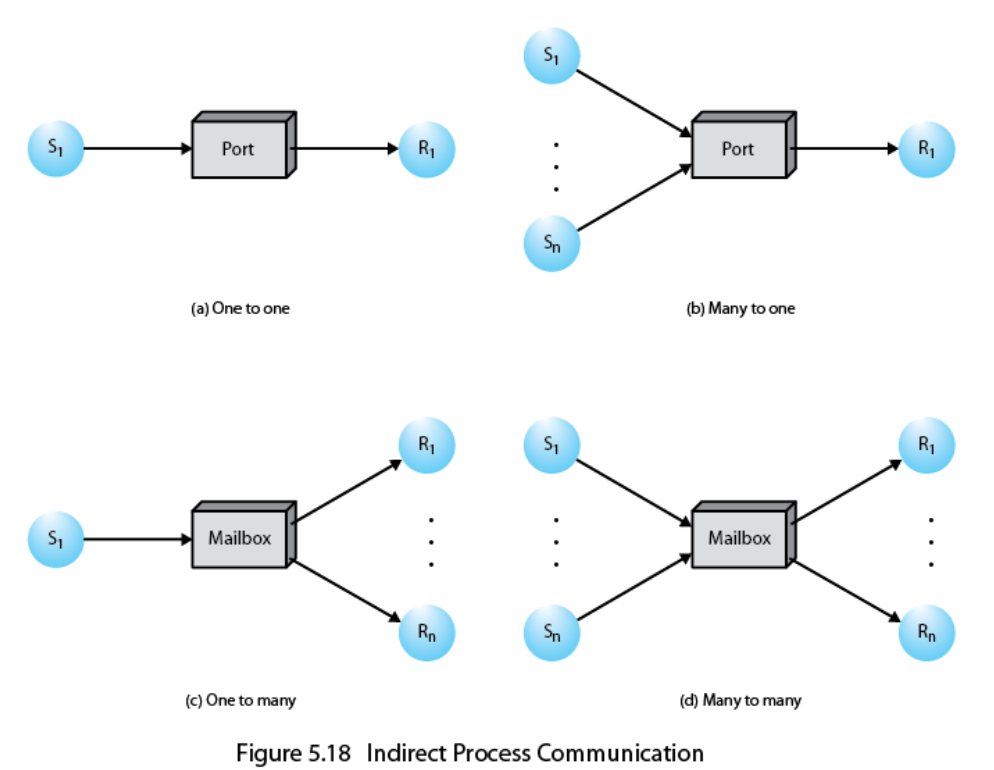
- Indirect addressing
- Messages are sent to the shared data structure consisting of queues
- Queues are called mailboxes
- One process sends a message to the mailbox and the other process picks up the message from the mailbox
- No processing right away after calling receive
Serial mq package: efficient for message passing, application, for game implementation.
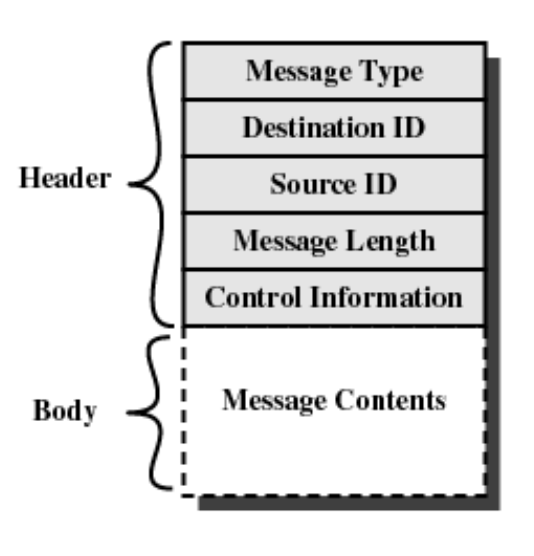
Message Format
Depends on the requirements of the OS
Example of implementation of message passing:
If we want 5 threads to be in the critical section, send 5 tokens in the send(mutex, null);
Drawback for test and set: Busy waiting.
Message Passing (2): Figure 5.21
Producer produces and stuff it in the mayconsume mailbox. Same as the consumer, there is a mayproduce. So we have two mailboxes.
Don’t forget to fill in the tokens, allow how much cake for the producer to producer.
Reader / Writer Problem (1)
- Assume that we have a number of readers to a file and one that can write.
- If a writer is writing to the file, no reader may read it
Code: Should the writer have priorities or the readers? Semaphore x protects readcount, makes sure in the reader section no one can mess the readcount. If we only have one readcount, we enter the if statment and call semWait(wsem). wsem is
Wed Feb 7 2024
Reader / Writer Problem (3)
- rsem in or out, needs to be in especially when we have a writer who wants to read and come in.
-
z only one writer can access the particular section
- x protects read count Produce() takes time,
Lecture 6 - Deadlock and Starvation
Joint Progress Diagram:
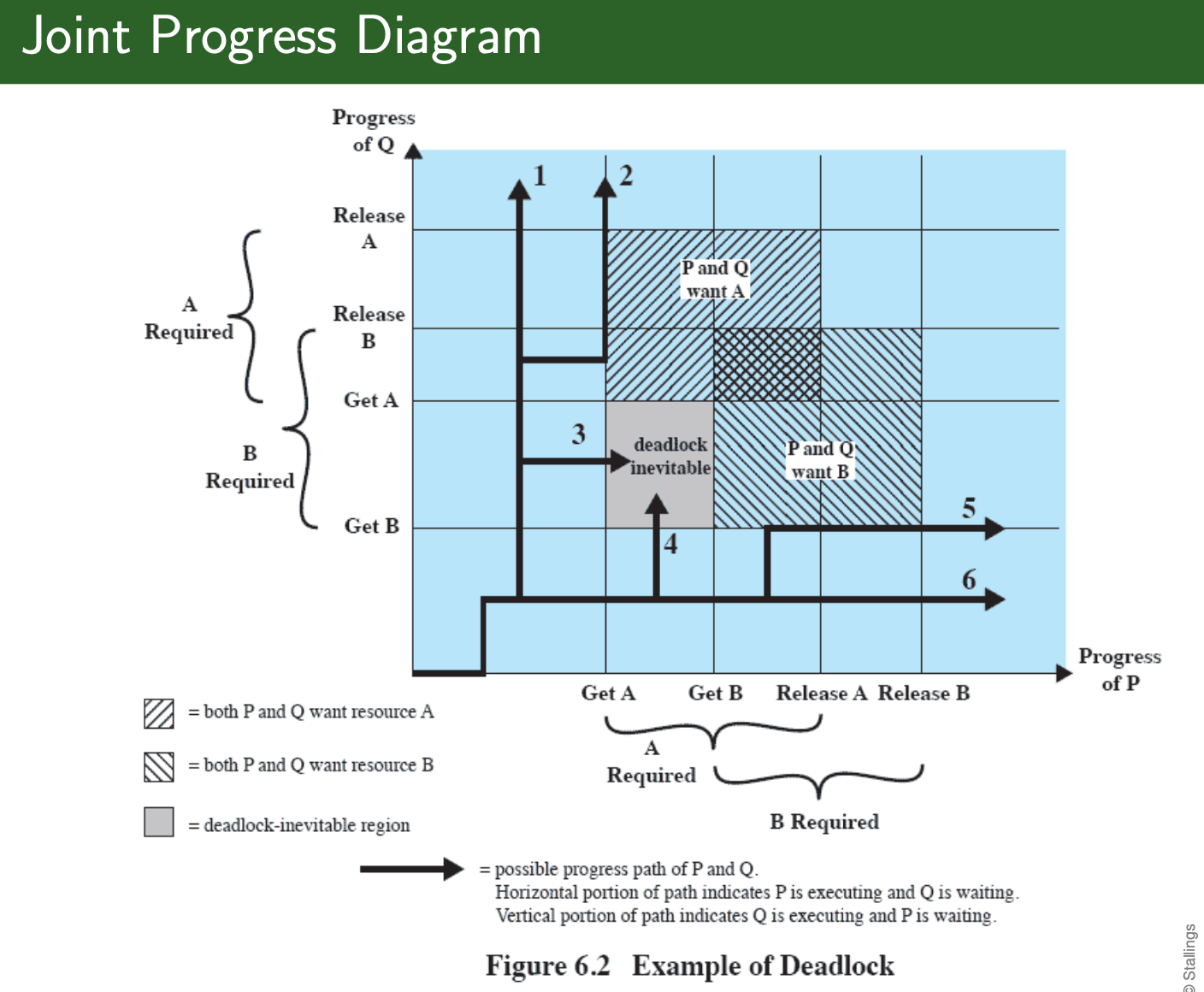
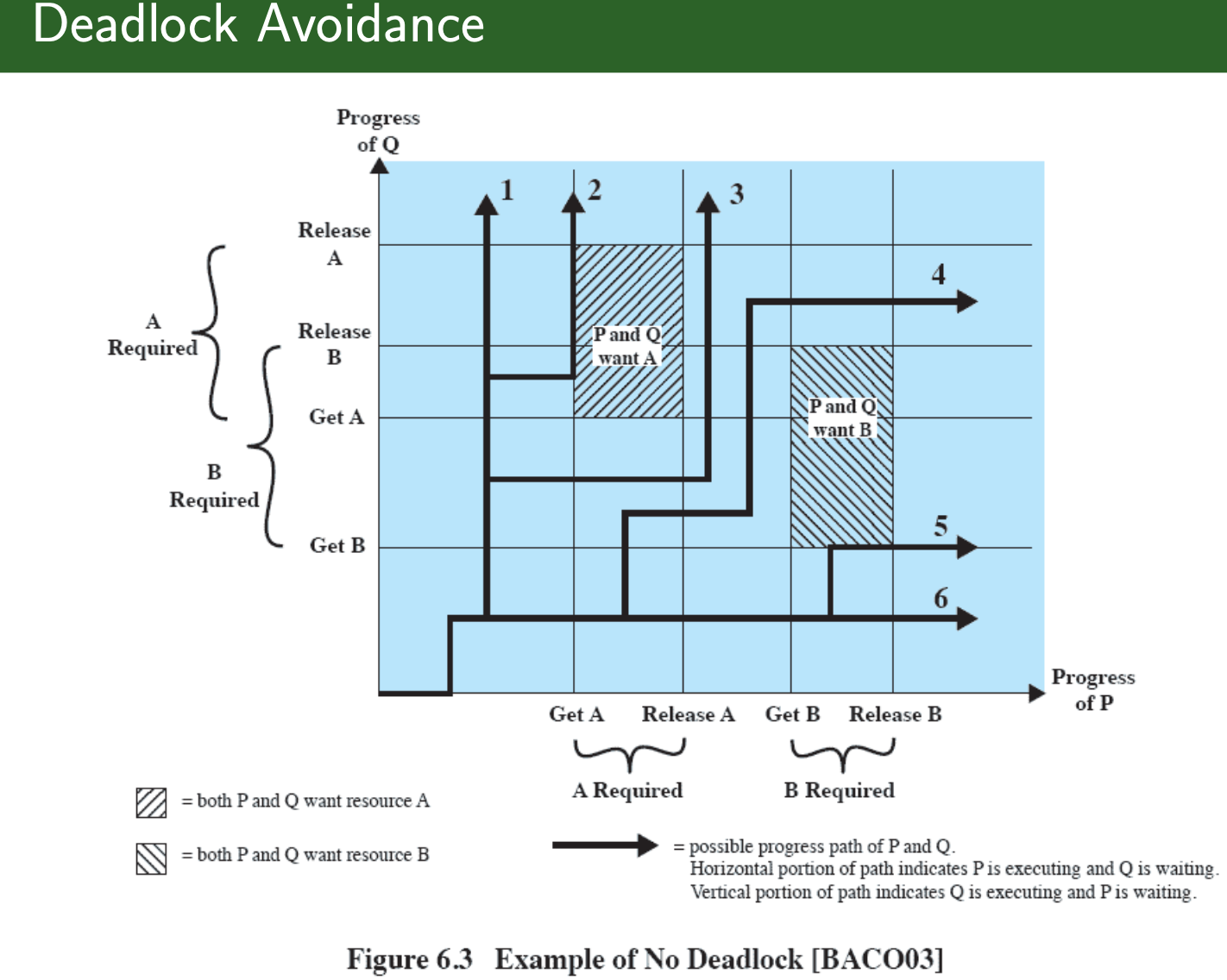
Let program Q to get A before B to avoid deadlock
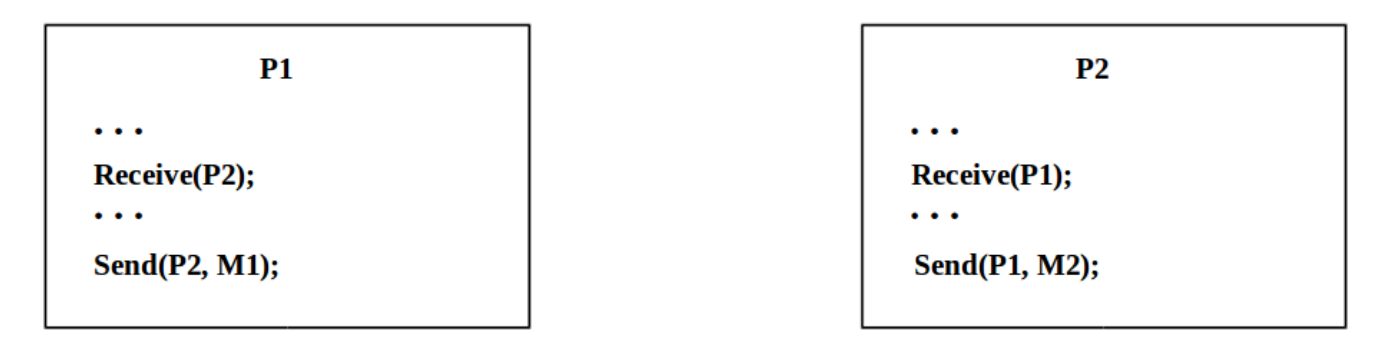
Deadlock occurs if they are on a blocking receive, so both are blocked.
Conditions for Deadlock:
- Mutual exclusion
- Hold-and-wait
- No preemption (wrt. resources)
- Circular wait
Banker’s algorithm runs when you make a request.
Refer to textbook Figure 6.7
Friday Feb 9 2024 (Continued with Lecture 6 deadlock slides)
Strategies once deadlock is detected
- Abort all deadlocked processes
- Back up each deadlocked process to some previously defined checkpoint, and restart all process
- Original deadlock may occur
- Successively abort deadlocked processes until deadlock no longer exists
Terminate the one who:
- consumes most resources
- lowest priority
- lowest importance
Method Comparisons:
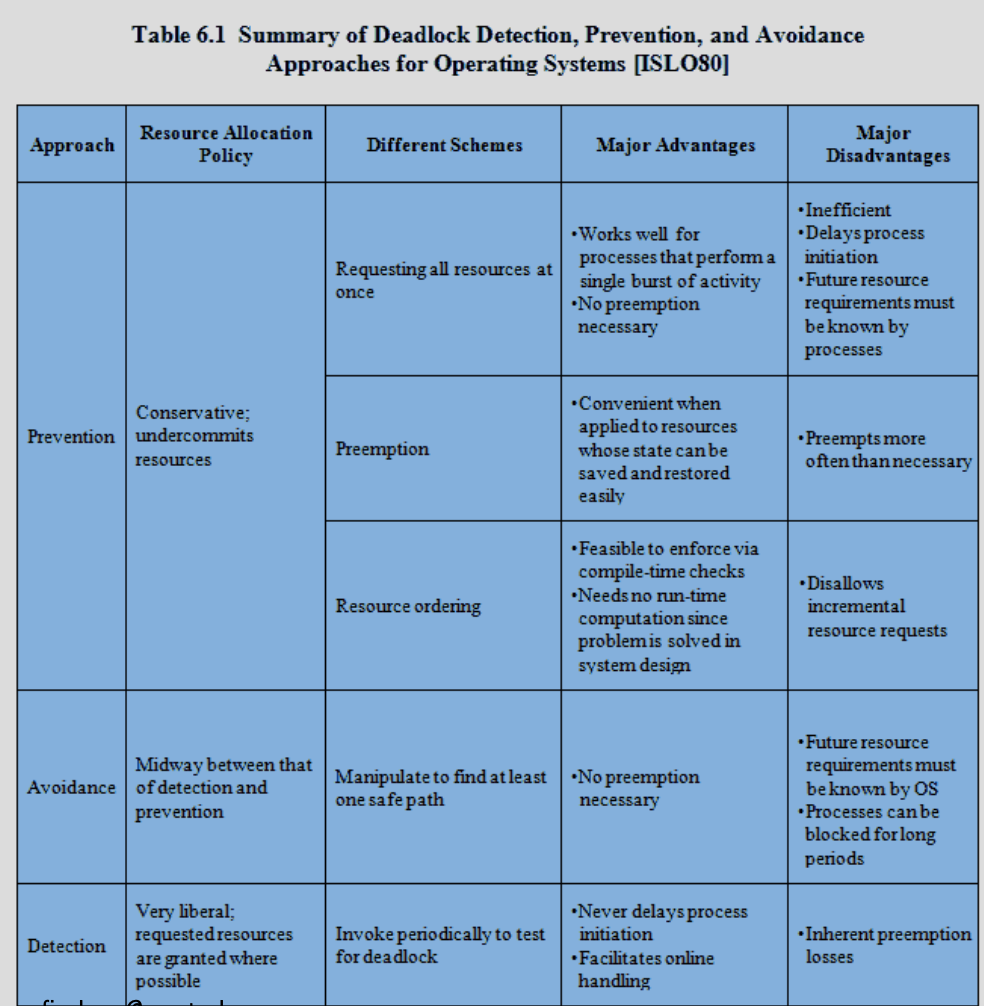
- Need to review 6.4 Deadlock Detection!
Dining Philosophers Problem
- Review 6.6 Dining Philosophers Problem! Answer: limit the number of philosophers to be at the table at any given time.
They have to wait to enter the room. There is always a pair of forks that is available.
Showed us a demo on it: used : ps axm | less to see how many threads are blocked
Lecture 7 - Memory Management
- Subdividing memory to accommodate multiple processes
- Memory needs to be allocated to ensure a reasonable supply of ready processes to consume available processor time
Requirements that memory management is intended to satisfy:
-
Relocation
- Programmer does not know where the program will be placed in memory when it is executed
- While the program is executing, it may be swapped to disk and returned to main memory at a different location (relocated)
- Memory references must be translated in the code to actual physical memory address
In linux you can go to
proc/andmem/to see how many memory
-
Protection
- Processes should not be able to reference memory locations in another process without permission
- Impossible to check absolute addresses at compile time
- Must be checked at execution time
- see your ‘segmentation fault’ bugs
-
Sharing
- Allow several processes to access the same portion of memory
- Better to allow each process access to the same copy of the program rather than have their own separate copy

Monday Feb 12 2024
Logical Organization
- Programs are written in modules
- Modules can be written and compiled independently
- Different degrees of protection given to modules (read-only, execute-only)
- Share modules among processes
Share modules among processes What can you share modules?
- libraries, because they are only going to be accessed by users in read-only mode
nm a.out : There is a book about linking and loading very complicated topic.
objdump: it can output symbols, disassemble code, dissect what comes before main
LD_LIBRARY_PRELOAD: set it as environment variable, good for attacks
Physical organization
- Memory available for a program plus its data may be insufficient
- Overlaying allows various modules to be assigned the same region of memory
- Programmer does not know how much space will be available
Fixed Partitioning
- Equal size partition problems:
- Any process whose size is less than or equal to the partition size can be loaded into an available partition
- If all partitions are full, the operating system can swap a process out of a partition
Problems:
May not fit, then you’ll have to use different partitions
Inefficient use
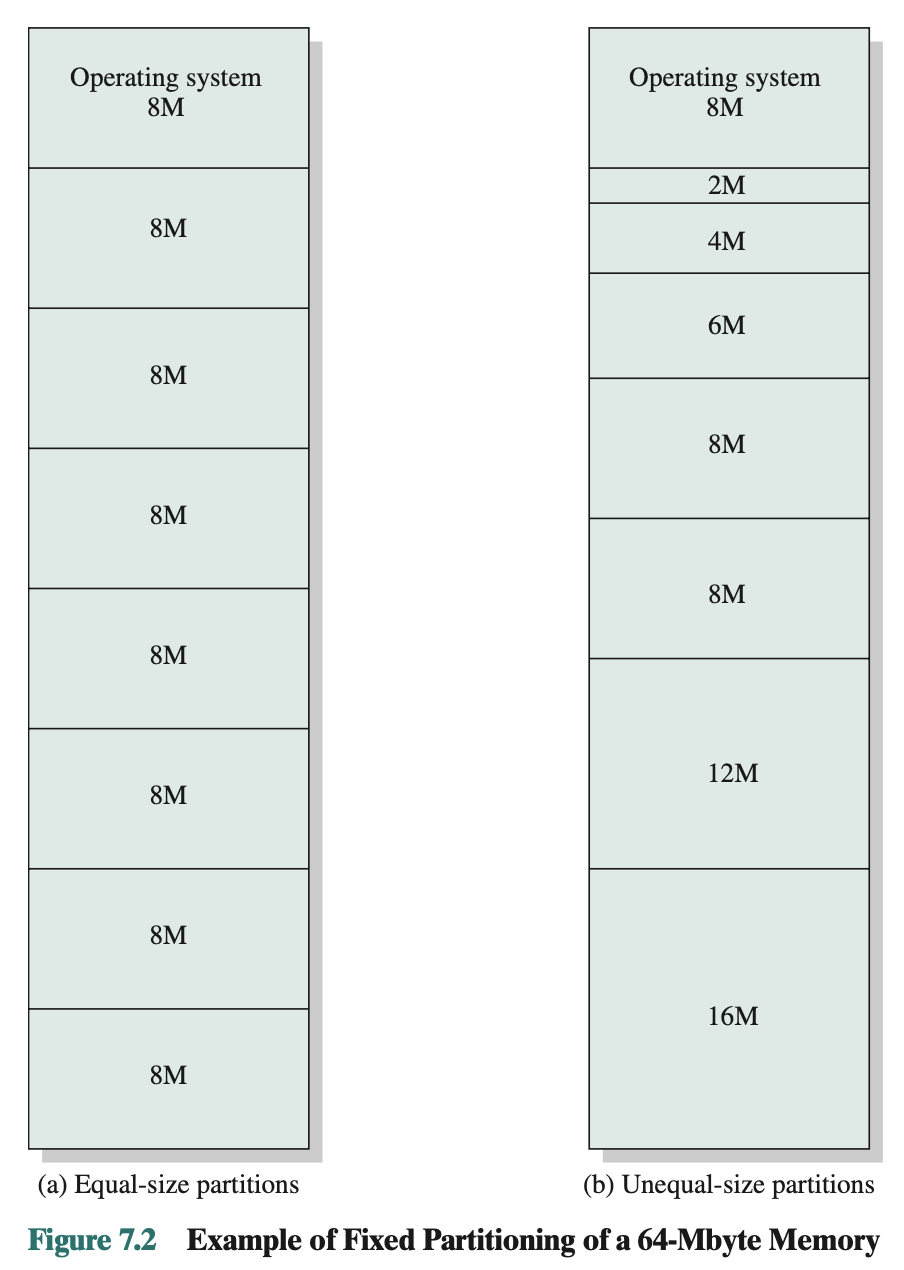
Placement Algorithm
- Equal-size
- Placement is trivial
- Unequal-size
- Can assign each process to the smallest partition within which it will fit
- Queue for each partition
- Processes are assigned in such a way as to minimize wasted memory within a partition
- Provides a degree of flexibility to fixed partitioning Disadvantages:
- Limits the number of active (not suspended) processes in the system
- Small jobs will not utilize partition space efficiently
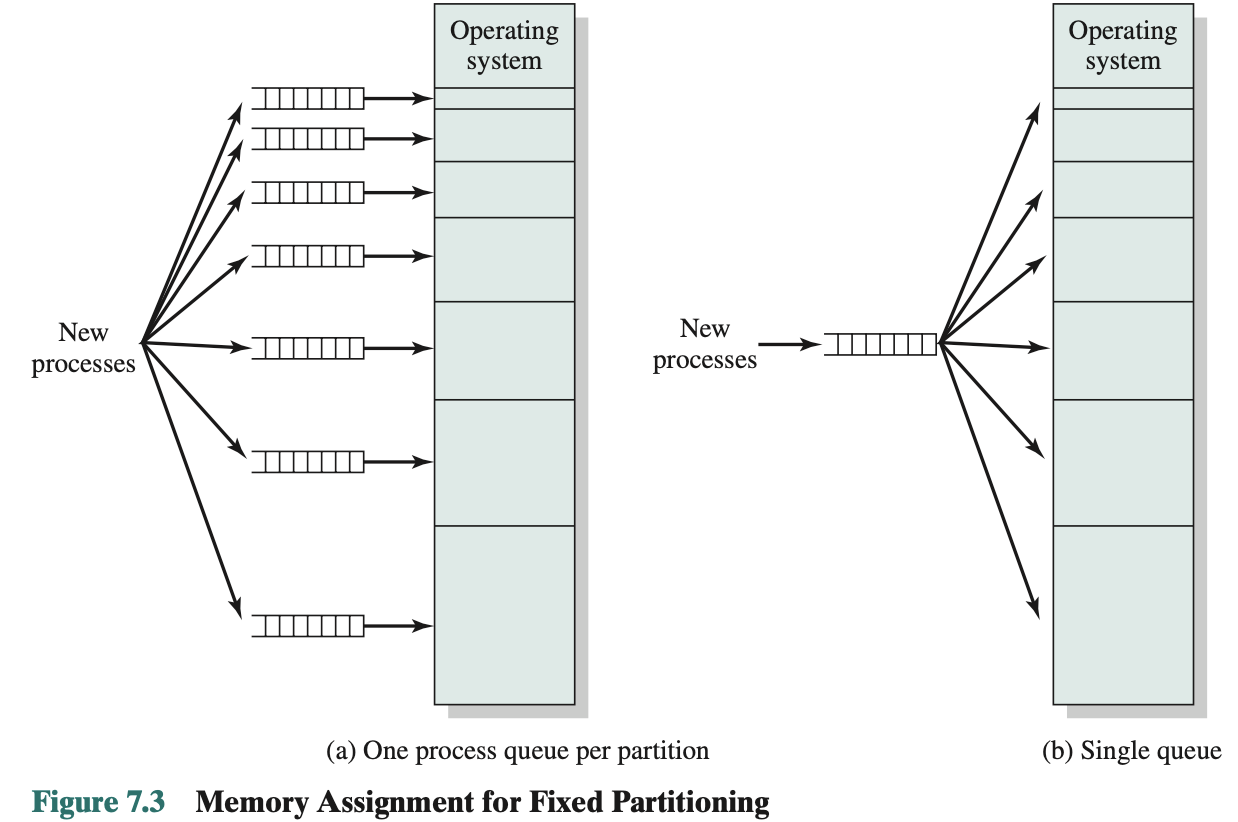
- Preferable approach would be to employ a single queue for all processes (Figure 7.3).
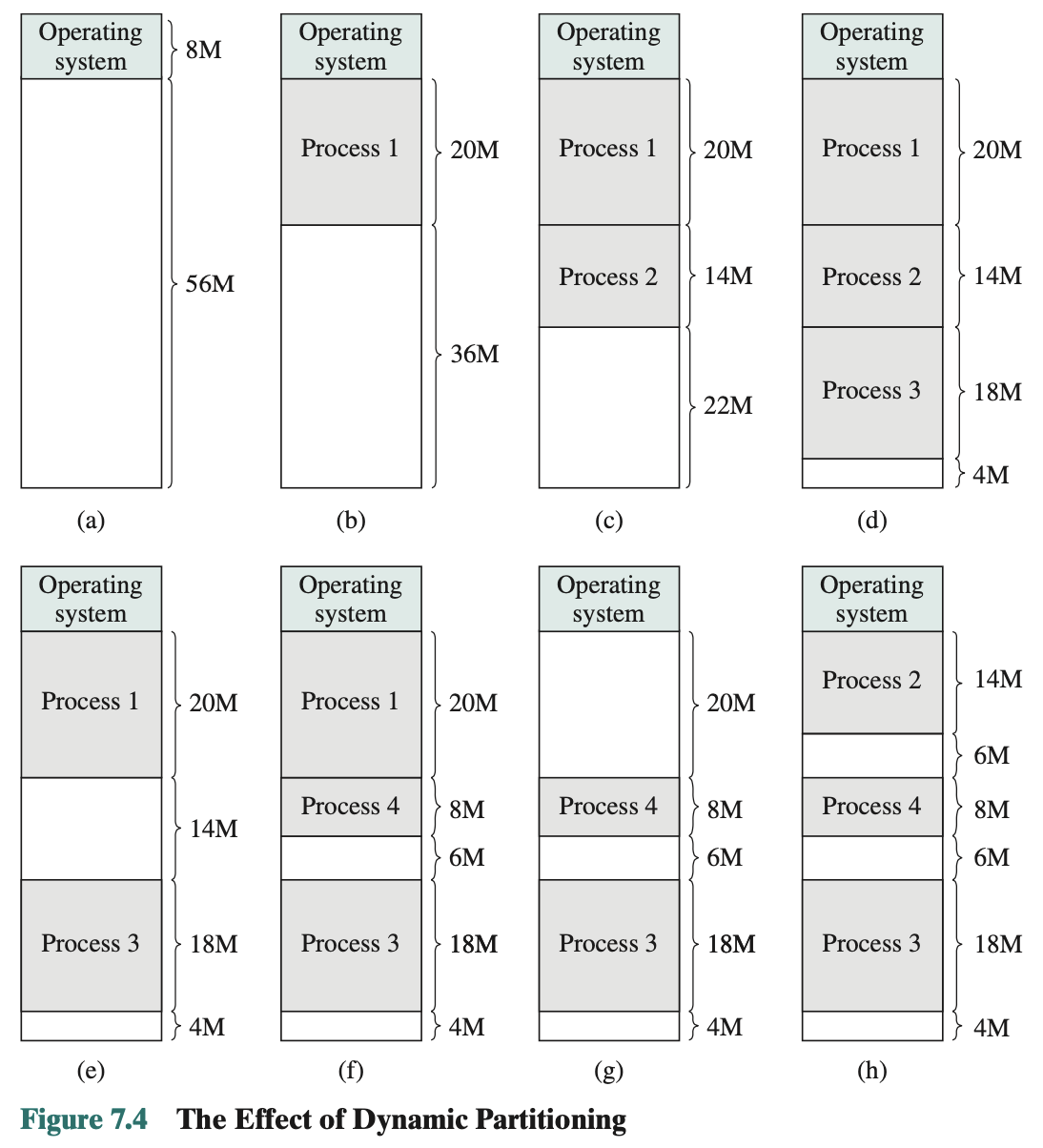
Dynamic Partitioning
- Partitions are of variable length and number
- Process is allocated exactly as much memory as required
- Eventually get holes in the memory. This is called external fragmentation
- Must use compaction to shift processes so they are contiguous and all free memory is in one block
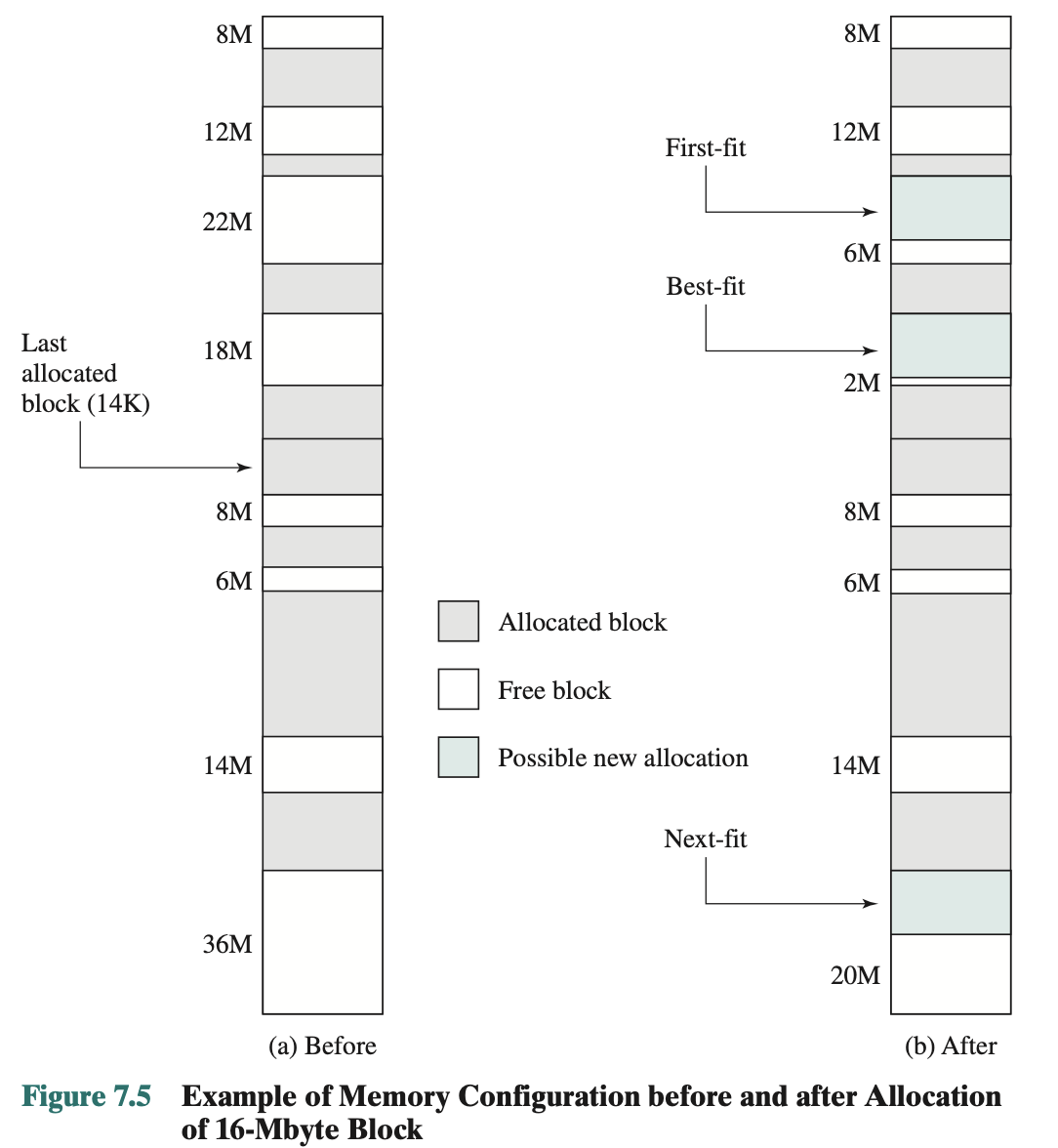
- Operating system must decide which free block to allocate to a process
- Best-fit algorithm
- Chooses the block that is closest in size to the request
- Worst performer overall
- Memory compaction must be done more frequently than with the other algorithms since it leaves small fragments behind
- First-fit algorithm
- Scans memory from the beginning and chooses the first available block that is large enough
- Fastest
- Next-fit algorithm
- Scans memory from the location of the last placement
- More often allocates a block of memory at the end of memory where the largest block is found
- The largest block of memory is broken up into smaller blocks
- Compaction is required to obtain a large block at the end of memory
- Best-fit algorithm
Buddy System
Implemented using a tree. Predictable and has the ability to merge.
- Entire space available is treated as a single block of
- If a request of sizes such that then the entire block will be allocated
- Otherwise the block is split into two equal sized buddies
- Process continues until smallest block greater than or equal to is generated.
Example:
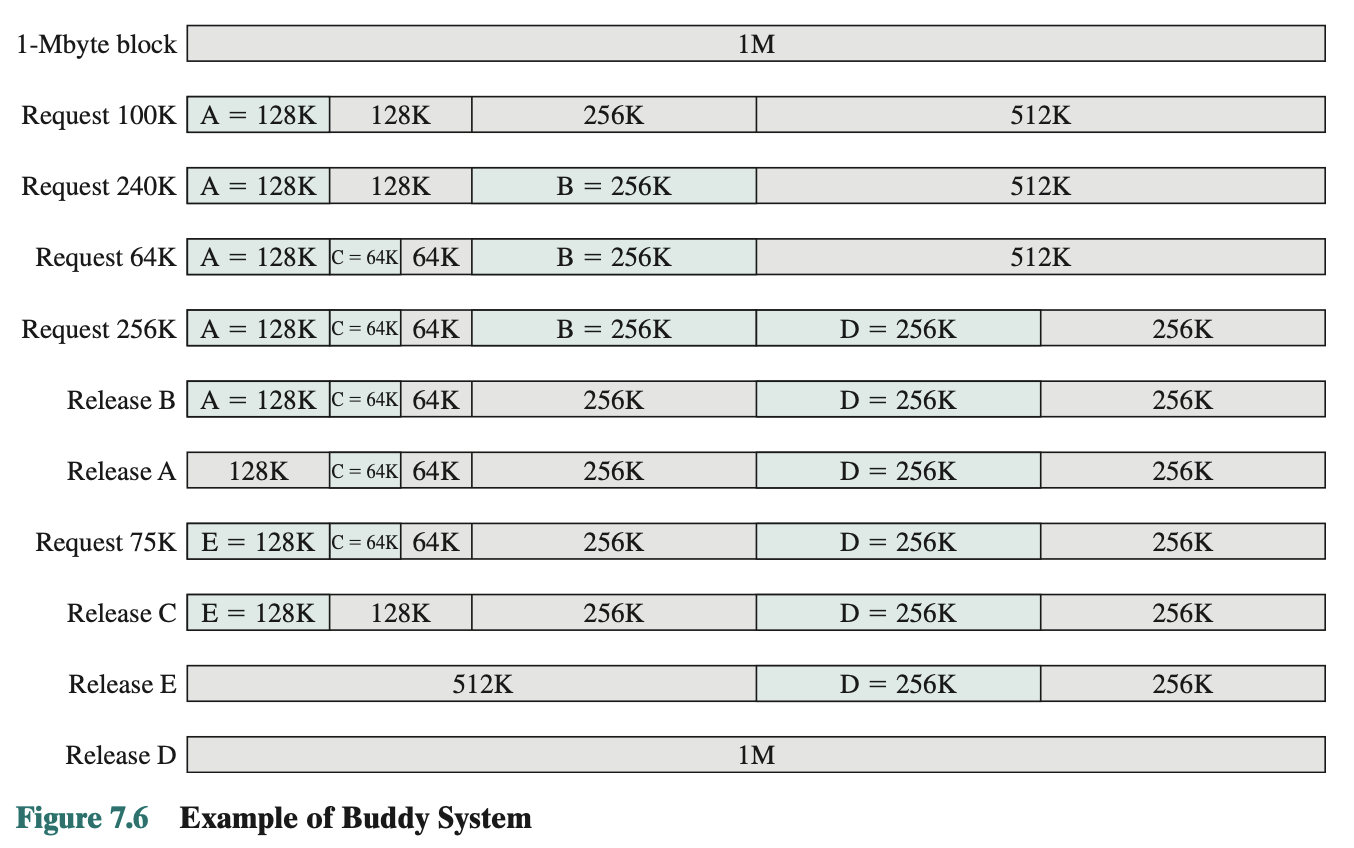
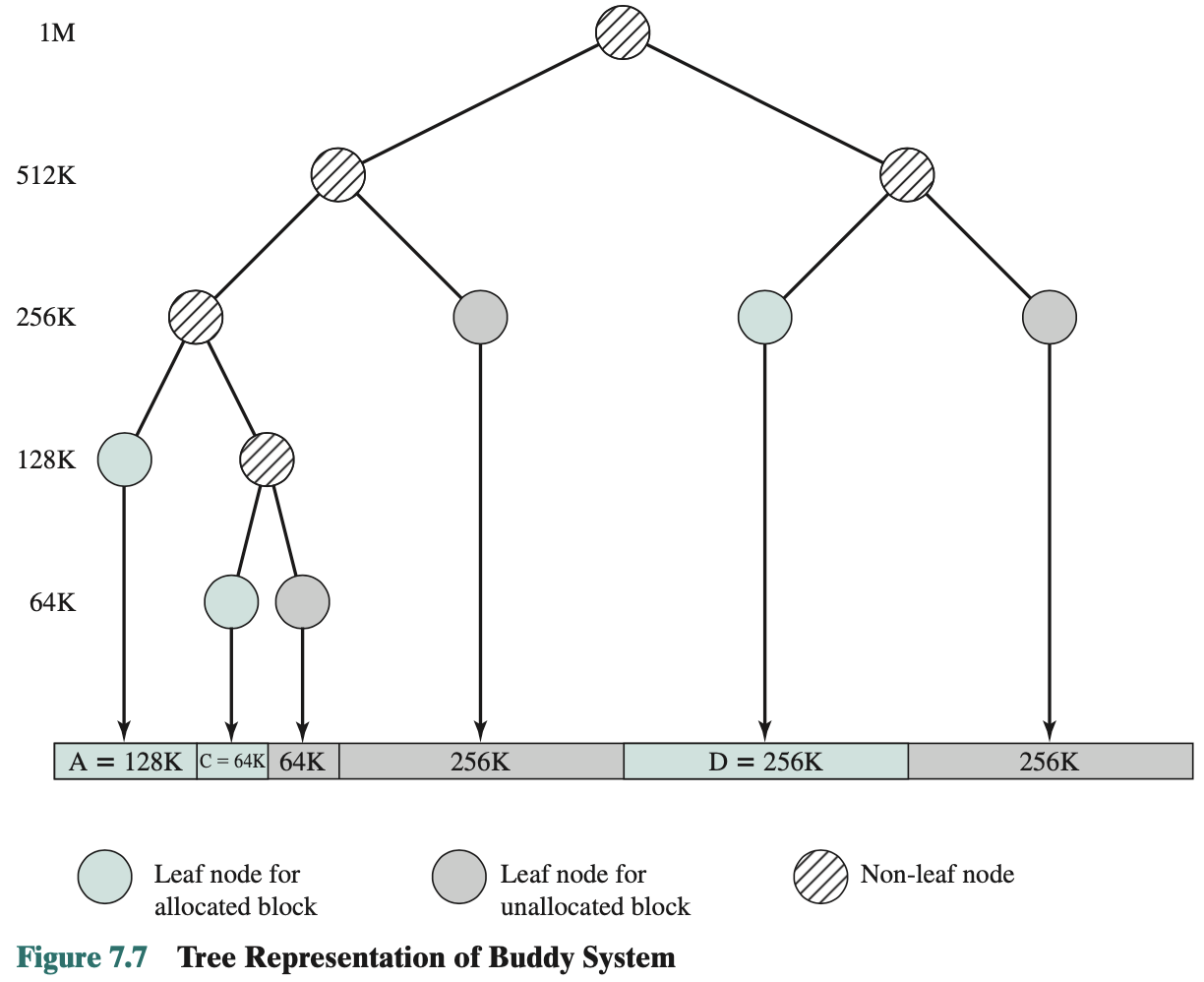
Figure 7.7 shows a binary tree representation of the buddy allocation immediately after the Release B request. The leaf nodes represent the current partitioning of the memory. If two buddies are leaf nodes, then at least one must be allocated; otherwise they would be coalesced into a larger block:
Relocation
- When program is loaded into memory, the actual (absolute) memory locations are determined
- A process may occupy different partitions, which means different absolute memory locations during execution (from swapping)
- Compaction will also cause a program to occupy a different partition, which means different absolute memory locations
- free up some space to have more memory space
Why have Relocation?
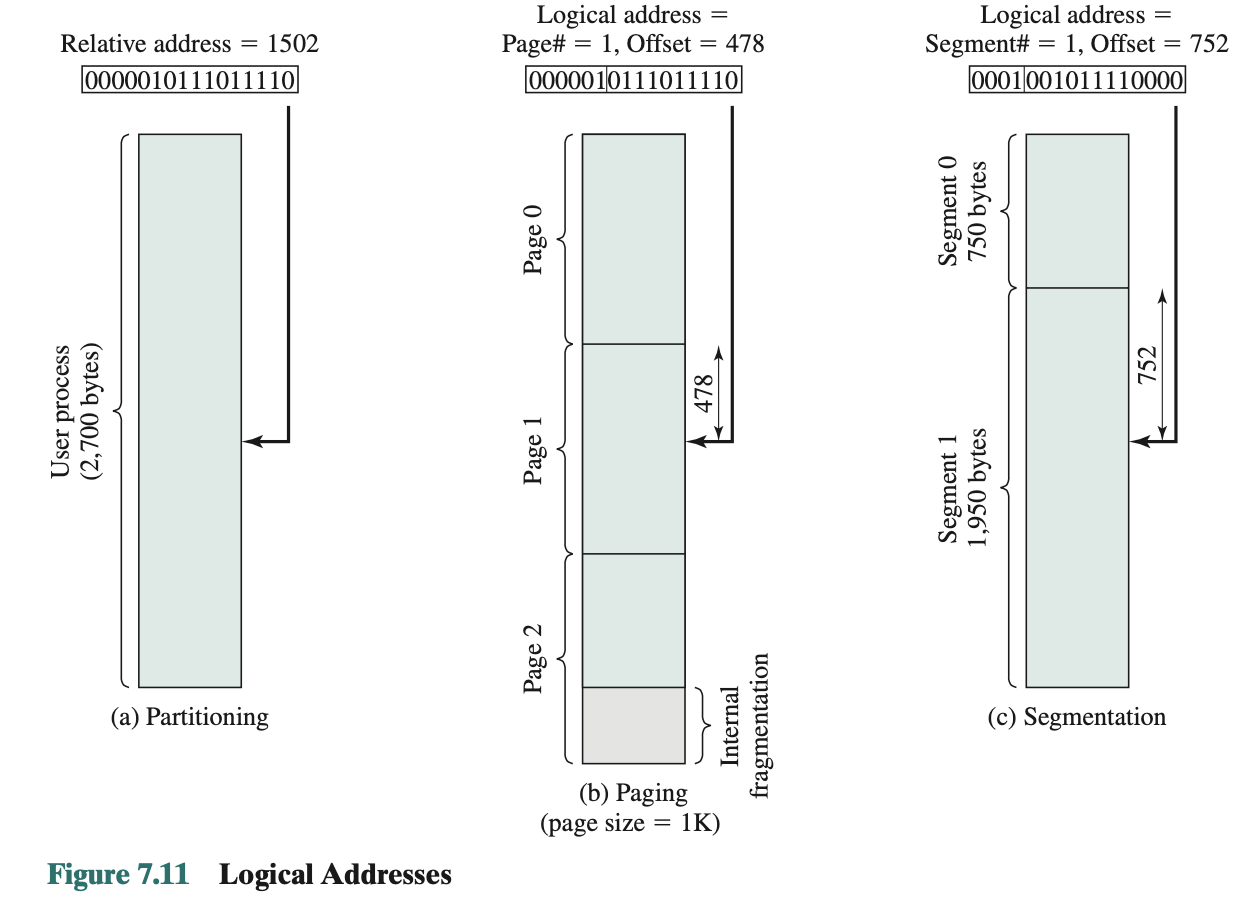
- Logical address
- Reference to a memory location independent of the current assignment of data to memory
- A translation must be made to the physical address before the memory access can be achieved
- Relative address
- Address expressed as a location relative to some known point
- A particular example of logical address, in which the address is expressed as a location relative to some known point, usually a value in a processor register
- Physical address
- The absolute address or actual location in main memory
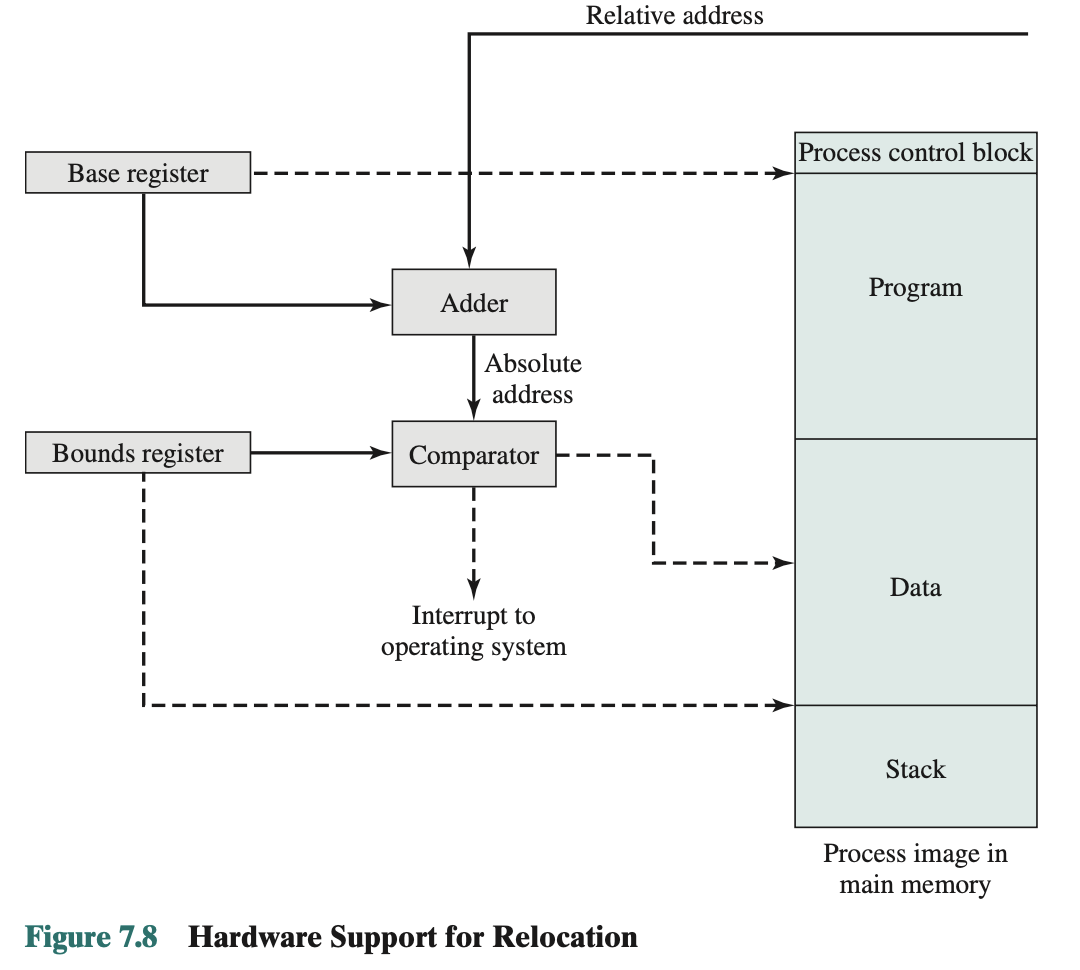
- Programs that employ relative addresses in memory are loaded using dynamic run-time loading. Relative to the origin of the program. Thus, a hardware mechanism is needed to translate relative addresses to physical main memory addresses at the time of execution of the instruction that contains the reference. Registers Used during Execution:
- Base register
- Starting address for the process
- Bounds register
- Ending location of the process
- Might go out of bound
- Theses values are set when the process is loaded or when the process is swapped in
- The value of the base register is added to a relative address to produce an absolute address
- The resulting address is compared with the value in the bounds register
- If the address is not within bounds, an interrupt is generated to the OS
Why of those are a problem for a process that gets swapped out and swapped in again?
Should use relative address: that way you just need the base and calculate with the relative address to get where it is placed.
What to do About External Fragmentation?
Delt with paging.
- frames is what you have in memory
- pages logical structure you have for your program of what kind of data you have
Wednesday Feb 14, 2024: Didn’t attend
Paging
- Partition memory into small equal fixed-size chunks and divide each process into the same size chunks
- The chunks of a process are called pages and chunks of memory are called frames
- Base address pointer no longer sufficient
- Operating system maintains a page table for each process
- Contains the frame location for each page in the process
- Memory address consist of a page number and offset within the page
- Logical-to-physical is still done by hardware
- Logical address: (page, offset)
- Physical address: (frame, offset)
- Page table shows the frame location for each page of the process. Within the program, each logical address consists of a page number and an offset within the page.
- Recall in the case of simple partition, a logical address is the location of a word relative to the beginning of the program; the process translates that into a physical address
- With paging, the logical-to-physical is done by process hardware
- Processor needs to know how to access the page table of the current process
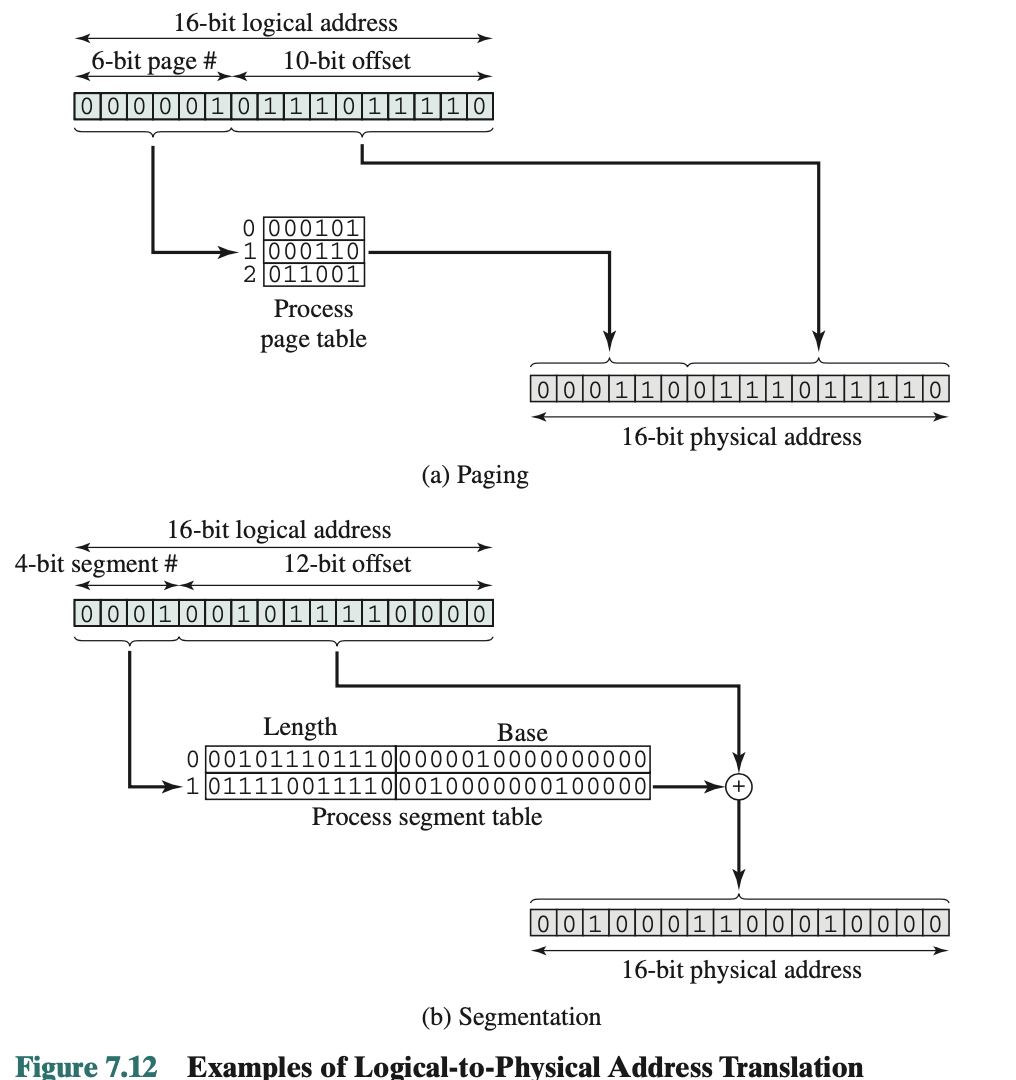
- Presented with a logical address (page number, offset), the processor uses the page table to produce a physical address (frame number, offset)

- Page table holds where in the memory, the different pages are located!
Logical Addresses:
The following steps are needed for address translation:
- Extract the page number as the leftmost n bits of the logical address.
- Use the page number as an index into the process page table to find the frame number, k.
- The starting physical address of the frame is k * 2m, and the physical address of the referenced byte is that number plus the offset. This physical address need not be calculated; it is easily constructed by appending the frame number to the offset.
Consequence of using page size that is a power of 2:
- Logical addressing scheme is transparent to the programmer, assembler and linker
- Each logical address (page number, offset) of a program is identical to its relative address?
- Relatively easy matter to implement a function in hardware to perform dynamic address translation at run-time.
Segmentation
- Program is divided into segments
- All segments of all programs do not have to be of the same length
- There is a maximum segment length
- As with paging, a logical address using segmentation consist of two parts: (segment number, offset)
- Since segments are not equal, segmentation is similar to dynamic partitioning
- But program can have more segments (but only one partition)
Don't really understand the difference between partition and segments??
The difference, compared to dynamic partitioning, is that with segmentation a program may occupy more than one partition, and these partitions need not be contiguous?? What does this mean?
Summary:
- with simple segmentation, a process is divided into a number of segments that need not be of equal size. When a process is brought in, all of its segments are loaded into available regions of memory, and a segment table is set up.
Monday Feb 26: Missed class because of studying for math213 midterm
Lecture 8 - Virtual Memory
- Define Virtual Memory
- hardware and control structures that support virtual memory
- OS mechanisms used to implement virtual memory
Somehow with this resident set of the process, it can know if the memory locations needed are indeed presently in memory?? I’m a bit confused, but I understand the idea.
Virtual Memory Loads the program’s code and data on demand:
- Upon reads, load memory from disk.
- When memory is unused, write it to disk.
Enablers of Virtual Memory
- Addresses are logical, not physical
- Run-time address translation (paging and segmentation) enable noncontiguous memory layouts.
Implication: a process can successfully run without being fully resident in memory.
What do we need?
Two things:
- Next instruction to execute
- Next data to be accessed
With these items, you’re good to go.
Pulling it off
- Load some part of the program.
- Start executing, till program tries to read or execute something not in RAM (page fault).
- Upon page fault, block the process, read in data, resume the process.
Page faults
- How does the OS know when to load data? CPU triggers page fault upon access to nonresident data/code.
Performance Implications
- Lazy loading is often a win, but
- Disk load batches of data faster.
Functionality WIN
- Can juggle more processes in memory at once.
- A process can exceed system’s RAM size.
Comparison
- Real memory backed by RAM chips.
- Because a process executes only in main memory, that memory is referred to as real memory.
- Virtual memory: RAM and swap space.
Is virtual memory too slow?
Nope. Key win of lazy loading: CPU keeps busy, hence less wasted time. Only a small part of each process is active at a time (we hope).
Thrashing
When the OS brings one piece in, it must throw another out. If it throws out a piece just before it is used, then it will just have to go get that piece again almost immediately. Too much of this leads to a condition known as thrashing: The system spends most of its time swapping pieces rather than executing instructions.
Principle of Locality
OS tries to guess, based on recent history, which pieces are least likely to be used in the near future. This reasoning is based on belief in the principle of locality.
To summarize, the principle of locality states that program and data references within a process tend to cluster. Hence, the assumption that only a few pieces of a process will be needed over a short period of time is valid. Also, it should be possible to make intelligent guesses about which pieces of a process will be needed in the near future, which avoids thrashing.
Stuff you need in the future is close to stuff you needed in the past.
Requirements for Virtual Memory
- Hardware must support paging and segmentation
- Operating system support for putting pages on disk and reloading them from disk.
- OS must include software for managing movement of pages and/or segments between secondary and main memory.
Paging
Can refer to Paging. I took notes there too.
- review table 8.2 in detail later (I’ve skipped it while reading the textbook for now)
- There is one entry in the inverted page table for each real memory page frame rather than one per virtual page.???? multiple virtual address may map to the same table entry → chaining technique is used to manage overflow
- The page table’s structure is called inverted because it indexes page table entries by frame number rather than by virtual page number.
Wed Feb 28: 15 minutes late to class
He was on slide 35/76
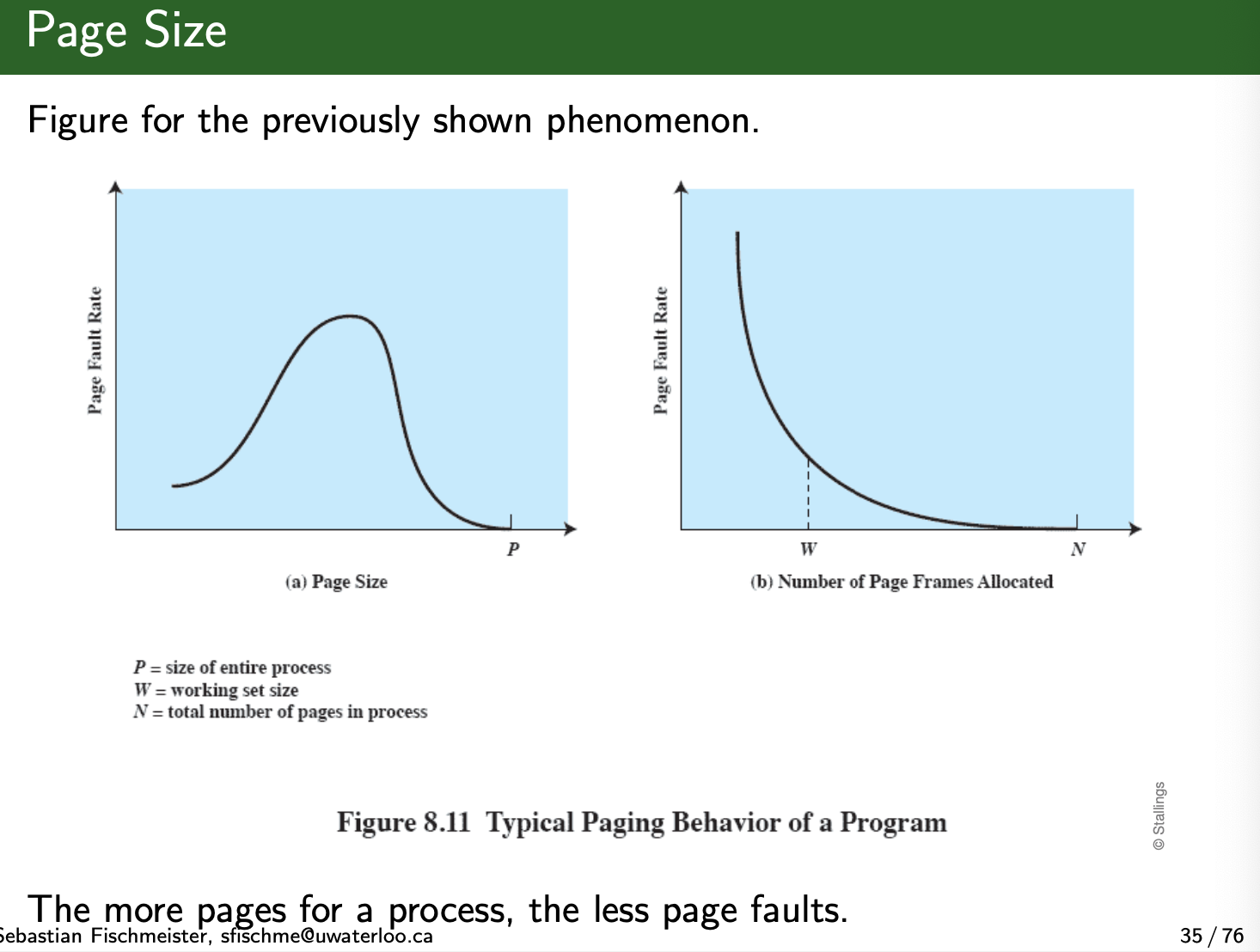
- The smaller the page size, the lesser is the amount of internal fragmentation.
- Apparently, at some point, everything is in memory.
- The smaller the page, the greater is the number of pages required per process. More pages per process means larger page tables
- If the page size is very small, then ordinarily a relatively large number of pages will be available in main memory for a process
- the pages in memory will all contain portions of the process near recent references. Thus, the page fault rate should be low. As the size of the page is increased, each individual page will contain locations further and further from any particular recent reference. Thus, the effect of the principle of locality is weakened and the page fault rate begins to rise.
Segmentation
Advantages:
- allows you to logically group some memories, reserve it for some use cases
- Good for debugging
- allow some programs to read, write → share memory and data (instead of sharing pages == pain)
- protect segments (useful for liability if there is a program defect, advantages in security)
To manage segments we have Segment Tables
- Starting address corresponding segment in main memory
- Similar to PCB
- Each
Why is there a length for the segment table
Otherwise, process will read and write into wrong segments.
Combined Paging and Segmentation
In a combined paging/segmentation system, a user’s address space is broken up into a number of segments, at the discretion of the programmer. Each segment is, in turn, broken up into a number of fixed-size pages, which are equal in length to a main memory frame.
From the programmer’s point of view, a logical address still consists of a segment number and a segment offset. From the system’s point of view, the segment offset is viewed as a page number and page offset for a page within the specified segment.
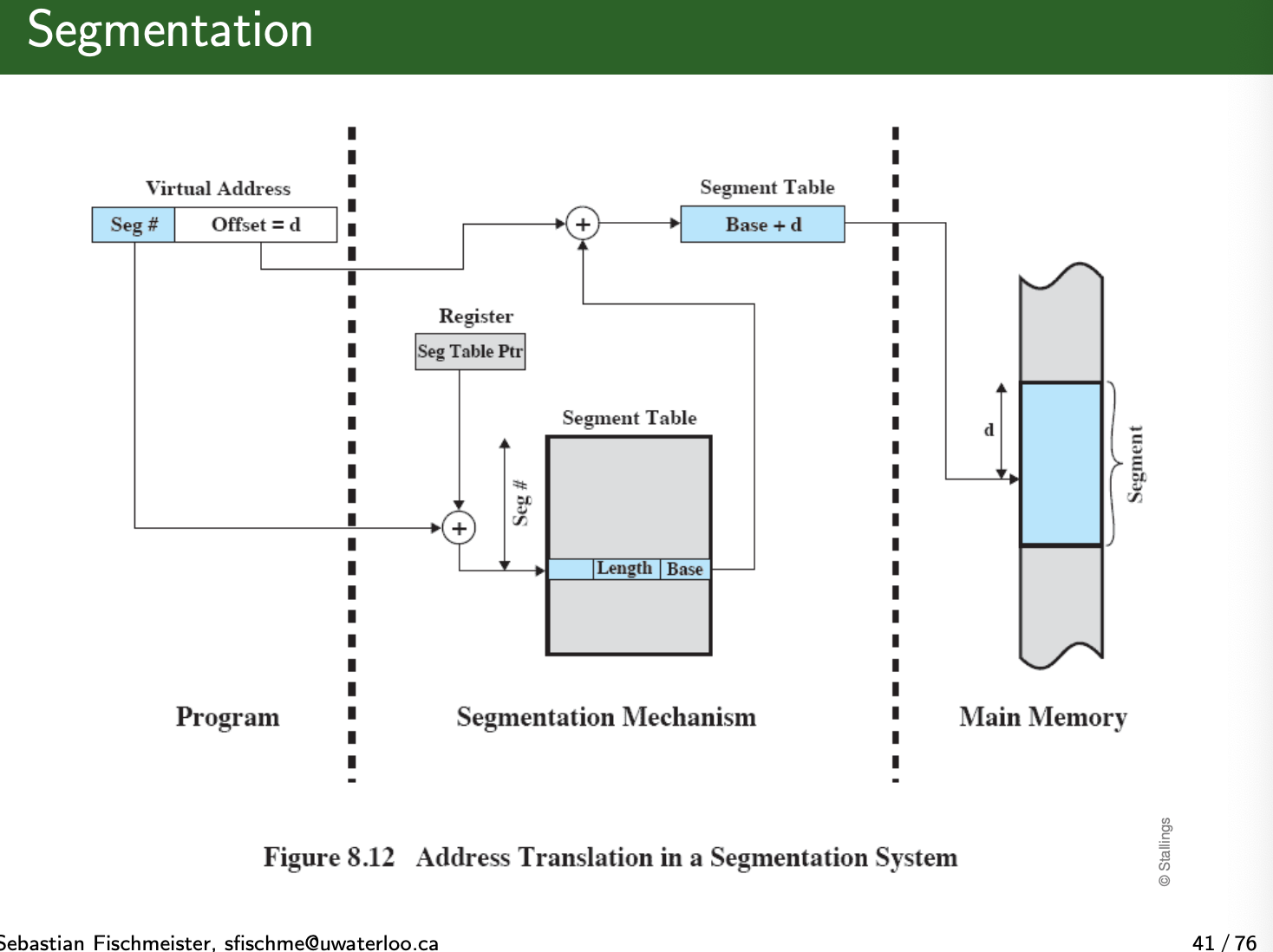
Segment can potentially have fragmentation?
Address Translation:
- For segment number we go into the segment table, for page number we go to the page table. Add and compute.
- Add because we add the offset into the table when we compute.
- MMU takes care of this usually (depends on processor)
Protection and Sharing
Protection Relationships:
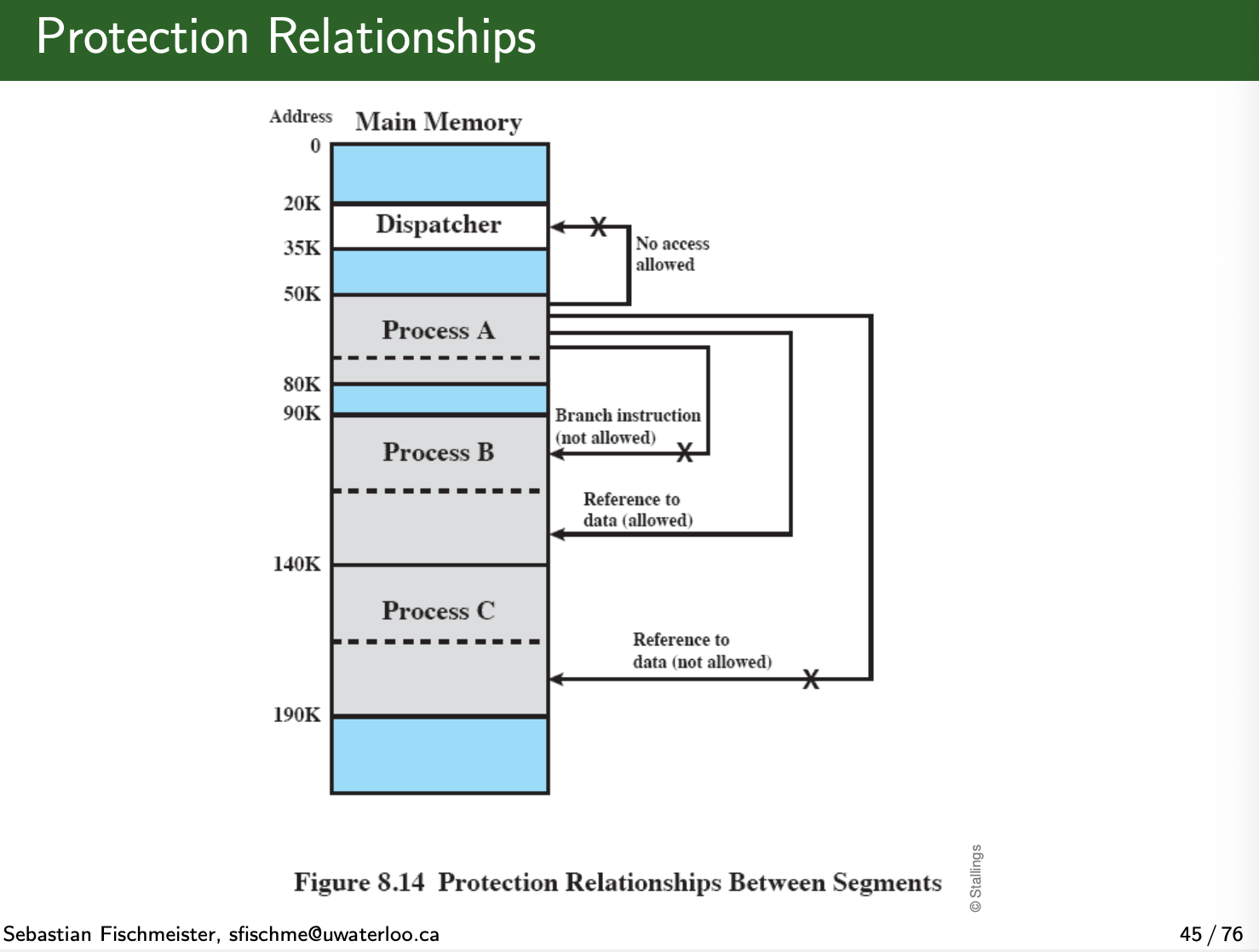
Do you need Virtual Memory?
Operating System Software
OS Designer needs to make three choices:
- Does the system need virtual memory?
- Paging, segmentation or both?
- Which algorithms for memory management?
- Required algorithms:
- Fetch policy Placement policy
- Replacement policy
- Cleaning policy (Load control)
Fetch Policy
- Determines when a page should be brought into memory
- Demand paging only brings pages into main memory when a reference is made to a location on the page
- Many page faults when process first started
- But over time, based on the principle of locality, most future references will be to pages that have recently been brought in. Thus, number of page faults will drop to a low level over time.
- Prepaging brings in more pages than needed
- pages other than the one demanded by a page fault are brought in (think of Prof’s whole analogy with bringing boxes from the basement). I guess, it’s kind of like, oh if I nee to bring this one in, then might as well bring the ones that I think I will nee to in all in one time.
- More efficient to bring in pages that reside contiguously on the disk
- Do not confuse prepaging with swapping
- When process is swapped out, all its resident pages are moved out.
- When the process resumes, all of the pages that were previously in main memory are returned into it.
In UNIX there is LD_PRELOAD: load libraries required at runtime, specify path if it is installed in another location then where it default looks at
Placement Policy
- Determines where in real memory a process piece is to reside
- Important in a segmentation system (minimize fragmentation)
- Paging or combined paging with segmentation hardware performs address translation
- Irrelevant in system that uses either pure paging or paging combined with segmentation, because the address translation hardware and the main memory access hardware can perform their functions for any page-frame combination with equal efficiency.
todo start taking notes of slide here
Replacement Policy
“Replacement policy,” which deals with the selection of a page in main memory to be replaced when a new page must be brought in.
Replacement Policy
studies when all of the frames in main memory are occupied and it is necessary to bring in a new page to satisfy a page fault. So the replacement policy determines which page currently in memory is to be replaced.
All the policies have their objective that the page that is removed should be the page least likely to be referenced in the near future. Most policies try to predict the future behaviour on the basis of past behaviour.
- Frame locking
- Restriction on replacement policy? Some frames in main memory might be locked. It can’t be replaced.
- Much of the kernel of the OS, as well as key control structures are held in locked frames. I/O buffers and other time-critical areas may be locked into main memory frames.
- telling the OS not to throw out the box, i need it
- Used for example in:
- Kernel
- Key control structure (cuz can cause deadlock)
- I/O buffers
- Time critical elements
- lock means os can’t swap it out (when you lock memory)
- what if process spawns a lot of process and locks them
Basic algorithms are:
- Optimal
- Least recently used (LRU)
- First-in-first-out (FIFO)
- Clock
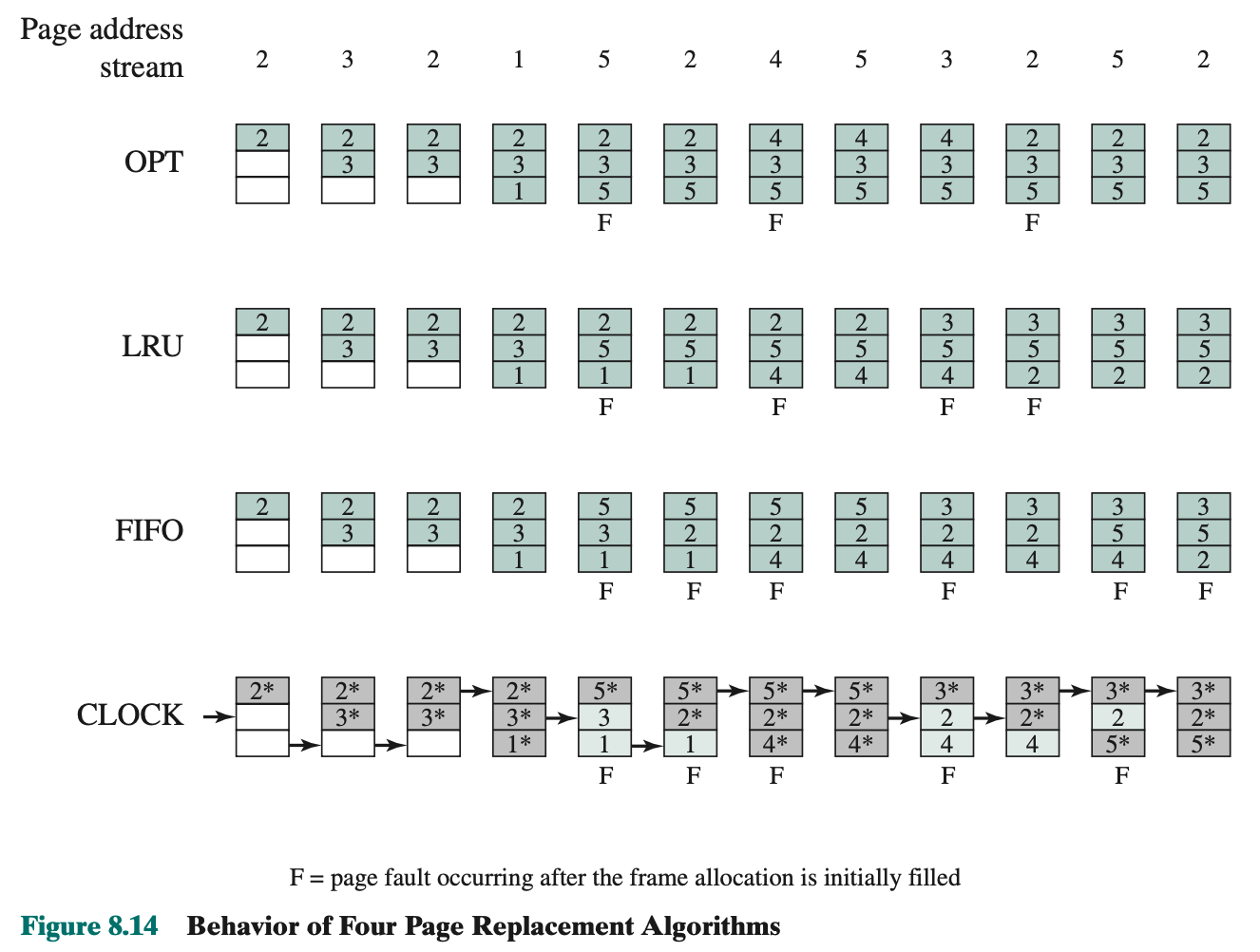
- LRU is not doable(hard to implement?), because you’ll need to mark it up (takes a lot of bits). A lot of overhead.
- Clock, add use bit (to represent if it has been accessed or not recently (since last time you’ve tried to access something)) → clock policy
- Pointer, if use bit is initially 1, we don’t replace. Set the use bit to 0, and advance the pointer. Only replace if the use bit is 0. Then we replace with incoming page, and set the use bit from 0 to 1 and advance the pointer. Thus completing the replacement procedure of the page.
- If all of the frames have a use bit of 1, then the pointer will make one complete cycle through the buffer, setting all the use bits to 0, and stop at its original position, replacing the page in that frame.
Comparison: compares the four algorithms
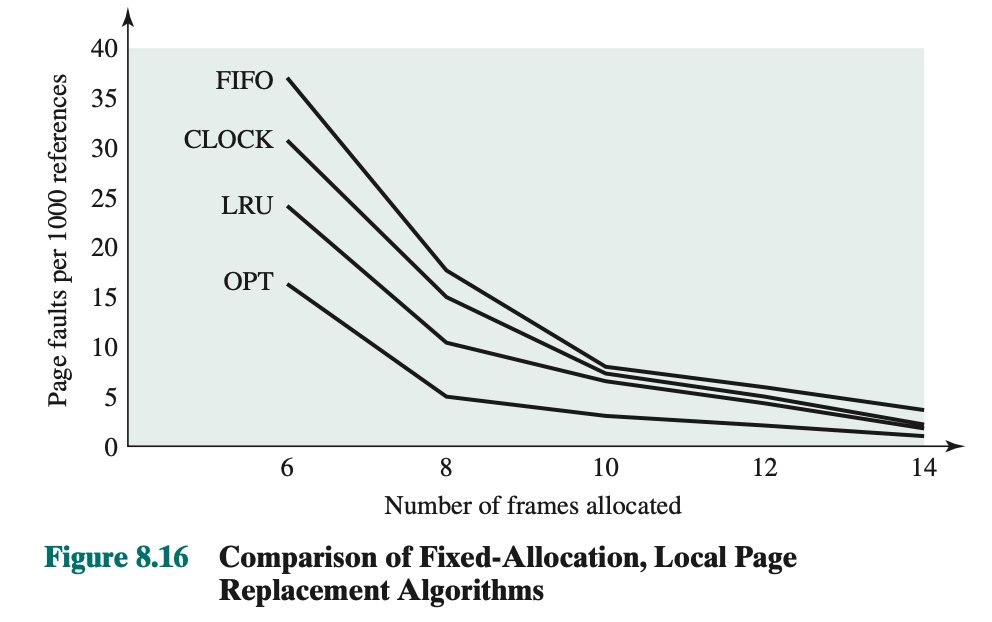
- Assumed that page assigned is fixed
- In order to run efficiently, we would like to be to the right of the knee of the curve (with a small page fault rate) while keeping a small frame allocation (to the left of the knee of the curve)
Stopped at Slide 58/76
Mon March 4 2024
Tools define people - Dijkstra
- Go through the Clock page replacement algorithm
- Page buffering
Prof likes cooking.
Resident Set Management
Resident Set Size: OS must decide how many pages to bring in, that is, how much main memory to allocate to a particular process. Factors:
- The smaller the amount of memory allocated to a process, the more processes that can reside in main memory at any one time. This increases the probability that the OS will find at least one ready process at any given time and hence reduces the time lost due to swapping.
- If a relatively small number of pages of a process are in main memory, then, despite the principle of locality, the rate of page faults will be rather high (see Figure 8.10b).
- Beyond a certain size, additional allocation of main memory to a particular process will have no noticeable effect on the page fault rate for that process because of the principle of locality.
Replacement Scope
The scope of a replacement strategy can be categorized as global or local. Both types of policies are activated by a page fault when there are no free page frames.
- A local replacement policy chooses only among the resident pages of the process that generated the page fault in selecting a page to replace.
- A global replacement policy considers all unlocked pages in main memory as candidates for replacement, regardless of which process owns a particular page.
FIXED ALLOCATION, LOCAL SCOPE
For this case, we have a process that is running in main memory with a fixed number of frames.
Whenever a page fault occurs in the execution of a process, one of the pages of that process must be replaced by the needed page.
A fixed resident set implies a local replacement policy
VARIABLE ALLOCATION, GLOBAL SCOPE
This combination is perhaps the easiest to implement and has been adopted in a number of operating systems.
At any given time, there are a number of processes in main memory, each with a certain number of frames allocated to it. Typically, the OS also maintains a list of free frames. When a page fault occurs, a free frame is added to the resident set of a process and the page is brought in. Thus, a process experiencing page faults will gradually grow in size, which should help reduce overall page faults in the system.
One way to counter the potential performance problems of a variable-allocation, global-scope policy is to use page buffering.
VARIABLE ALLOCATION, LOCAL SCOPE
The variable-allocation, local-scope strategy attempts to overcome the problems with a global-scope strategy. It can be summarized as follows:
- When a new process is loaded into main memory, allocate to it a certain number of page frames as its resident set, based on application type, program request, or other criteria. Use either prepaging or demand paging to fill up the allocation.
- When a page fault occurs, select the page to replace from among the resident set of the process that suffers the fault.
- From time to time, reevaluate the allocation provided to the process, and increase or decrease it to improve overall performance.
- Fixed-allocation
- Local Scope
- Variable-allocation
- Based on activity: shrink or add, that is if there is a demand (activity)
- Global Scope
- Local Scope
- periodically check if we have enough space to the process (residetn size), then decide to add or remove
Why is fixed allocation global replacement strategy not possible?
Contradicts each other, global replacement you can replace
Working set strategy.
I skipped this. Learn the formula and go through the table I guess…
Problem with working set strategy:
- The past does not always predict the future. Both the size and the membership of the working set will change over time (e.g., see Figure 8.18).
- A true measurement of working set for each process is impractical. It would be necessary to time-stamp every page reference for every process using the virtual time of that process and then maintain a time-ordered queue of pages for each process.
- The optimal value of ∆ is unknown and in any case would vary.
- Figure 8.19: dots means hits, it it in the table
- similar to a cache hit
- Note: column 3, it can go less than 3, since the page reference are 18, 24, 18
- Found the principle of locality: program goes through this phase: insert picture, where you have stability for some time, then transition
- larger the working set → higher the hits (make sense)
You only look at what is not in your working set, basically the LRU policy. process can only execute if their working set is in the main memory
Problems:
- overhead happens when you have to track every page reference for every process
- …
Cleaning Policy
Cleaning Policy
A cleaning policy is the opposite of a fetch policy; it is concerned with determining when a modified page should be written out to secondary memory.
- Pre-cleaning:
- Policy writes modified pages before their page frames are needed so that pages can be written out in batches.
- Big risk:Write back pages that you shouldn’t
- Problem, a page is written out but remains in the main memory until the page replacement algorithm tells it to be removed.
- might be doing unnecessary writes since its done beforehand
- Allows writing of pages in batches, makes little sense tho
- Demand cleaning:
- A page is written out to secondary memory only when it has been selected for replacement.
A better approach incorporates page buffering. Clean only pages that are replaceable, but decouple the cleaning and replacement operations. With page buffering, replaced pages can be placed on two lists: modified and unmodified.
Load Control
Load Control
Basically wants to determine the number of processes that can have resident in main memory, which has been referred to as the multiprogramming level..
Critical in memory management. If too few few processes are resident at any one time, then there will be many occasions when all processes are blocked, and much time will be spent in swapping. On the other hand, if too many process, inadequate and frequent faulting which results to thrashing.
Multiprogramming Level Thrashing in figure 8.19: As multiprogramming level increases from small value, expect to see processor utilization rise, because there is less chance that all resident processes are blocked. However, a point is reached at which the average resident set is inadequate. At this point, the number of page faults rises dramatically, and processor utilization collapses.
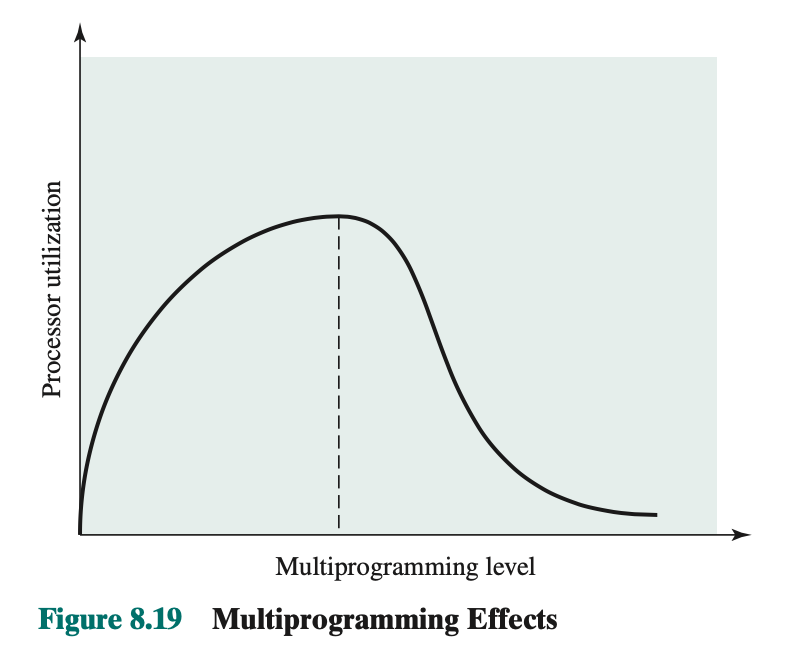
Approach to fix this problem:
- Only those processes with resident set is large enough are allowed to execute
- criterion
- Adapt the clock page replacement algorithm, technique using a global scope, that involves monitoring the rate at which the pointer scans the circular buffer of frames
Note: Processor utilization rises, but the actual performance goes down.
-
How do you figure out the spot, how many activity you should have and the number of processes and resident size for them
-
Not sure if it still works for modern architectures
-
But graph and idea still the same
-
Just know how to load, replace and remove (concept)
Not gonna ask us how to compute, and all the theory involved.
Process Suspension: in multiprogramming, decide which process to swap out (to be suspended). There are six possibilities:
- Lowers-priority process
- Faulting process
- Last process activated
- Process with the smallest resident set
- Largest process
- Process with the largest remaining execution window
Lecture 9 - Uniprocessor Scheduling
Basically Chapter 3 on steroids.
- Explain the differences among long-, medium-, and short-term scheduling.
- Assess the performance of different scheduling policies.
- Understand the scheduling technique used in traditional UNIX.
In Multiprogramming system, multiple processes exist concurrently in main memory. Each process alternates between using a processor and waiting for some event to occur, such as the completion of an I/O operation. The processor or processors are kept busy by executing one process while the others wait. The key to multiprogramming is scheduling.
Aim of Processor Scheduling
- Assign processes to be executed by the processor(s)
- Affect the performance, by determining which process will wait and which will progress
- Scheduler must meet objectives
- Response time
- Throughput
- Processor efficiency
- Temperature
- Power
- …
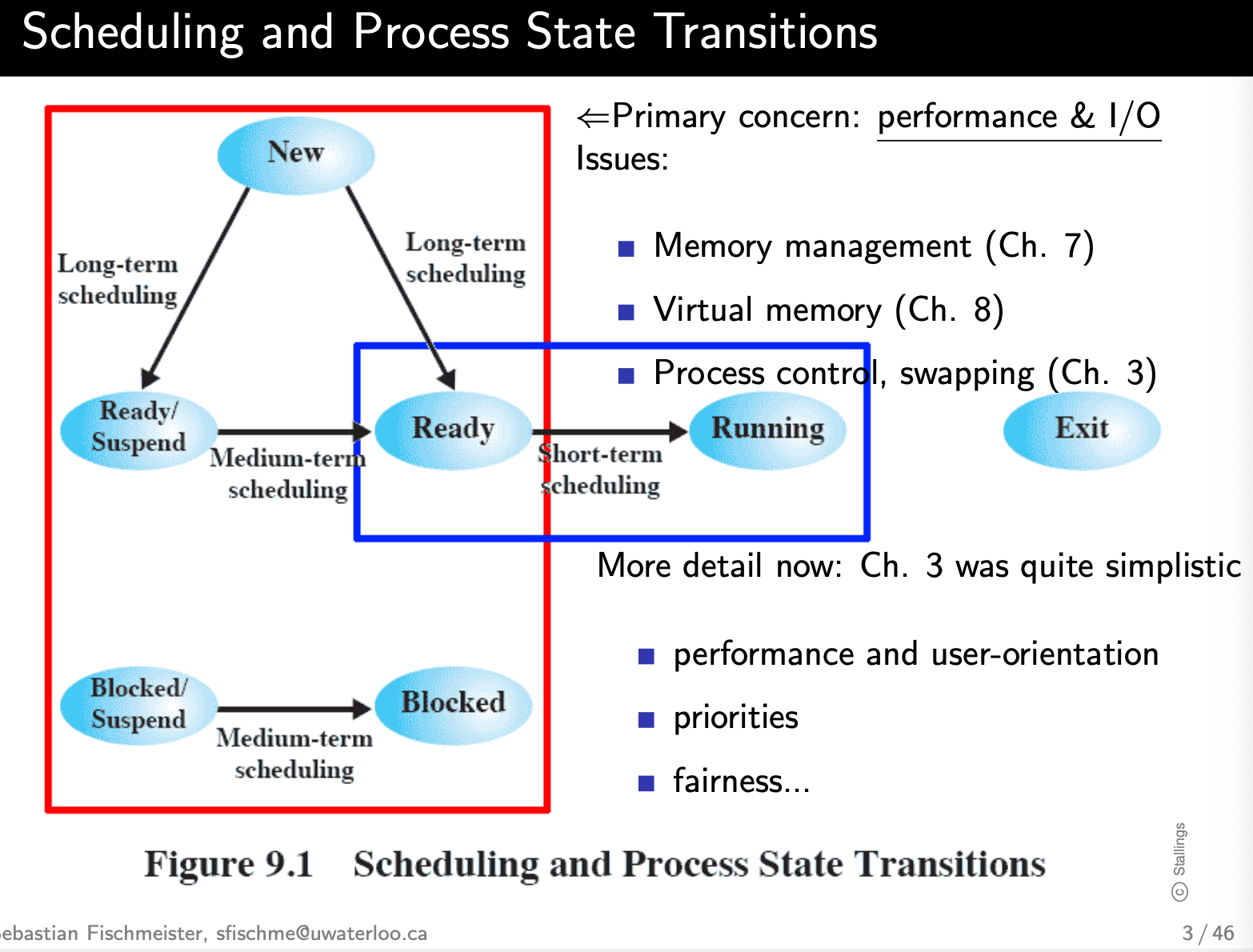
Types of Processor Scheduling

Fundamentally, scheduling is a matter of managing queues to minimize queueing delay and to optimize performance in a queueing environment.
Long-Term Scheduling
The long-term scheduler determines which programs are admitted to the system for processing. It controls the degree of multiprogramming.
New Ready, New Ready/suspend.
Once admitted, a job or user program becomes a process and is added to the queue for the short-term scheduler. Long-term scheduling is performed when a process is created.
The scheduler must decide when the OS can take on one or more additional processes.
The more processes that are created, the smaller is the percentage of time that each process can be executed (i.e., more processes are competing for the same amount of processor time). Thus, the long-term scheduler may limit the degree of multiprogramming to provide satisfactory service to the cur- rent set of processes.
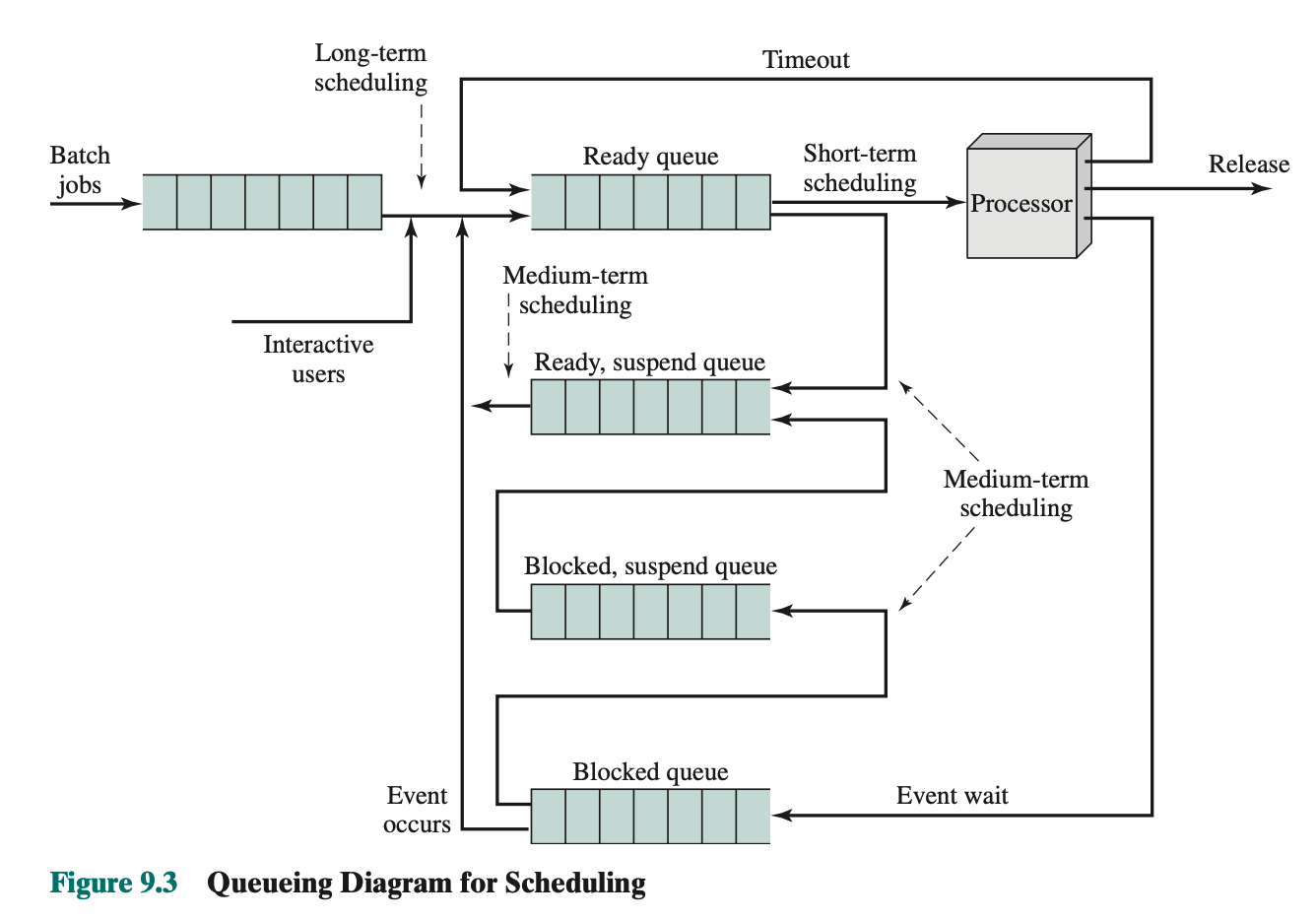
- Figure 9.3 diagram
- What is ready, suspended queue
- The decision as to when to create a new process is generally driven by the de- sired degree of multiprogramming. The more processes that are created, the smaller is the percentage of time that each process can be executed (i.e., more processes are competing for the same amount of processor time). Thus, the long-term scheduler may limit the degree of multiprogramming to provide satisfactory service to the cur- rent set of processes.
- The decision as to which job to admit next can be on a simple first-come- first-served (FCFS) basis, or it can be a tool to manage system performance. The criteria used may include priority, expected execution time, and I/O requirements.
Medium-Term Scheduling
Medium-term scheduling is part of the swapping function.
The issues involved are discussed in Chapters 3, 7, and 8. Typically, the swapping-in decision is based on the need to manage the degree of multiprogramming. On a system that does not use virtual memory, memory management is also an issue. Thus, the swapping-in decision will consider the memory requirements of the swapped-out processes.
Example: Block/suspend Blocked or Ready/suspend Ready.
Short-Term Scheduling
Also known as the dispatcher, executes most frequently and makes the fine-grained decision of which process to execute next.
Invoked whenever an event occurs that may lead to the blocking of the current process or that may provide an opportunity to preempt a currently running process. Examples:
- Clock interrupts
- I/O interrupts
- Operating system calls
- Signals (e.g., semaphores)
Actual decision of which ready process to execute next.
From Ready Running.
Scheduling Algorithms
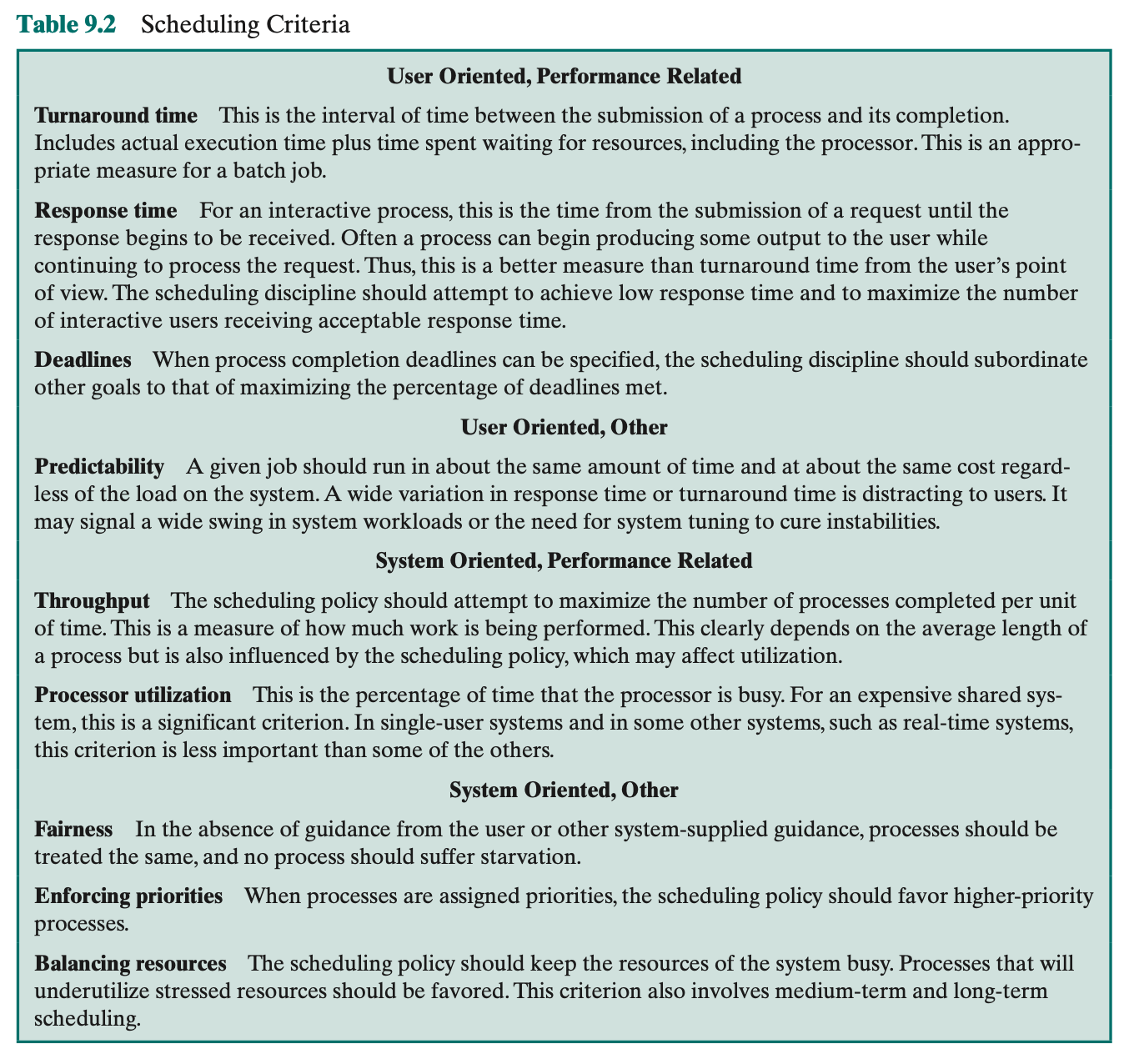
Short-Term Scheduling Criteria
Goal of short-term scheduling: allocate processor time to optimize one or more aspects of system behaviour. Two big category used criteria: user-oriented and system-oriented criteria.
- User-oriented criteria relate to the behaviour of the system as perceived by the individual user or process.
- In system oriented, that is, the focus is on effective and efficient utilization of the processor.
In most interactive operating systems, whether single user or time shared, ad- equate response time is the critical requirement
Summary:
In most interactive operating systems, whether single user or time shared, adequate response time is the critical requirement.
The Use of Priorities
In many systems, each process is assigned a priority and the scheduler will always choose a process of higher priority over one of lower priority.
Priorities:
- Scheduler will always choose a process of higher priority over one of lower priority
- Use multiple ready queues to represent multiple levels of priority
- Lower-priority may suffer starvation
- Allow a process to change its priority based on its age or execution history
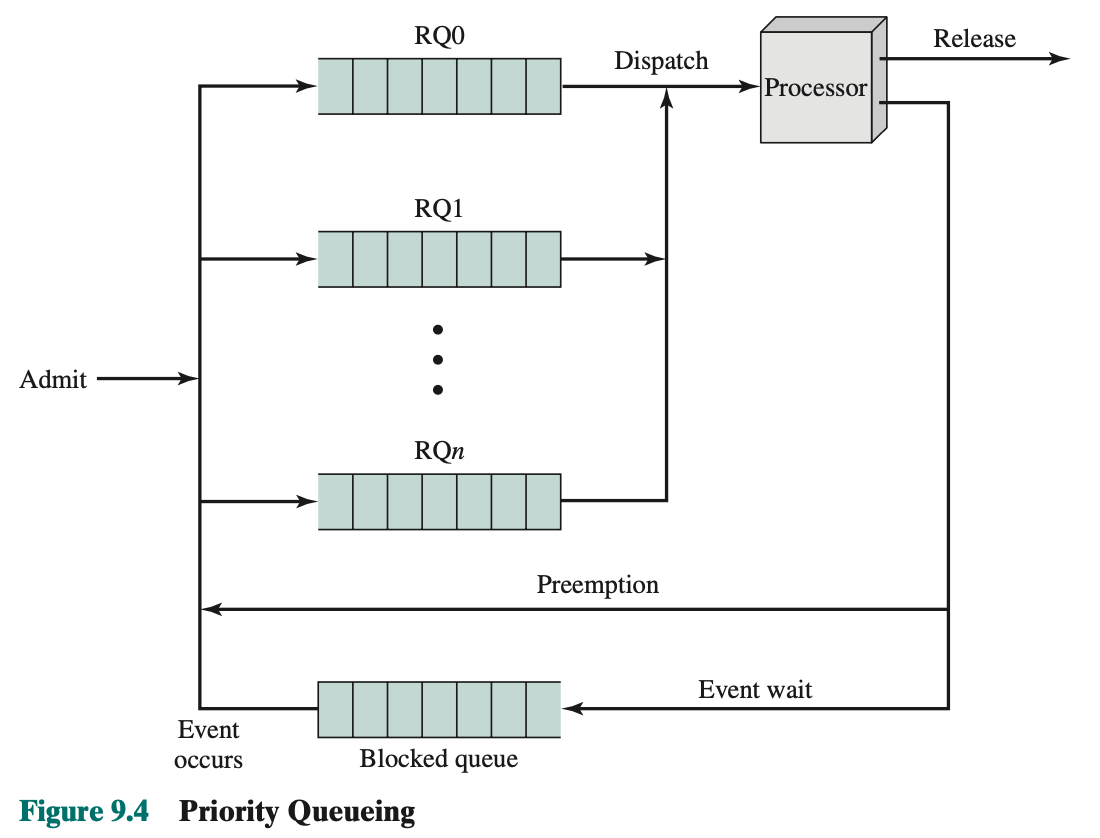
- Instead of a single queue, we have here a set of queues (in descending order of priority)
- When comes the time for scheduler to decide, it will start at the highest-priority ready queue.
- If there are one or more processes in the queue, a process is selected using some scheduling policy.
- If empty, we go to the next queue. For example, if RQ0 is empty, then RQ1 is examined, and so on.
- Problem: One problem with a pure priority scheduling scheme is that lower-priority processes may suffer starvation.
Alternative Scheduling Policies
The selection function determines which process, among ready processes, is selected next for execution. The function may be based on priority, resource requirements, or the execution characteristics of the process. In the latter case, three quantities are significant:
- = time spent in system so far, waiting
- time spent in execution so far
- total service time required by the process, including ; generally, this quantity must be estimated or supplied by the user
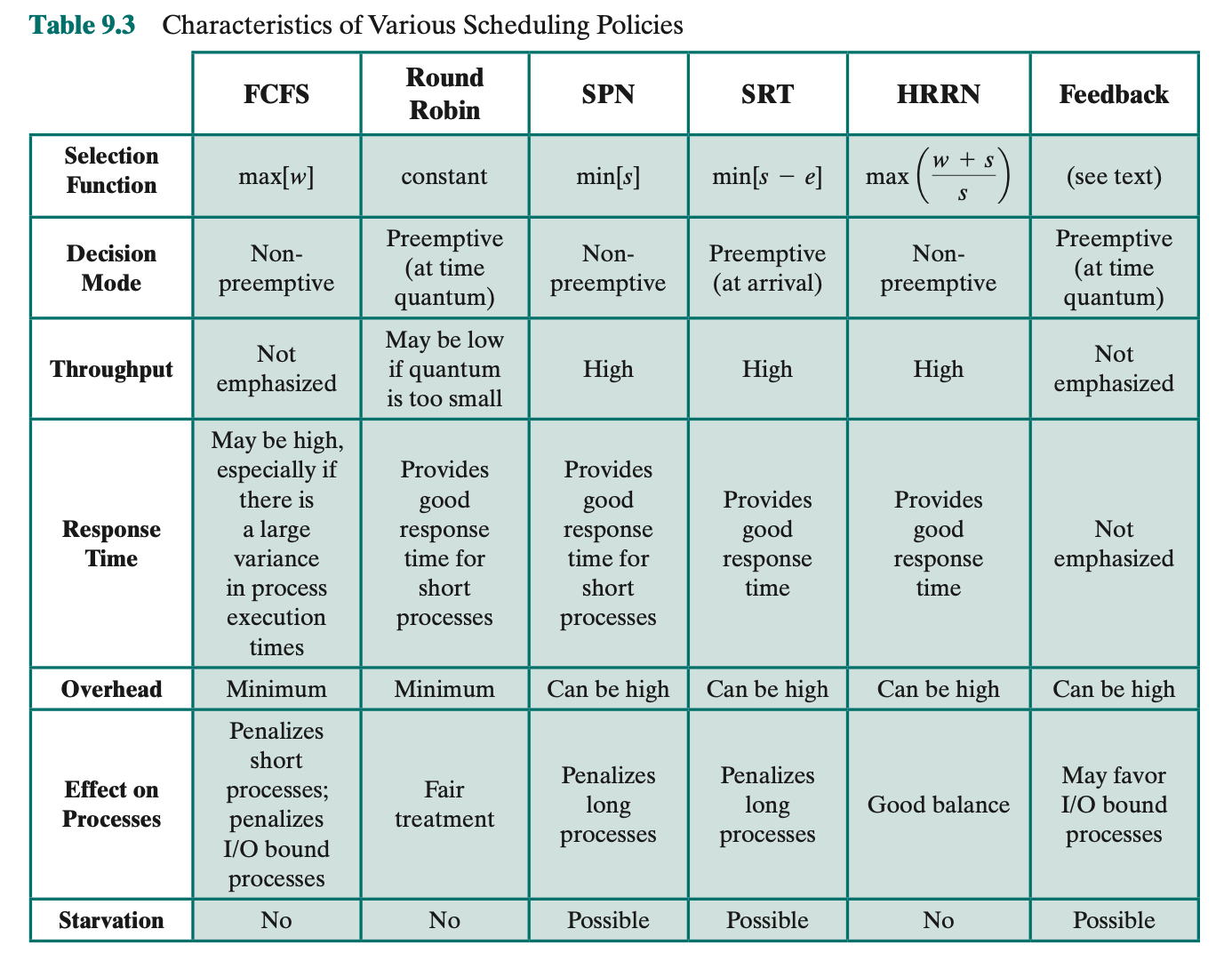
Decision Mode For Multiprogramming:
- Nonpreemptive
- Once a process is in the running state, it will continue until it terminates or blocks itself for I/O or to request some OS service.
- Preemptive
- Currently running process may be interrupted and moved to the Ready state by the operating system
- Allows for better service since any one process cannot monopolize the processor for very long
- The cost of preemption may be kept relatively low by using efficient process-switching mechanisms (as much help from hardware as possible) and by providing a large main memory to keep a high percentage of programs in main memory.
- Cooperative
Example:
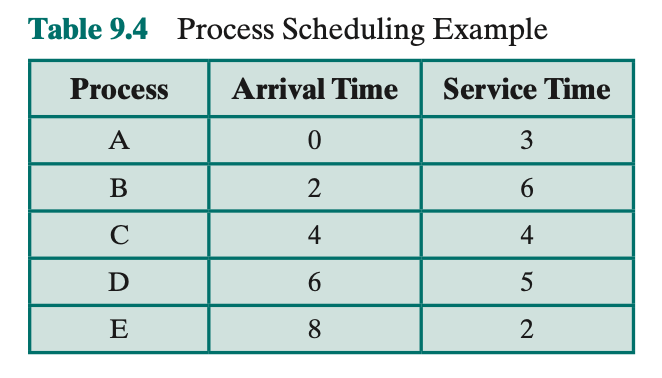
- Turnaround time (TAT) is the residence time , or total time that the item spends in the system (waiting time plus service time).
- the ratio of turnaround time to service time
- Typically, the longer the process execution time, the greater is the absolute amount of delay that can be tolerated
First-Come-First-Served (FCFS)
The simplest scheduling policy is first-come-first- served (FCFS), also known as first-in-first-out (FIFO) or a strict queueing scheme. As each process becomes ready, it joins the ready queue. When the currently running process ceases to execute, the process that has been in the ready queue the longest is selected for running.
Performs well for long processes than short ones.
- Each process joins the Ready queue
- When the current process ceases to execute, the oldest process in the Ready queue is selected
- A short process may have to wait a very long time before it can execute
- Good for computation-intensive processes
- Favours CPU-bound processes over I/O-bound processes
- I/O processes will block soon and then have to wait until CPU-bound process completes (don’t fully understand the explanation in the textbook, maybe because i’m in a hurry…)
Difficulty for FCFS: favours processor-bound processes over I/O bound processes.
- Consider that there is a collection of processes, one of which mostly uses the processor (processor bound) and a number of which favour I/O (I/O bound). When a processor-bound process is running, all of the I/O-bound processes must wait. Some of these may be in I/O queues (blocked state) but may move back to the ready queue while the processor-bound process is executing. At this point, most or all of the I/O devices may be idle, even though there is potentially work for them to do. When the currently running process leaves the Running state, the ready I/O-bound processes quickly move through the Running state and become blocked on I/O events. If the processor-bound process is also blocked, the processor becomes idle. Thus, FCFS may result in inefficient use of both the processor and the I/O devices.
FCFS is not an attractive alternative on its own for a uniprocessor system. However, it is often combined with a priority scheme to provide an effective scheduler. Scheduler may maintain a number of queues, one for each priority level, and dispatch within each queue on a first-come-first-served basis.
Round Robin
Use preemption based on a clock.
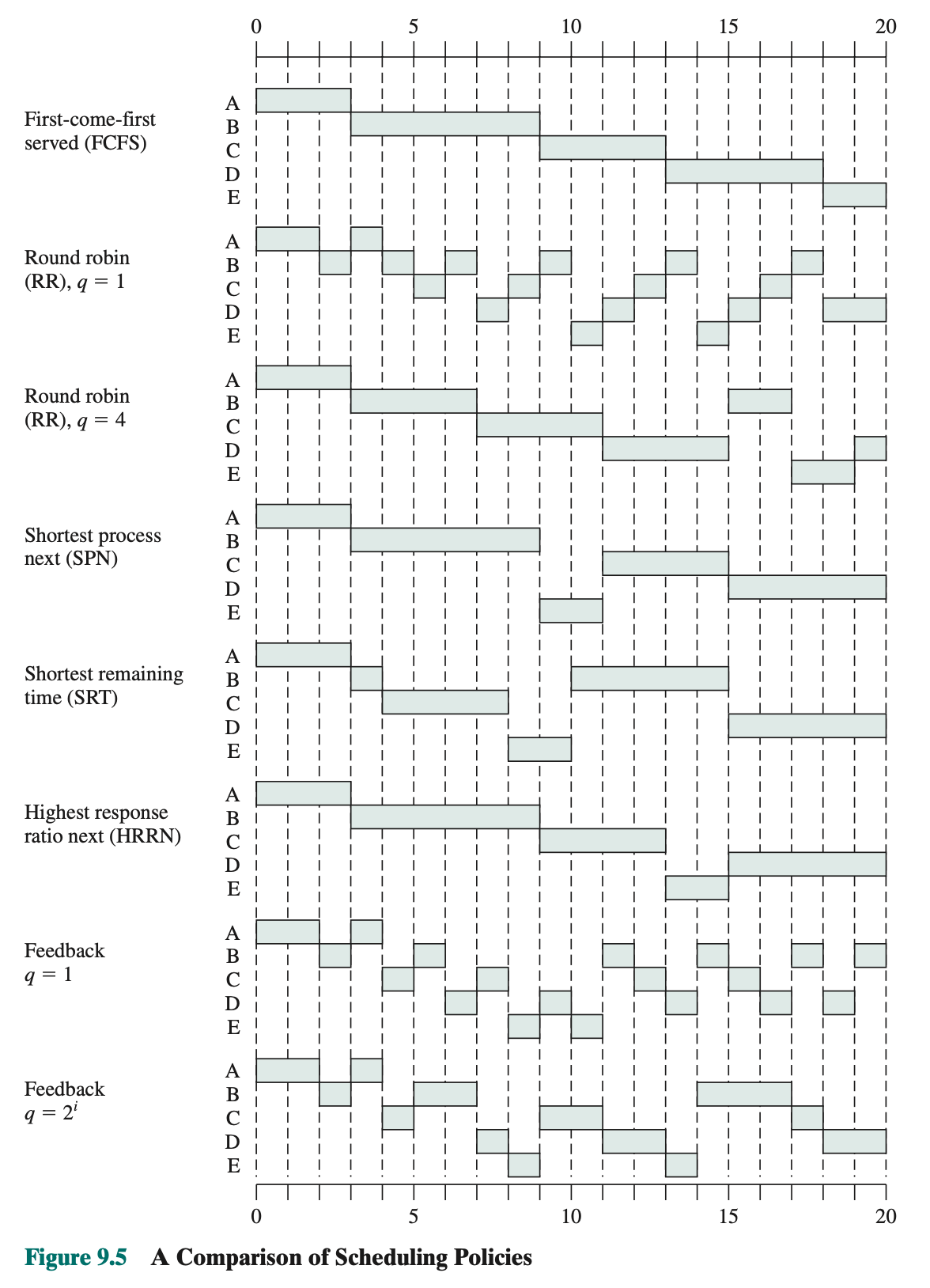
A clock interrupt is generated at periodic intervals. When the interrupt occurs, the currently running process is placed in the ready queue, and the next ready job is selected on a FCFS basis. This technique is also known as time slicing, because each process is given a slice of time before being preempted.
- With round robin, the principal design issue is the length of the time quantum, or slice, to be used.
- There is processing overhead involved in handling the clock interrupt and performing the scheduling and dispatching function. Thus, short time quanta should be avoided.
- The time quantum should be slightly greater than the time required for a typical interaction or process function
- Round robin is particularly effective in a general-purpose time-sharing system or transaction processing system.
- One drawback to round robin is its relative treatment of processor-bound and I/O-bound processes. If both exists, the following will happen:
- An I/O-bound process uses a processor for a short period and then is blocked for I/O; it waits for the I/O operation to complete and then joins the ready queue. On the other hand, a processor-bound process generally uses a complete time quantum while executing and immediately returns to the ready queue. Thus, processor-bound processes tend to receive an unfair portion of processor time, which results in poor performance for I/O-bound processes, inefficient use of I/O devices, and an increase in the variance of response time.gap-in-knowledge
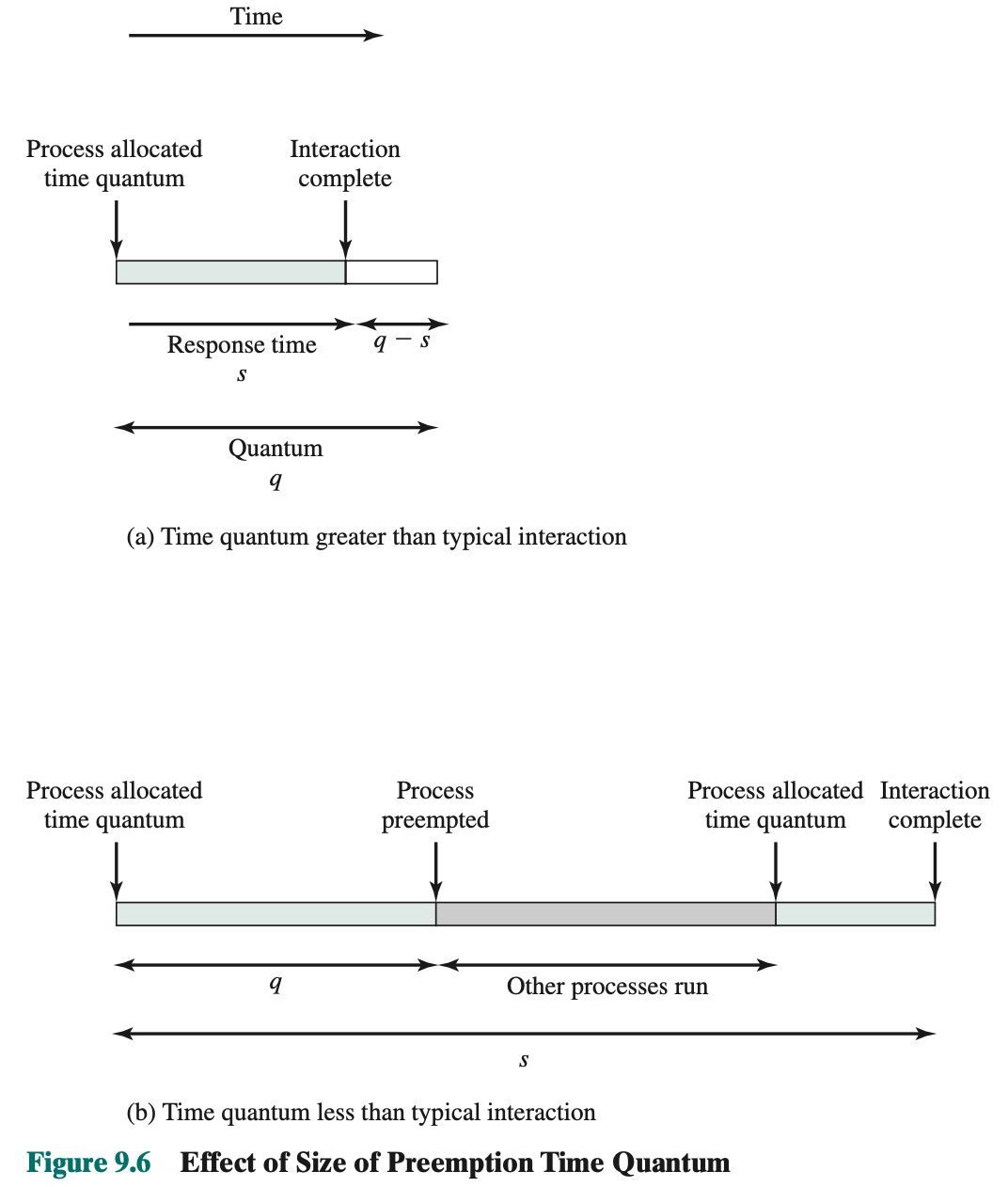
Virtual RR:
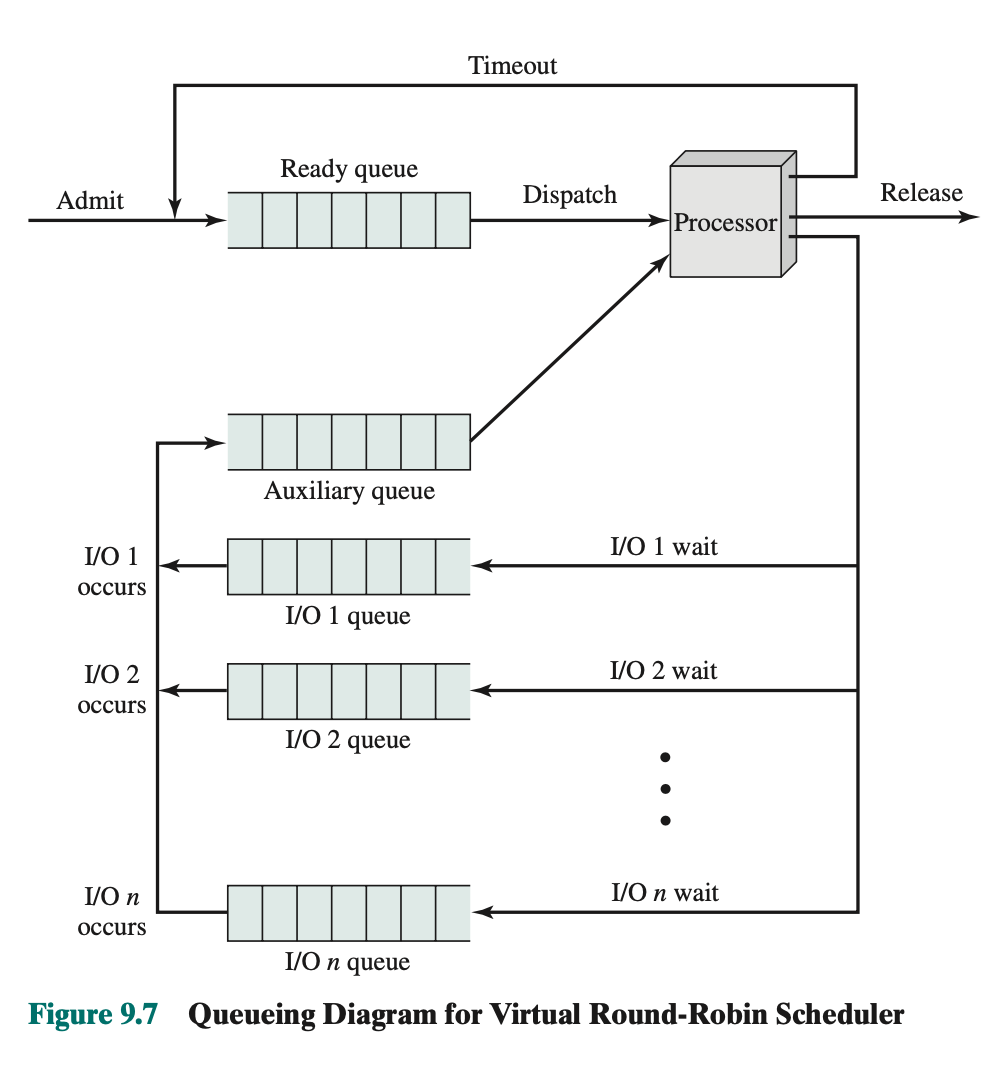
- Addition of this auxiliary queue
- The new feature is an FCFS auxiliary queue to which processes are moved after being released from an I/O block.
- When a dispatching decision is to be made, processes in the auxiliary queue get preference over those in the main ready queue.
- When a process is dispatched from the auxiliary queue, it runs no longer than a time equal to the basic time quantum minus the total time spent running since it was last selected from the main ready queue.
Stopped at slide 21/46
Wed Mar 6 - No Class
Mon Mar 10 - Quiz 3
Continue on slide 24/60.
Shortest Process Next (SPN)
- Nonpreemptive policy
- Process with shortest expected processing time is selected next
- Short process jumps ahead of longer processes

Difficulty:
- Need to know or at least estimate the required processing time of each process.
- For batch jobs, system may require the programmer to estimate the value and supply it to the OS. If the programmer’s estimate is substantially under the actual running time, the system may abort the job.
I skipped all the math in the textbook associated with SPN.
Use of Exponential Averaging
Shortest Reaming Time (SRT)
- Preemptive version of SPN policy
- Scheduler always chooses the process that has the shortest expected remaining process time.
- When a new process joins the ready queue, it may in fact have a shorter remaining time than the currently running process. Accordingly, the scheduler may preempt the current process when a new process becomes ready.
- Must estimate processing time just like SPN.
- Risk of Starvation of longer processes

Advantages and Disadvantages:
- Does not have bias in favour of long processes found in FCFS
- Unlike Round robin, no additional interrupts are generated, reducing overall overhead.
Another scheduling policy: Highest Response Ratio Next
- Choose next process with the greatest ratio
- Accounts for age and short processes (better ratio)
- Still requires knowing the service time
Ratio:
When the current process completes or is blocked, choose the ready process with the greatest value of R (response ratio). Just like SRT and SPN, expected service time (s) must be estimated.
Another policy: Feedback-based Scheduling
- Penalize jobs that have been running longer. Preference for shorter jobs.
- Don’t know remaining time process needs to execute
- Scheduling is done on a preemptive (at time quantum) basis, and a dynamic priority mechanism is used.
- When a process first enters the system, it is placed in RQ0. After its first preemption, when it returns to the Ready state, it is placed in RQ1.
- A short process will complete quickly, without migrating very far down the hierarchy of ready queues. A longer process will gradually drift downward. Thus, newer, shorter processes are favoured over older, longer processes.
- Within each queue, except the lowest-priority queue, a simple FCFS mechanism is used.
- Once in the lowest-priority queue, a process cannot go lower, but is returned to this queue repeatedly until it completes execution. Thus, this queue is treated in round-robin fashion.
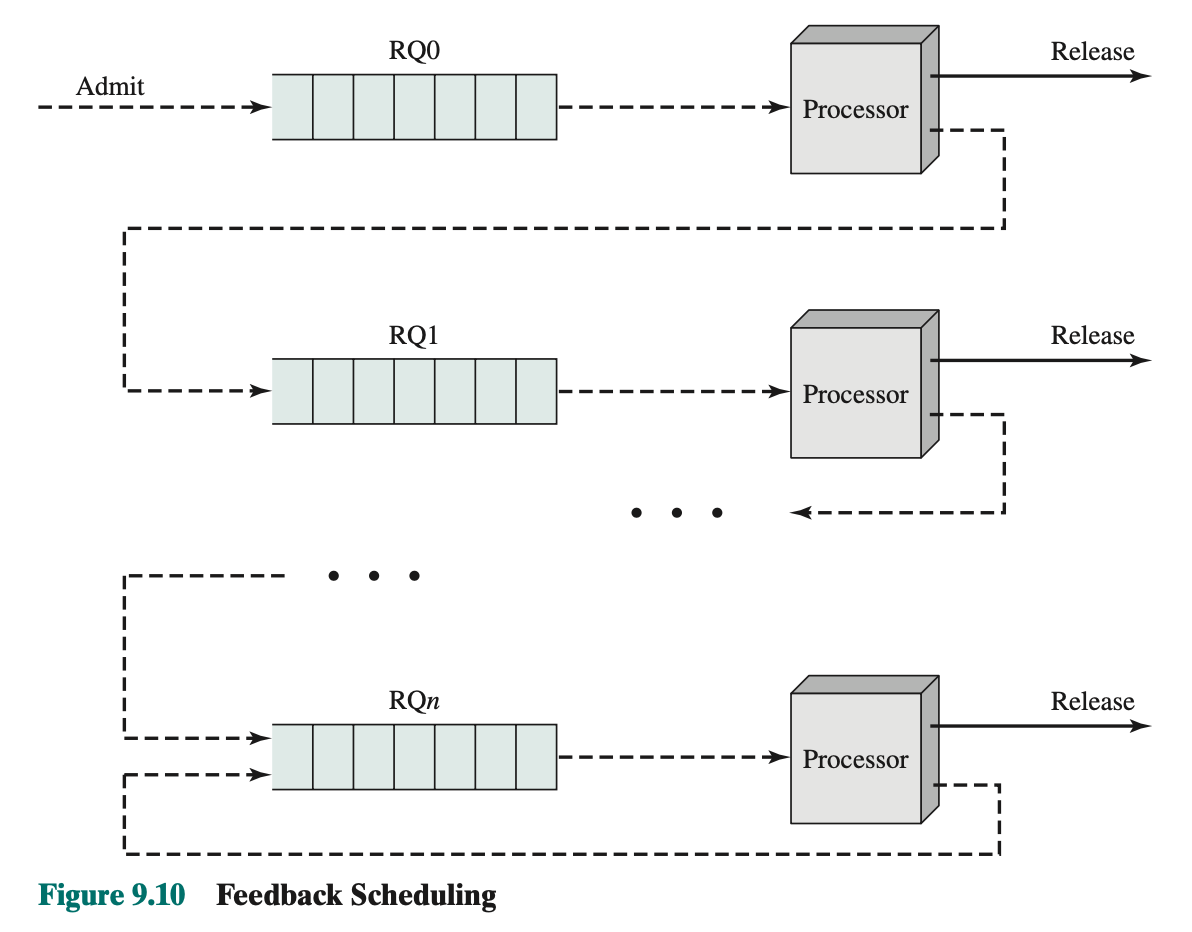
- Illustrate the feedback scheduling mechanism.
- This method known as multilevel feedback
- OS allocates the processor to a process and when the process blocks or is preempted, feeds it back into one of the several priority queues.
Problem with feedback:
- The turnaround time of longer processes can stretch out alarmingly.
- Possible for starvation to occur if new jobs are entering the system frequently.
- to fix, we can vary preemption time according to the different queue
- A process scheduled from RQ0 is allowed to execute for one time unit and then is preempted; a process scheduled from RQ1 is allowed to execute two time units, and so on. In general, a process scheduled from RQi is allowed to execute q = 2i time units before preemption. This scheme is illustrated for our example in Figure 9.5 and Table 9.5.
- to fix, we can vary preemption time according to the different queue
Understand the advantages and disadvantages of those scheduling policies: Table 9.5. Will not be asked about the theory.
Fair-Share Scheduling
All of the scheduling algorithms discussed so far treat the collection of ready processes as a single pool of processes from which to select the next running process. This pool may be broken down by priority but is otherwise homogeneous.
It would be attractive to make scheduling decisions on the basis of these process sets. Fair-share scheduling.
The concept can be extended to groups of users, even if each user is represented by a single process.
Example:
- in a time-sharing system, we might wish to consider all of the users from a given department to be members of the same group. Scheduling decisions could then be made that attempt to give each group similar service.
- Thus, if a large number of people from one department log onto the system, we would like to see response time degradation primarily affect members of that department rather than users from other departments.
Fair share: each user is assigned a weighting of some sort that defines that user’s share of system resources as a fraction of the total usage of those resources. Every user is assigned a share of the processor.

Figure 9.16
Figure 9.16 is an example in which process A is in one group and processes B and C are in a second group, with each group having a weighting of 0.5. Assume that all processes are processor bound and are usually ready to run. All processes have a base priority of 60. Processor utilization is measured as follows: The processor is interrupted 60 times per second; during each interrupt, the processor usage field of the currently running process is incremented, as is the corresponding group processor field. Once per second, priorities are recalculated.
In the figure, process A is scheduled first. At the end of one second, it is pre- empted. Processes B and C now have the higher priority, and process B is scheduled. At the end of the second time unit, process A has the highest priority. Note that the pattern repeats: The kernel schedules the processes in order: A, B, A, C, A, B, and so on
Thus, 50% of the processor is allocated to process A, which constitutes one group, and 50% to processes B and C, which constitute another group.
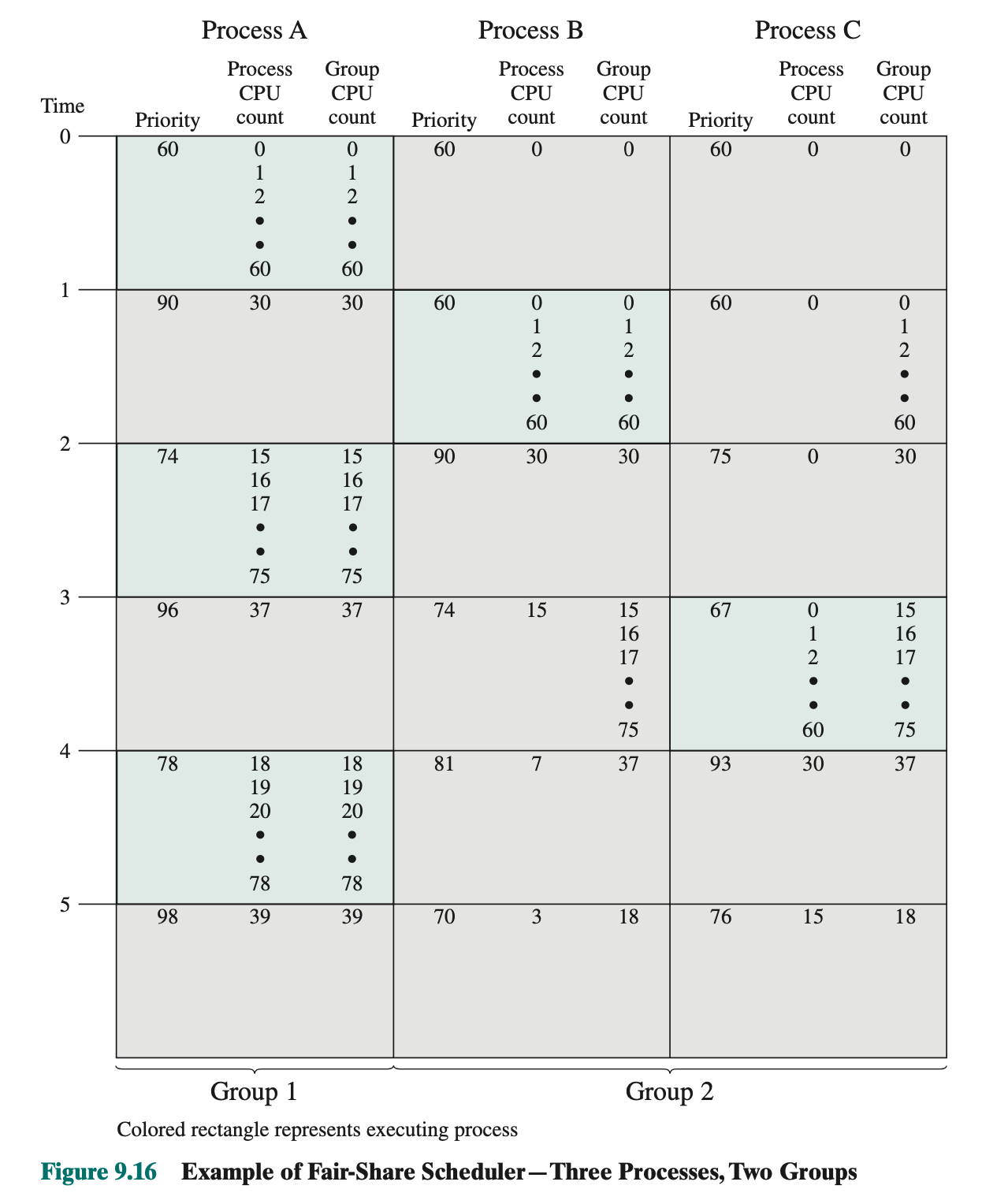
- we get 74, because run down integer
- If asked something, equation will be given, but need to know how the algorithm works
Traditional UNIX Scheduling
These systems are primarily targeted at the time-sharing interactive environment. The scheduling algorithm is designed to provide good response time for interactive users while ensuring that low-priority background jobs do not starve.
- Employs multilevel feedback using round robin within each of the priority queues
- If a running process does not block or complete within 1 second, it is preempted
- Priorities are recomputed once per second.
- That is, if a running process does not block or complete within one second, it is preempted
- Base priority divides all processes into fixed bands of priority levels
Purpose: divide all processes into fixed bands of priority levels. The CPU and nice components are restricted to prevent a process from migrating out of its assigned band (assigned by the base priority level). These bands are used to optimize access to block devices (e.g., disk) and to allow the OS to respond quickly to system calls. In decreasing order of priority, the bands are:
- Swapper
- Block I/O device control
- File manipulation
- Character I/O device control
- User processes
OS find automatic way to assign groups instead of letting the user do it.
Lecture 10 - Multiprocessor and Real-Time Scheduling
Scheduling of processes on a multiprocessor system.
Multiprocessor and Multicore Scheduling
Classifications of Multiprocessor Systems
- Loosely coupled or distributed multiprocessor, or cluster
- Functionality specialized processors
- Tightly coupled multiprocessor
Multicore = Multiprocessor for this course
Granularity
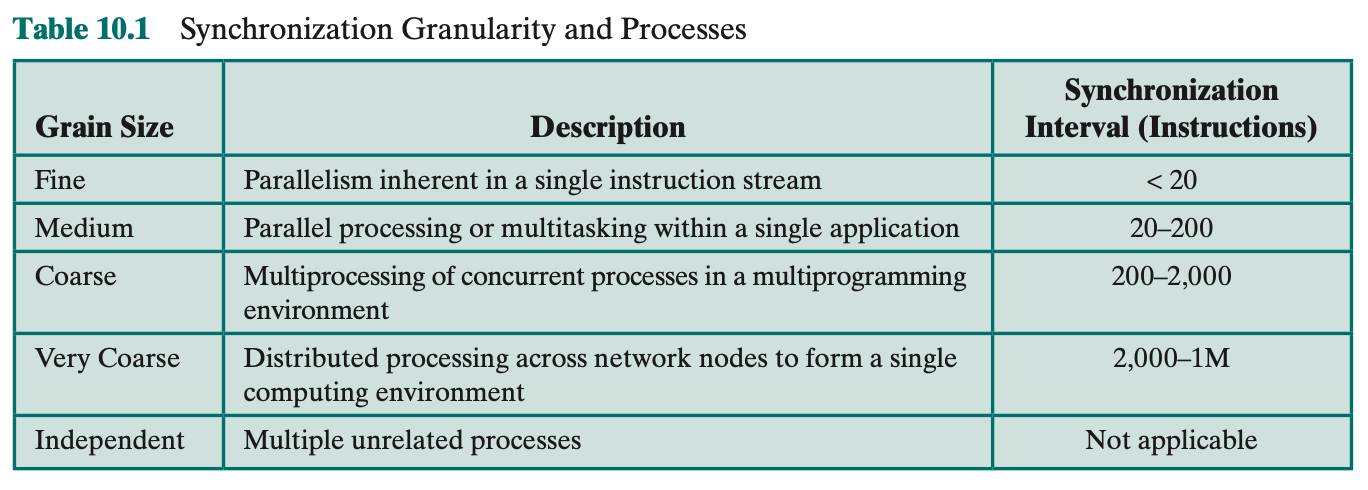
We can distinguish five categories of parallelism that differ in the degree of granularity. These are summarized in Table 10.1.
Independent Parallelism
- Processes are separate applications
- no synchronization among processes
- Example is time-sharing system
- Run word processing, shell, mail browser
- Properties similar to the uniprocessor system
Types of Parallelism
Coarse and Very Coarse-Grained Parallelism
- Distributed processing across network nodes
- Multiprocessing of concurrent processes in a multiprogramming environment
- Little synchronization among processes
- Good for concurrent processes running on a multiprogrammed uniprocessor
- Can by supported on a multiprocessor with little change
Medium-Grained Parallelism
- Parallel processing or multitasking within a single application
- Threads usually interact frequently and share data
- requires synchronization
- Scheduling decisions regarding one thread might affect the performance of the entire application
Multiprogrammed uniprocessor vs. multiprocessor with little or no impact on scheduling of threads???
Fine-Grained Parallelism
- Fine-grained parallelism represents a much more complex use of parallelism than is found in the use of threads
- Parallelism inherent in a single instruction stream
- Highly parallel applications
Design Issues
Scheduling on a multiprocessor involves three interrelated issues (scheduler needs to consider):
- Assignment of processes to processors
- Use of multiprogramming on individual processors
- Actual dispatching of a process
How to assign processes to processors?
- Two architectural styles:
-
- Multiprocessor is uniform
- Multiprocessor is heterogeneous
-
- Assuming architectural style 1:
- a) Assign processes to a dedicated processor
- b) Migrate processes between processors
- Style 2 requires special software
Assignment of Processes to Processors
-
We have Round-Robin:
-
Static Assignment
- You get an assignment, you decide which one to give it too
- Non-preemptive
- Problem: one processor will maybe get longer assignments so will be more busy than the other processes.
-
You can also only have one queue for multiple processes
- Advantages: Either processes will be executing whatever is available
- Disadvantages:
- Race condition when both processes try to access the queue and select the next assignment.
- Cold cache problem
-
Hybrid method, where if the queues meet a certain condition, it can get re-evaluated and put it in the general queue to be assigned to a queue.
Insert slide 11/58
Another method is dynamic loading (two approaches):
- master/slave architecture
- Key kernel functions always run on a particular processor ( RTLinux design)
- Master is responsible for scheduling
- Slave sends service request to master and waits for result
- Advantages:
- simple and need little enhancement to a uniprocessor multiprogramming OS (similar to uniprocessor)
- Resolves conflict (simplified) since one processor has control of all memory and I/O resources
- Disadvantages (2):
- A failure of the master brings down whole system
- Master can become a performance bottleneck
- Peer architecture
- Kernel can execute on any processor
- Each processor does self-scheduling
- Complicates the OS
- Make sure two processors don’t choose the same process
- And that the processes are not lost from the queue
Multiprogramming (on individual processor)
- When each process is statically assigned to a processor for duration of its life time: Do we still need multiprogramming in a multiprocessor environment?
- Consider an 80 core machine
- No definitive answer. Advantages and disadvantages exist.
- Low system overhead, less complexity
- Btw. in-application concurrency still necessary
- That is an application that consists of a number of threads may run poorly unless all of its threads are available to run simultaneously.
Process Dispatching
- Do we still require sophisticated concepts to guide the scheduling decisions?
- Complex scheduling algorithms
- Priorities
- Feedback queues
- Compute metrics at run time
- Some are unnecessary and even counter productive ⇒ active area of research
Wed Mar 20 2024: Continues on slide 19/58
Prof skipped the Process Scheduling section in the textbook?!?!?!
There is no slides on it…
Process Scheduling
Typically, in multiprocessor systems, there is a dedicated queue for all processes and processes are not dedicated to any particular processor. Single queue for all processors, if there are priority schemes, then there are multiple queues based on priority all feeding into the common pool of processors.
Include the comparison pictures of one and two processors
Conclusion
Apparently the takeaway is that the specific scheduling discipline is much less important with two processors than with one. Stronger as the number of processors increases. Thus, a simple FCFS discipline or use of FCFS with a static priority schemes suffice for multiple-processor system.
Thread Scheduling
- Separate execution from resource ownership
- In multiprocessor system: threads can be used to realize true parallelism in an application.
- An application consists of multiple cooperating, concurrently-executing threads
- For applications that require significant interaction among threads (medium-grain parallelism), small differences in thread management and scheduling can have huge performance impact!!
- Multiprocessor: True parallelism (unlike the fake multiprogramming on a uniprocessor with time-sharing giving the illusion of parallel programming…)
- Uniprocessor:
- Program structuring aid
- Overlap I/O with processing
- Low management overhead (compared to MP)
Four general approaches:
- Load sharing
- Processes are not assigned to a particular processor
- Load sharing vs load balancing
- load sharing allowing processes to go back into the queue and go somewhere else?
- Gang scheduling
- A set of related threads is scheduled to run on a set of processors at the same time
- Advantages: You can run them together at the same time. Good for synchronization or something like that, explained on next few slides.
- Dedicated processor assignment
- Threads are assigned to a specific processor
- Each program, for its execution, is assigned a number of processors that is equal to the number of threads in the program.
- Dynamic scheduling
- Number of threads can be altered during course of execution
Load Sharing
-
Global queue, processor picks process
-
Load is distributed evenly across the processors
-
Advantages:
- No processor is left idle while there are processes available.
- No centralized scheduler required
- Transparent for the developer. ????
- Global queue can be organized and accessed using any of the schemes discussed in Chapter 9, including priority based schemes
-
Disadvantage:
- Central queue needs mutual exclusion
- When a lot of processes want to access the queue. Becomes a problem when there is a large number of processors. Especially when the multiprocessor consists of dozens or hundreds of processors ⇒ bottleneck
- Preemptive threads are unlikely to resume execution on the same processor (cache misses)
- If all threads are in the global queue, all threads of a program will not gain access to the processors at the same time
- Central queue needs mutual exclusion
The global queue can be organized and accessed using any of the schemas, FCFS, Smallest number of threads first or preemptive smallest number of threads first.
Gang Scheduling
Concept of scheduling a set of processes simultaneously on a set of processors predates the use of threads.
- Threads often need to synchronize with each other
- ⇒ run multiple threads to together
- Simultaneous scheduling of threads that make up a single process
- Useful for applications where performance severely degrades when any part of the application is not running
According to author
Gang scheduling is generally superior to load sharing.
- Advantages
- Reduce scheduling overhead, since they a single scheduling decision is used.
- Less process switching and performance increases.
- For example, multiple gang-scheduled threads can access a file without the additional overhead of locking during a seek, read/write operation.
The use of gang scheduling creates a requirement for processor allocation.
Processor Allocation
- Gang scheduling can lead to inefficient use of the multiprocessor
- Group independent threads into groups
- Use weights in the scheduling algorithm
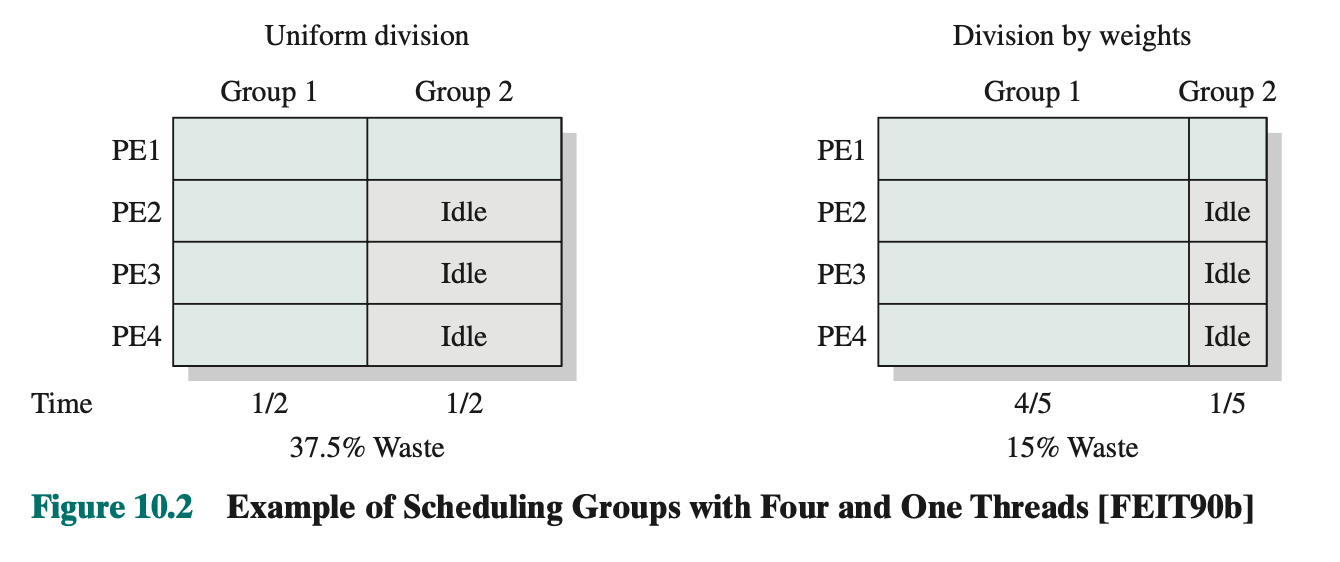
Dedicated Processor Assignment
An extreme form of gang scheduling is to dedicate a group of processors to an application for the duration of the application. When an application is scheduled, each of its thread is assigned a processor that remains dedicated to that thread until the application runs to completion
- Dedicate thread groups to processors until application completes
- No multiprogramming of processors!!
- Looks bad: extremely wasteful
- If a thread is blocked waiting for I/O or for synchronization with another thread, then that thread’s processor remains idle
- However:
- Assume 1000 processor cores
- In highly parallel system, each processors represents a small fraction of the cost of system, so processor utilization no longer important metric for performance
- Zero overhead
- Avoids process switching which can speedup program
Management overhead involved so application cannot speedup forever. Refer to the graph. Initial increase of the application as the threads
- Number of threads in a process are altered dynamically by the application
- Requires a layer of indirection which maps computation tasks to threads
Activity Working Set
The minimum number of activities (threads) that must be scheduled simultaneously on processors for the application to make acceptable progress.
Failing can lead to processor thrashing.
Dynamic Scheduling
- Number of threads in a process are altered dynamically by the application
- Requires a layer of indirection which maps computation tasks to threads
OS responsible for partitioning the processors among the jobs. Decision on which to run as well as which thread to suspend when a process is preempted, is left to the individual applications.
The scheduling responsibility of the operating system is primarily limited to processor allocation.
Do we need to know Multicore Thread Scheduling??
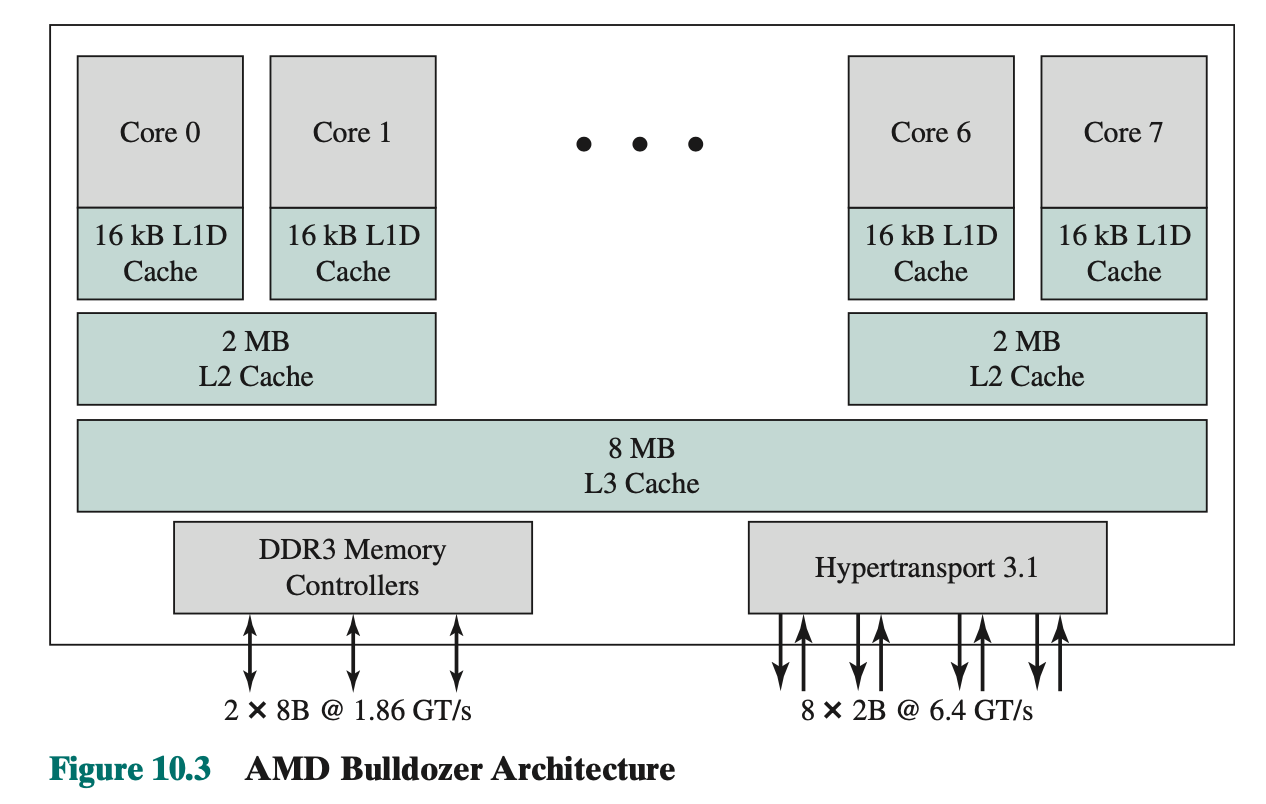
- Multicore Thread Scheduling
- In this architecture, each core has a dedicated L1 cache; each pair of cores share an L2 cache; and all cores share an L3 cache. Compare this with the Intel Core i7-990X (Figure 1.20), in which both L1 and L2 caches are dedicated to a single core.
- When some but not all cores share a cache, the way in which threads are allocated to cores during scheduling has a significant effect on performance.
- Ideally, if two threads are going to share memory resources, they should be assigned to adjacent cores to improve the effects of locality, and if they do not share memory resources they may be assigned to nonadjacent cores to achieve load balance.
- Two different aspects of cache sharing to take into account: cooperative resource sharing and resource contention.
- The objective of contention-aware scheduling is to allocate threads to cores in such a way as to maximize the effectiveness of the shared cache memory and therefore to minimize the need for off-chip memory accesses.
10.2 Real-Time Scheduling
Real-time computing may be defined as that type of computing in which the correctness of the system depends not only on the logical result of the computation but also on the time at which the results are produced.
- Correctness of the system depends on
- Logic behaviour
- Timing
- A correct value at the wrong time is a fault.
- Tasks or processes attempt to control or react to events that take place in the outside world
- These events occur in real time and tasks must be able to keep up with them
Properties of RT Systems
Real time tasks:
-
hard real-time task: must meet its deadline, otherwise cause damage or fatal error to system
-
soft real-time task: has an associated deadline that is desirable, but not mandatory. Still makes sense to schedule and complete the task even if it has passed its deadline.
-
aperiodic task: has a deadline by which it must finish or start, or it may have a constraint on both start and finish time.
-
periodic task: requirements may be stated as “once per period ” or “exactly unit apart”
-
Real time is about producing the correct result at the right time.
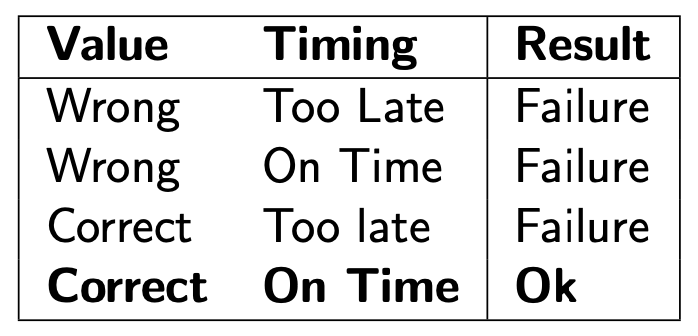
-
Temporal constraints are a way to specify, when the value is on time.
Soft Temporal and Hard Temporal System Constraints
- A soft real-time system is one where the response time is normally specified as an average value. This time is normally dictated by the business or market
- A single computation arriving late is not significant to the operation of the system, though many late arrivals might be.
- Ex: Airline reservation system: If a single computation is late, the system’s response time may lab. However, the only consequence would be a frustrated potential passenger.
Hard Temporal Constraints
Firm Temporal Constraints
Characteristics:
for example: aircrafts does not have fail-safe.
Hard to create fail-silent systems
Features of Real-Time OS
- Fast process or thread switch
- Small size
- choose smallest processor to achieve the functionality of the system
- Ability to respond to external interrupts quickly
- Multitasking with interprocess communication tools such as semaphores, signals, and events
- Use of special sequential files that can accumulate data at a fast rate
- Preemptive scheduling based on priority
- Minimization of intervals during which interrupts are disabled
- Delay tasks for fixed amount of time
- Special alarms and timeouts
Real-Time Scheduling
- Static table-driven
- Determines at run time when a task begins execution
- Applicable to tasks that are periodic
- Scheduler attempts to develop a schedule that enables it to meet the requirements of all periodic tasks
- Inflexible
- Earliest-deadline-first or other periodic techniques are in this category of scheduling algo.
- Static priority-driven preemptive
- Traditional priority-driven scheduler is used
- No schedule is drawn up?
- Analysis used to assign priorities to tasks
- Makes use of the priority-driven preemptive scheduling mechanism common to most non-real-time multiprogram- ming systems.
- Time-sharing system, the priority of a process changes depending on whether it is processor bound or I/O bound. In a real-time system, priority assignment is related to the time constraints associated with each task.
- Dynamic planning-based
- Feasibility determined at run time
- An arriving task is accepted for execution only if it is feasible to meet its time constraints.
- After a task arrives, but before its execution begins, an attempt is made to create a schedule that contains the previously scheduled tasks as well as the new arrival
- Dynamic best effort
- No feasibility analysis is performed
- The system tries to meet all deadlines and aborts any started process whose deadline is missed.
- When a task arrives, the system assigns a priority based on the characteristics of the task.
- Form of deadline scheduling, such as earliest-deadline scheduling is used.
- Disadvantage:
- With this type of scheduling, until a deadline arrives or until the task completes, we do not know whether a timing constraint will be met.
- Advantage:
- Easy to implement.
Deadline Scheduling
- Real-time applications are not concerned with speed but with completing tasks
- Just care if it meets the deadline.
- Information used
- Ready time
- Time at which task becomes ready for execution.
- Time known for repetitive or periodic tasks.
- Starting deadline
- Time by which a task must begin
- Completion deadline
- Time by which a task must be complete.
- Processing time
- Time required to execute the task to completion.
- Resource requirements
- Set of resources (other than processor) required by the task while it is executing.
- Priority
- Measures relative importance of the task.
- Hard real-time tasks may have an “absolute” priority, with the system failing if a deadline is missed.
- Subtask scheduler (structure)
- A task may be decomposed into a mandatory subtask and an optional subtask.
- Only the mandatory subtask possesses a hard deadline.
- Ready time
Earliest deadline
A policy of scheduling the task with the earliest deadline minimizes the fraction of tasks that miss their deadlines. This conclusion holds for both single-processor and multiprocessor configurations
As an example of scheduling periodic tasks with completion deadlines
Consider a system that collects and processes data from two sensors, A and B.
Deadline for collecting data from sensor A must be met every 20 ms, and that for B every 50 ms. (Ending deadline column) It takes 10 ms, including operating system overhead, to process each sample of data from A and 25 ms to process each sample of data from B. (Execution time column)
Figure 10.5 compares three scheduling techniques using the execution profile of Table 10.3:
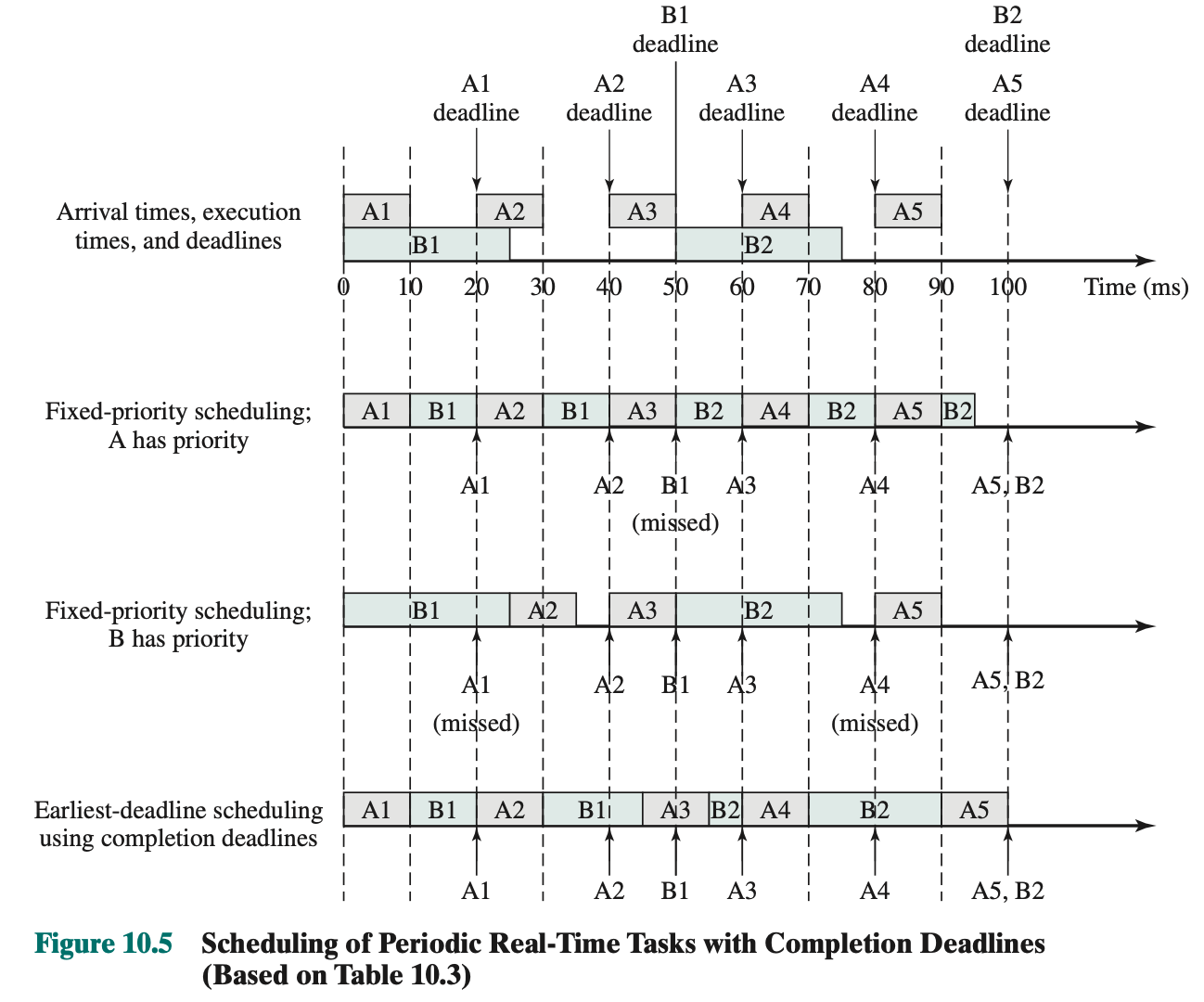
- A priority
- the first instance of task B is given only 20 ms of processing time, in two 10-ms chunks, by the time its deadline is reached, and thus fails.
- Since B1’s deadline has arrived, and we still have 5ms of execution time left on B1…
- B priority
- A will miss its first deadline
- Earliest-deadline scheduling (last row)
- At time t = 0, both A1 and B1 arrive
- Because A1 has the earliest deadline, it is scheduled first.
- At t = 20, A2 arrives. Because A2 has an earlier deadline than B1, B1 is interrupted so that A2 can execute to completion.
- B1 is resumed at t = 30.
- At t = 40, A3 arrives.
- However, B1 has an earlier ending deadline and is allowed to execute to completion at t = 45.
- A3 is then given the processor and finishes at t = 55.
Aperiodic tasks with starting deadlines
The top part of Figure 10.6 shows the arrival times and starting deadlines for an example consisting of five tasks each of which has an execution time of 20 ms. Table 10.4 summarizes the execution profile of the five tasks.
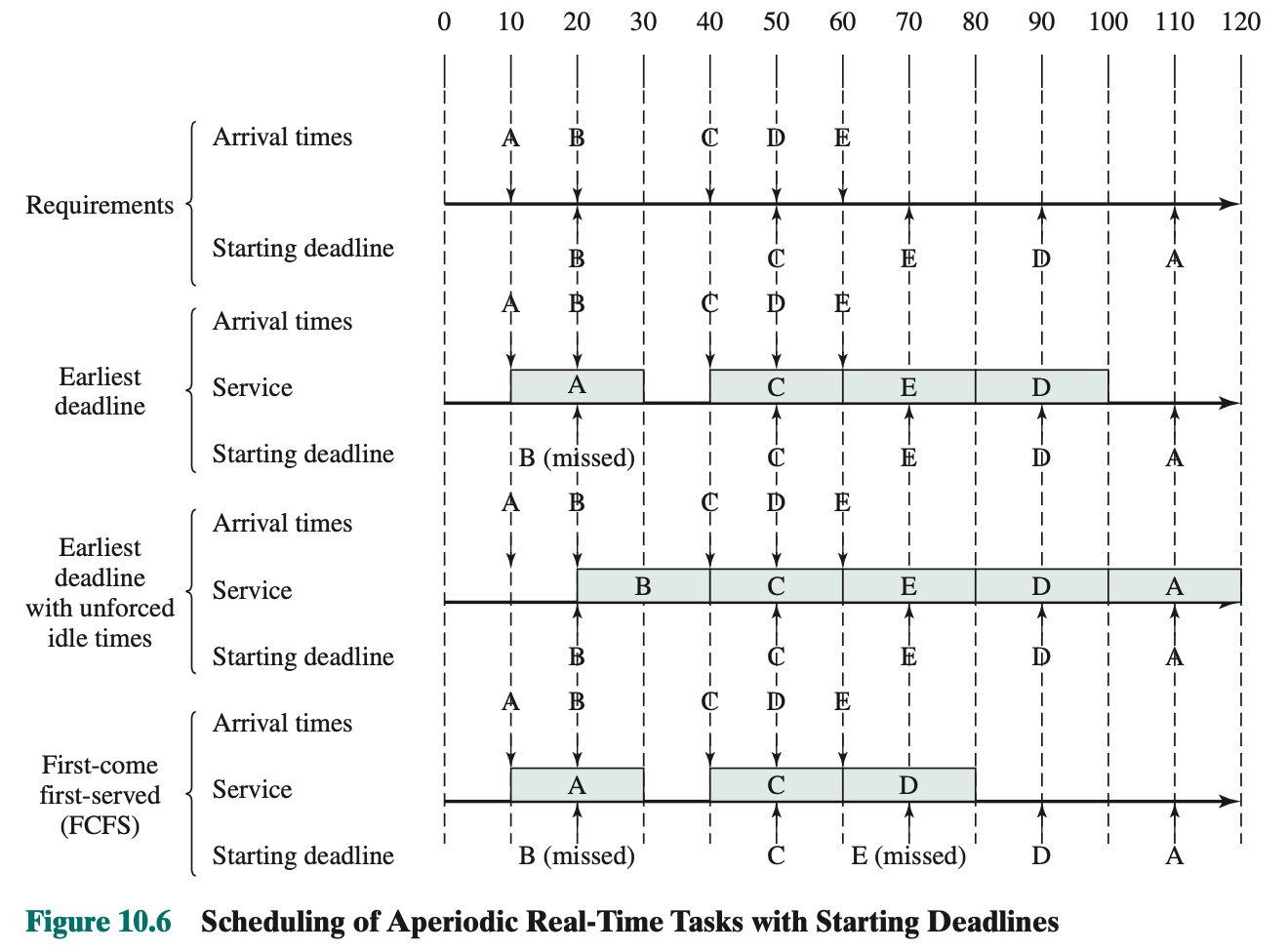
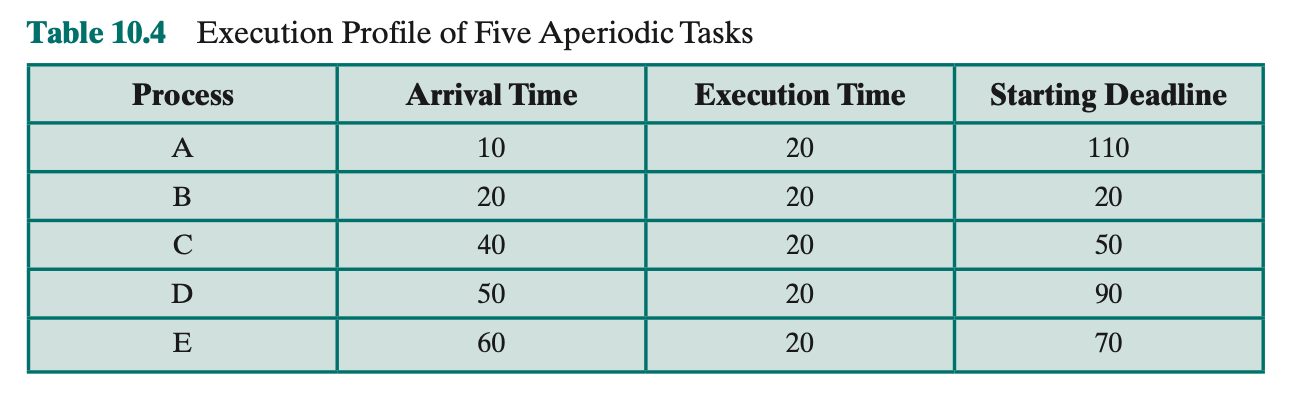
- Earliest deadline
- Although task B requires immediate service, the service is denied.
- This is the risk in dealing with aperiodic tasks, especially with starting deadlines.
- Earliest deadline with unforced idle times, operates as follows
- Always schedule the eligible task with the earliest deadline and let that task run to completion.
- An eligible task may not be ready, and this may result in the processor remaining idle even though there are ready tasks.
- Note that in our example the system refrains from scheduling task A even though that is the only ready task.
- The result is that, even though the processor is not used to maximum efficiency, all scheduling requirements are met.
- FCFS
- Tasks B and E do not meet their deadlines.
Rate Monotonic Scheduling
One of the more promising methods of resolving multitask scheduling conflicts for periodic tasks is rate monotonic scheduling (RMS).
RMS assigns priorities to tasks on the basis of their periods. For RMS, the highest-priority task is the one with the shortest period, the second highest-priority task is the one with the second shortest period, etc.
When more than one task is available for execution, the one with the shortest period is serviced first.
Plot priority of tasks as function of their rate:
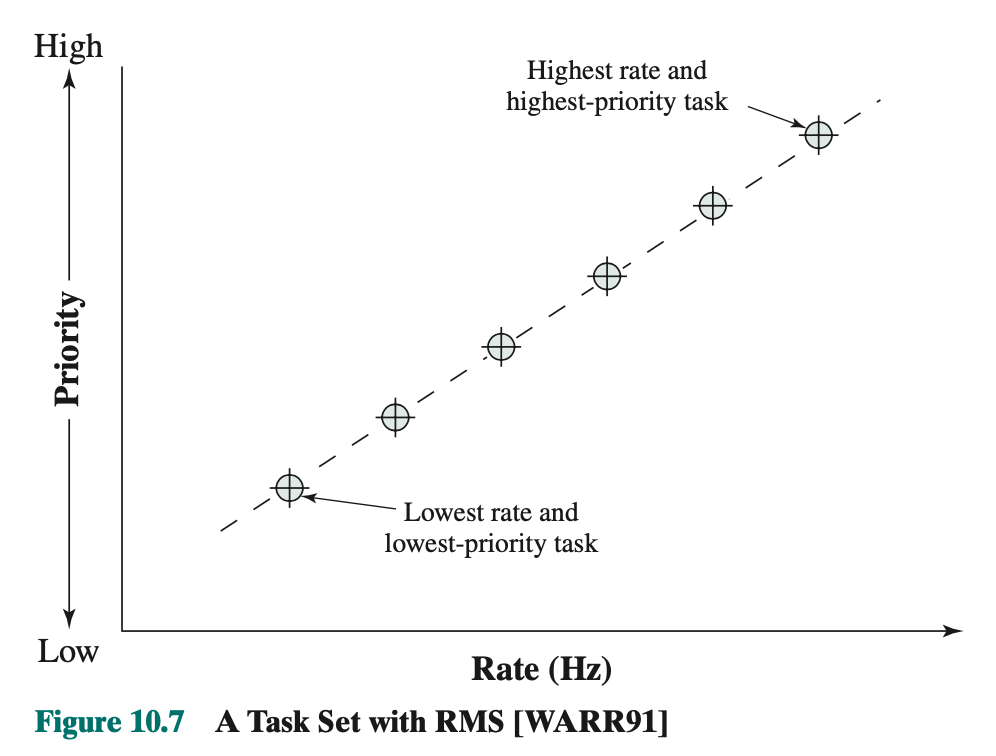
Parameters for periodic tasks:
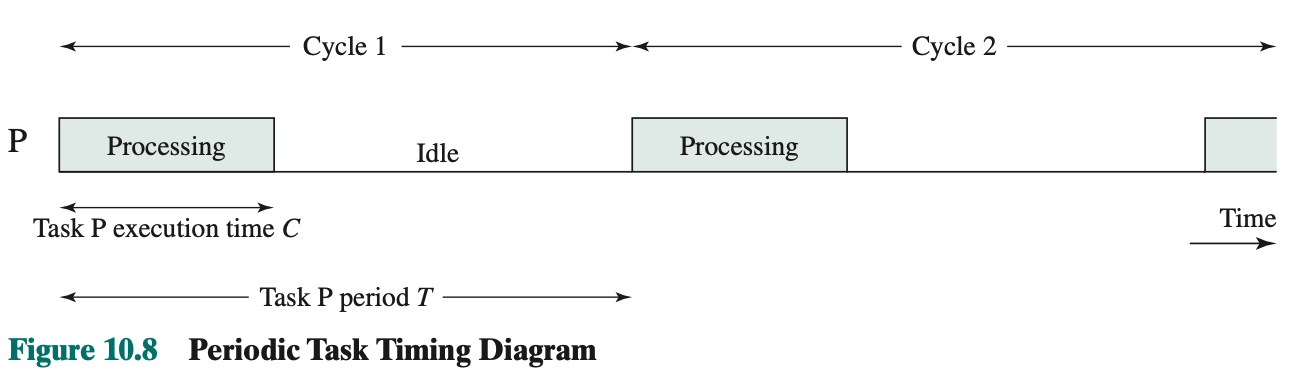
- Task period is the amount of time between the arrival of one instance of the task and the arrival of the next instance of the task.
- Task rate (hertz) is the inverse of its period (in seconds).
- For example:
- periodic task is always run to completion, then the utilization of the processor by this task is U = C/T. For example, if a task has a period of 80 ms and an execution time of 55 ms, its processor utilization is 55/80 = 0.6875.
The sum of the processor utilizations of the individual tasks cannot exceed a value of 1, which corresponds to total utilization of the processor.
It can also be shown that the upper bound of Equation (10.1) holds for earliest- deadline scheduling. Thus, it is possible to achieve greater overall processor utilization and therefore accommodate more periodic tasks with earliest-deadline scheduling.
Why use Monotonic that only goes up (schedule) to 70 % then using EDF that goes all the way.
- Less overhead
- Not good at calculating how much time we need to achieve
Mon March 25 2024
Slide 55/58
EDF vs. RM
Or why does industry prefer RM?
- 30% gain doesn’t make much a difference
- Processor speeds double
- Good designs have a safety margin anyways
- Only parts are time critical
- Use the 30% for soft real-time tasks
- RM is more predictable in overload situations
- Often you don’t have deadlines
Use RM in real life for safety reasons
Priority Inversion:
- Can occur in any priority-based preemptive scheduling scheme
- Occurs when circumstances within the system force a higher priority task to wait for a lower priority task
Priority Inheritance
- Duration of a priority inversion depends on unpredictable actions of other unrelated tasks
- Lower-priority task inherits the priority of any higher priority task pending on a resource they share
priority ceiling??
- give each resource a priority and as soon as a process locks that resource, it will automatically get that priority
Use EDF
Lecture 11 - I/O Management and Disk Scheduling
Categories of I/O Devices
- Human readable
- Used to communicate with the user
- Printers and terminals
- Machine readable
- Used to communicate with electronic equipment
- Disk drives, USB keys, Sensors, Controllers, Actuators
- Communication
- Used to communicate with remote devices
- Digital line drivers, modems
Differences in I/O Devices:
- Data rate
- May be differences of several orders of magnitude between the data transfer rates
I/O Device Data Rates:
- Application
- The use of the device affects the management software
- Example:
- Disk used to store files requires file management software
- Disk used to store virtual memory pages needs special hardware and software to support it
- Terminal used by system administrator may have a higher priority than the regular users one
- Oracle got rid of the firebase overhead for the database. (research done)
- Complexity of control
- Simple one line on/off
- Time dependent interaction: duty cycle of stepper motors
- Complex, protocol-based interaction: most communication devices
- Unit of transfer
- Data may be transferred as a stream of bytes for a terminal or in larger blocks for a disk
- Data representation
- Encoding schemes, differences in character code and parity conventions
- Error conditions
- Devices respond to errors differently
- Motor loses its torque
- CAN does simply not transmit
- Devices respond to errors differently
11.2 Organization of the I/O Function
Performing I/O
- Programmed I/O
- The processor issues an I/O command, on behalf of a process, to an I/O module;
- Process is busy-waiting for the operation to complete before proceeding
- Interrupt-drive I/O
- I/O command is issued by processor
- Processor continues executing instructions
- Direct Memory Acces (DMA)
- DMA module controls exchange of data between main memory and the I/O device
- Processor sends a request for the transfer of a block of data to the DMA module and
- Processor interrupted only after entire block has been transferred
Prof basically flew by the next couple of slides
OS Design Issues wrt. I/O
- Efficiency
- Most I/O devices are extremely slow compared to main memory
- Supper slow for I/O devices to access data in main memory
- Use of multiprogramming allows interleaving of I/O and processing
- Even in the future: I/O will not keep up with processor throughputs
- Swapping is used to bring in additional Ready processes; swapping is an I/O operation
- Most I/O devices are extremely slow compared to main memory
- Generality
- Desirable to handle all I/O devices in a uniform manner
- Hide most of the details of the device I/O in lower-level routines
The Evolution of the I/O Function
- The processor directly controls a peripheral device
- Controller or I/O module is added
- Processor used programmed I/O without interrupts
- Processor does not need to handle details of external devices

- Controller or I/O module with interrupts
- Processor does not spend time waiting for an I/O operation to be performed
- Direct Memory Access (DMA)
- Blocks of data are moved into memory without involving the processor
- Processor involved at beginning and end only
- I/O module is a separate processor
- I/O processor
- I/O module has its own local memory
- It is a computer in its own right
The CPU is relieved of I/O related tasks, improving performance!!!
Direct Memory Access (DMA)
- Processor delegates I/O operation to the DMA
- DMA module transfers data directly to or from memory
- When transfer is complete, DMA module sends an interrupt signal to the processor
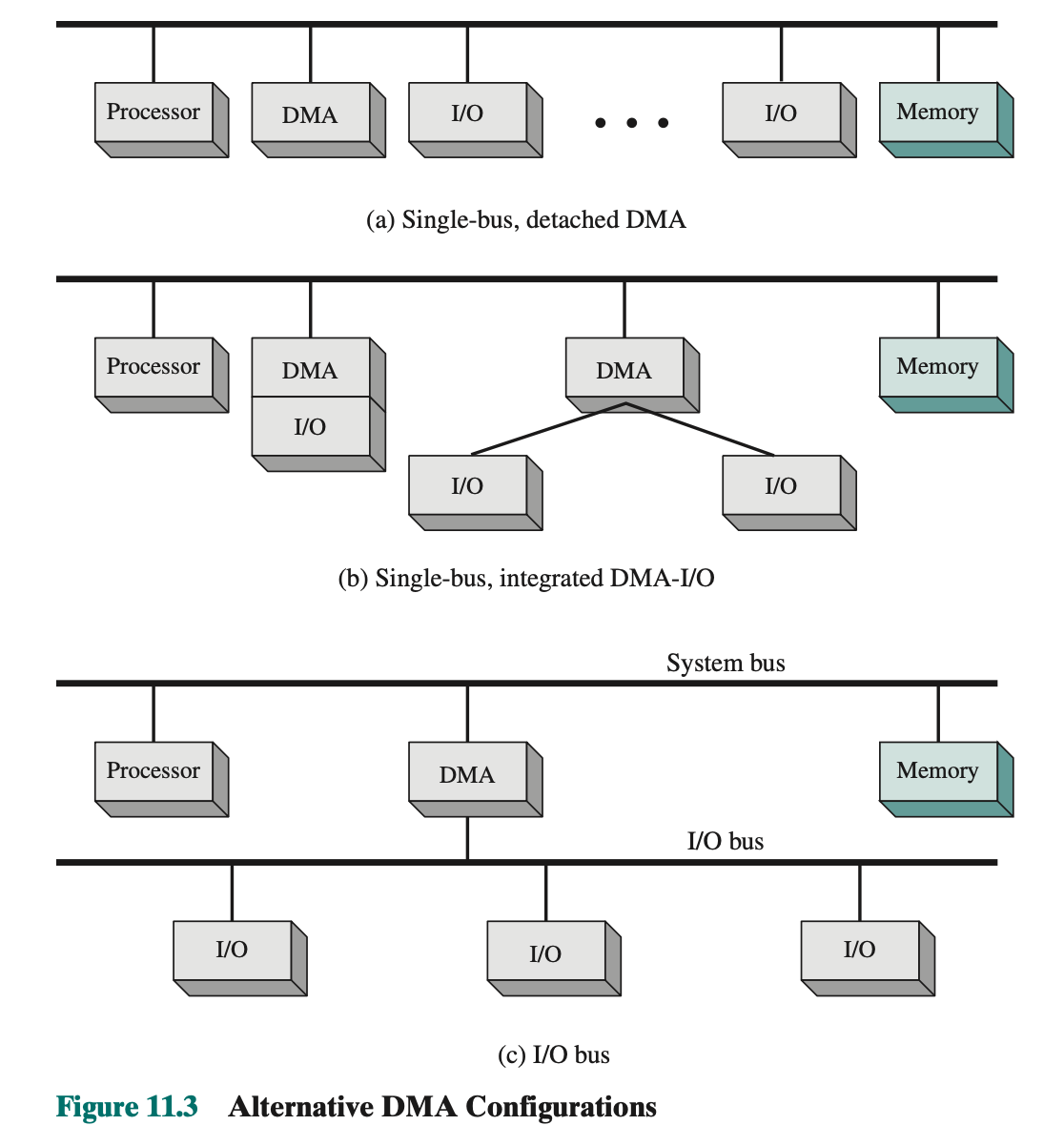
- In the first example, all modules share the same system bus.
- DMA module, acting as a surrogate processor, uses programmed I/O to exchange data between memory and an I/O module through the DMA module.
- This configuration, while it may be inexpensive, is clearly inefficient:
- Each transfer of a word consumes two bus cycles
- The DMA logic may actually be a part of an I/O module, or it may be a separate module that controls one or more I/O modules. This concept can be taken one step further by connecting I/O modules to the DMA module using an I/O bus
- Reduces the number of I/O interfaces in the DMA module to one
- Provides for an easily expandable configuration.
The exchange of data between the DMA and I/O modules takes place off the system bus.
OS Design Issues
- Efficiency
- Most I/O devices are extremely slow compared to main memory
- Use of multiprogramming allows interleaving of I/O and processing
- Even in the future: I/O will not keep up with processor throughputs
- Swapping is used to bring in additional Ready processes; swapping is an I/O operation
- Generality
- Desirable to handle all I/O devices in a uniform manner
- Applies to the way in which processes view I/O devices and the way OS manages I/O devices and operations.
- Hide most of the details of device I/O in lower-level routines,
- so upper levels of OS and processes see devices in terms of general functions!!!
- Desirable to handle all I/O devices in a uniform manner
Model of I/O Operation and Logical Structure of I/O Function
- Logical I/O: provides open, close, read, write
- Device I/O: converts operations & data into I/O instructions
- Scheduling and control: queuing and scheduling of operations
- Directory management: organizes files, symbolic file names are converted
- File system: open, close, read, write
- Physical organization: convert file addresses into locations in the disc
Hierarchical philosophy on I/O:
-
Lower part is always the same (I/O abstraction, scheduling and control of the hardware)
-
The bottom two are very specific to the hardware
-
Read, write, open and close
-
Logical I/O
- treats device as logical resource with no concerns of details of control
- manages I/O functions on behalf of user process
-
Device I/O
- convert requested operations into sequences of I/O instructions, channel commands, and controller orders
-
Scheduling and Control
- queueing and scheduling of I/O operations
- handle interrupts, check I/O status, …
- Layer of software that interacts with I/O module, hence device hardware
For secondary storage devices with a file system:
- Directory Management
- convert symbolic file names to identifiers that reference directly / indirectly the file
- manage user add, delete, reorganize operations
- File System
- logical structure of files and operations that can be specified by user
- Physical Organization
- convert logical references to files/records to physical storage addresses
I/O Buffering
To speed it up. To avoid overheads and inefficiencies, convenient to perform input transfers in advance of requests being made and to perform output transfers some time after the request is made.
-
Reasons for buffering
- Processes must wait for I/O to complete before proceeding
- Certain pages must remain in main memory during I/O
-
Risk of deadlock:
- Process calls an I/O routine and blocks
- Process is swapped out
- Process waits for I/O completion, but I/O waits for the process to be swapped in to access the memory
- Why putting the I/O buffer into the user process??
- Might swap the process into virtual memory. The swap drive as well as the i/o buffer. So the I/O devices won’t be able to write it, because the memory is on the swap drive. OS can’t resume that process, because the process is blocked although everyone could be making process.
- We don’t want the OS to swap that buffer out basically.
- Don’t program buffer in the user to be swappable.
-
Block oriented
- Information is stored in fixed sized blocks
- Transfers are made a block at a time
- Used for a disks and USB keys
-
Stream-oriented
- Transfer information as a stream of bytes
- Used for terminals, printers, communication ports, mouse and other pointing devices, and most other devices that are not secondary storage
-
The kernel (I/O routines) handle buffering
What can you do in a a block oriented buffering but not in a stream oriented?
You can’t perform seek() in stream-oriented for example in the future 5 seconds. Block-oriented devices allows you to do that.
Main difference: no
fseek()for streams, no going backwards!
Single Buffer
- Operating system assigns a buffer in a main memory for an I/O request
- Block oriented
- Input transfers made to system buffer
- When transfer is complete, process moves the block into user space and immediately requests another block.
- Block moved to user space when needed
- Another block is moved into the buffer
- Read ahead
- User process can process one block of data while next block is read in
- Swapping can occur since input is taking place in system memory, not user memory
- Operating system keeps track of assignment of system buffers to user processes
- Input transfers made to system buffer
- Stream-oriented
- Use a line at a time
- User input from a terminal is one line at a time with carriage return signalling the end of the line
- Output to the terminal is one line at a time
Flush()call in C
Double Buffer
In a double buffering you can always read in more data in OS, while the user processes is moving buffer data into the user process.
- Use two system buffers instead of one
- A process can transfer data to or from one buffer while the operating system empties or fills the other buffer
-
Ensures that the process will not have to wait on I/O
-
But increased complexity
-
stream-oriented input
- again are faced with the two alternative modes of operation
- For line-at-a-time I/O,
- the user process need not be suspended for input or output, unless the process runs ahead of the double buffers.
- For byte-at-a- time operation,
- the double buffer offers no particular advantage over a single buffer of twice the length.
- In both cases, the producer/consumer model is followed.
Double buffering fails when process performs rapid bursts of I/O!
Circular Buffer
- More than two buffers are used
- Each individual buffer is one unit in a circular buffer
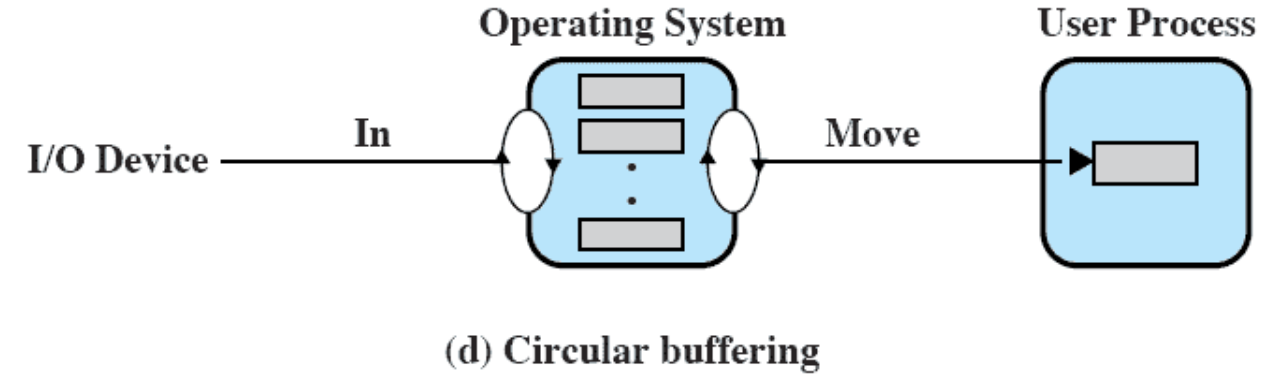
- Good for bursty I/O
- Producer and consumer (think of)
Why is two buffers not enough?
Double buffer will be inadequate for bursty I/O. When process performs rapid bursts of I/O!
Disk Scheduling
Disk Performance Parameters
- To read or write, the disk head, must be positioned at the desired track and at the beginning of the desired sector
- Seek time
- Time it takes to position the head at the desired track
- Rotational delay or rotational latency
- Time its takes for the beginning of the sector to reach the head
General timing diagram of disk I/O transfer:
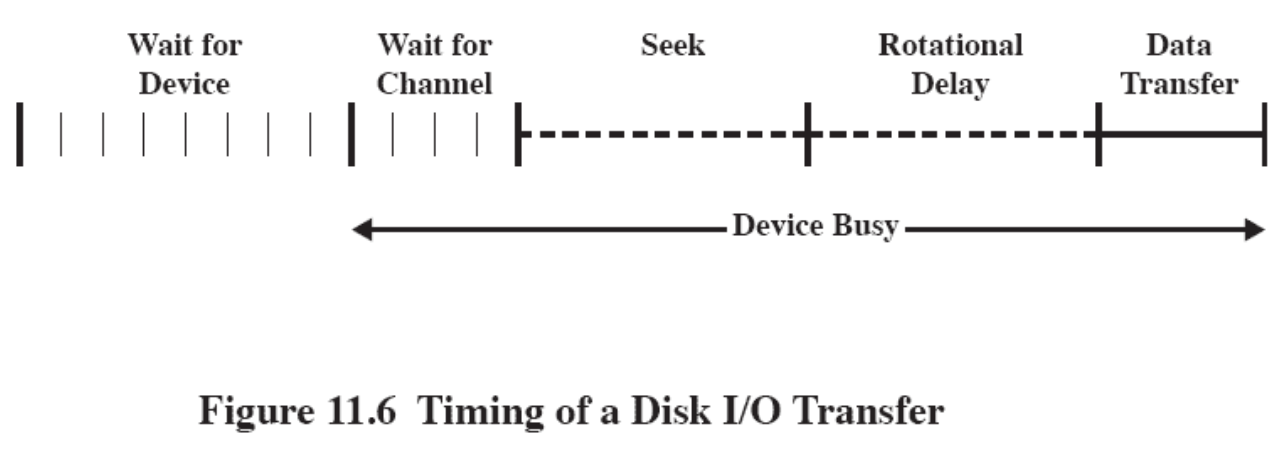
- Access time
- Sum of seek time and rotational delay
- The time it takes to get in position to read or write
- There can be a huge difference sequential read access and random read access.
Disk Scheduling Policies
- Seek times is the reason for difference in performance
- For a single disk there will be a number of I/O requests
- If requests are selected randomly, will get poor performance
Compares the performance of various scheduling algorithms for an example sequence of I/O requests. The vertical axis corresponds to the tracks on the disk. The horizontal axis corresponds to time or, equivalently, the number of tracks traversed.
The requested tracks, in the order received by the disk scheduler, are 55, 58, 39, 18, 90, 160, 150, 38, 184.
First In First Out (FIFO)
- Process requests sequentially
- Advantages:
- Fair to all processes
- Disadvantage:
- Approaches random scheduling in performance if there are many processes
Requests 55, 58, 39, 18, 90, 160, 150, 38, 184
Disk arm movement with FIFO:
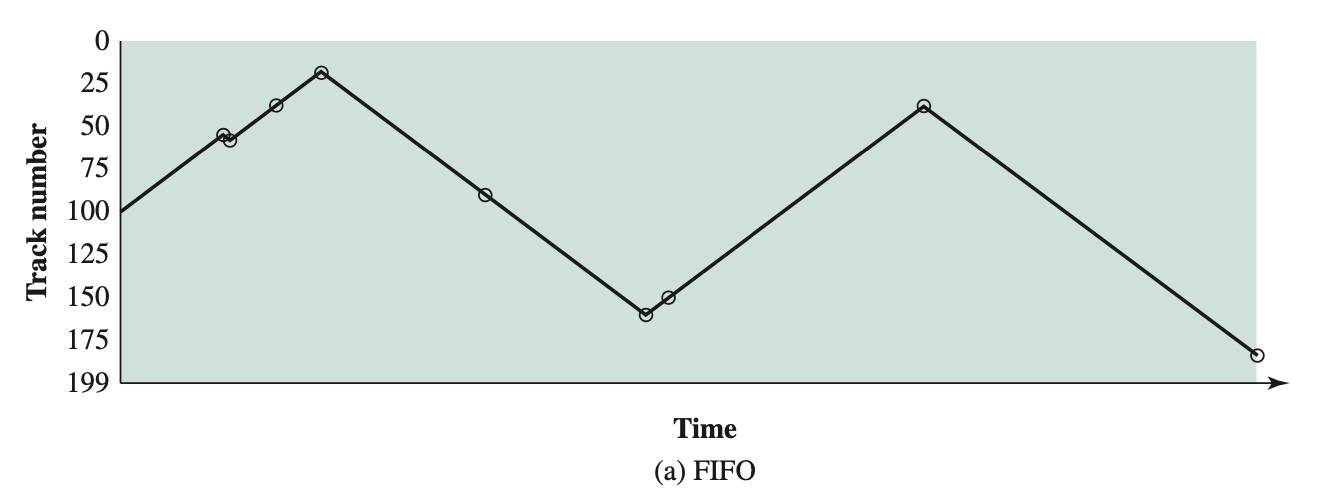
This is going to be on the exam!!
Priority-based scheduling
- Goal is not to optimize disk use but to meet other objectives
- Example 1:
- Short batch jobs may have higher priority
- Provide good interactive response time, since a lot of short jobs are flushed through the system quickly
- Example 2:
- Earlier deadlines have higher priority
- Can lead to counter measures by users: split their jobs into smaller pieces to beat the system!
- Can lead to starvation (principle of locality)
Last In, First Out
- Good for transaction processing systems
- The device is given to the most recent user, so there should be little arm movement
- Advantages:
- Taking advantage of locality improves throughout and reduce queue lengths
- Possibility of starvation since a job may never regain the head of the line
Shortest Seek Time First
-
Select the disk I/O request that requires the least movement of the disk arm from its current position
-
Always choose the minimum seek time
-
Requires knowledge of track position
-
Starvation still possible
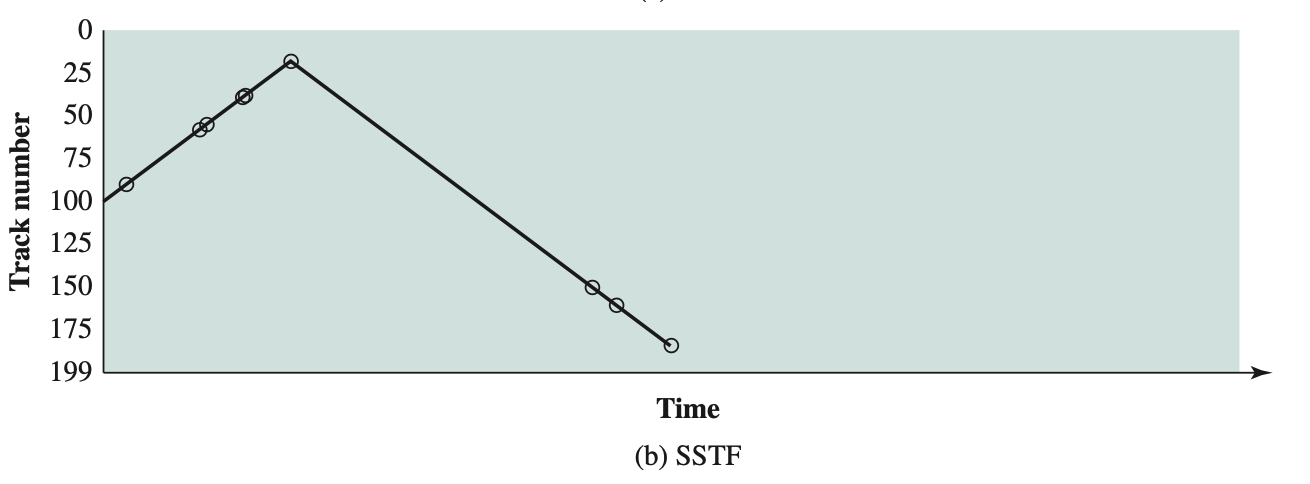
-
Better than FIFO, because arm can move in two directions.
-
The first track accessed is 90, because this is the closest requested track to the starting position. The next track accessed is 58 because this is the closest of the remaining requested tracks to the current position of 90. Subsequent tracks are selected accordingly.
SCAN
- Arm moves in one direction only (increasing or decreasing track
#), satisfying all outstanding requests until it reaches the last track in that direction, reverse the direction - Similar performance as SSTF
- Biased against area most recently traversed
- Deterministic
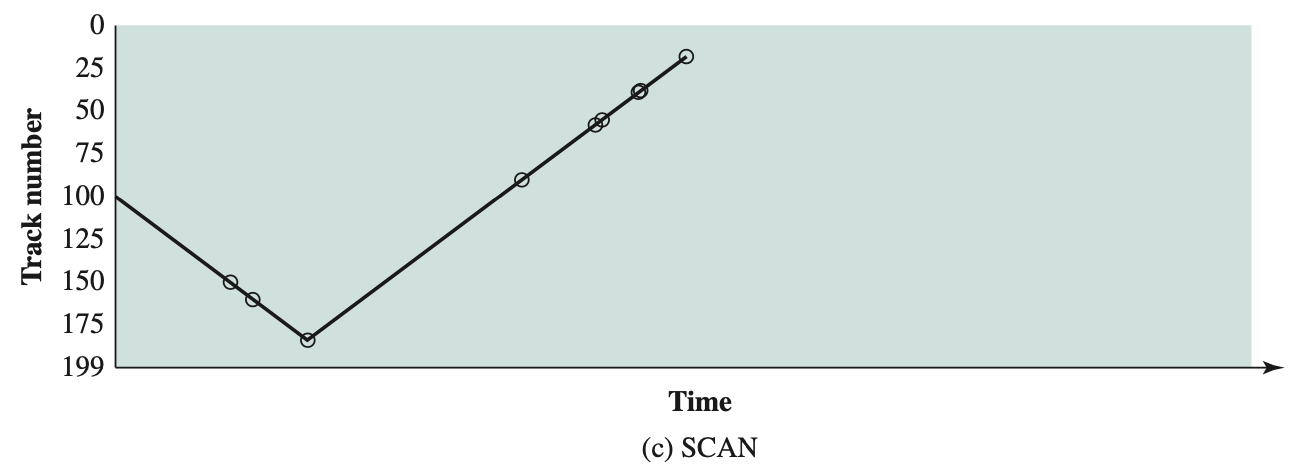
- the arm is required to move in one direction only, satisfying all outstanding requests en route, until it reaches the last track in that direction or until there are no more requests in that direction.
- This latter refinement is sometimes referred to as the LOOK policy.
- Figure 11.7c and Table 11.2c illustrate the SCAN policy. Assuming that the initial direction is of increasing track number, then the first track selected is 150, since this is the closest track to the starting track of 100 in the increasing direction.
As can be seen, the SCAN policy behaves almost identically with the SSTF policy.
- Disadvantage:
- Note that the SCAN policy is biased against the area most recently traversed. Thus it does not exploit locality as well as SSTF.
- SCAN policy favours jobs whose requests are for tracks nearest to both innermost and outermost tracks and favours the latest-arriving jobs.
C-SCAN
- Restricts scanning to one direction only
- When the last track has been visited in one direction, the arm is returned to the opposite end of the disk and the scan begins again.
- Deterministic, reduces delay for new requests
- This reduces the maximum delay experienced by new requests
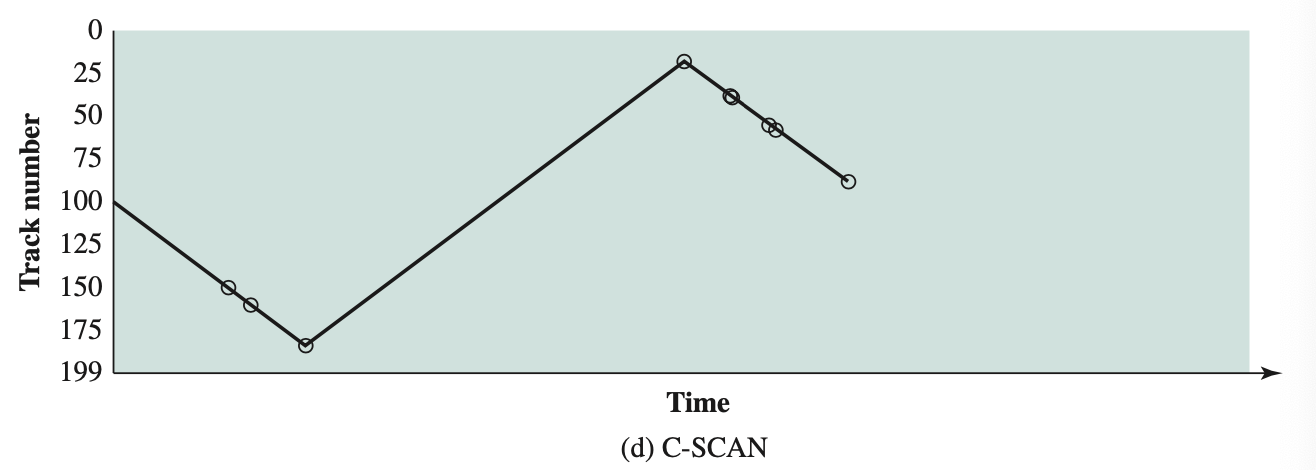
N-step-SCAN
- Segments the disk request queue into subqueues of length N
- Subqueues are processed one at a time, using SCAN
- New requests added to some other queue when queue is processed
Comparison of all theses
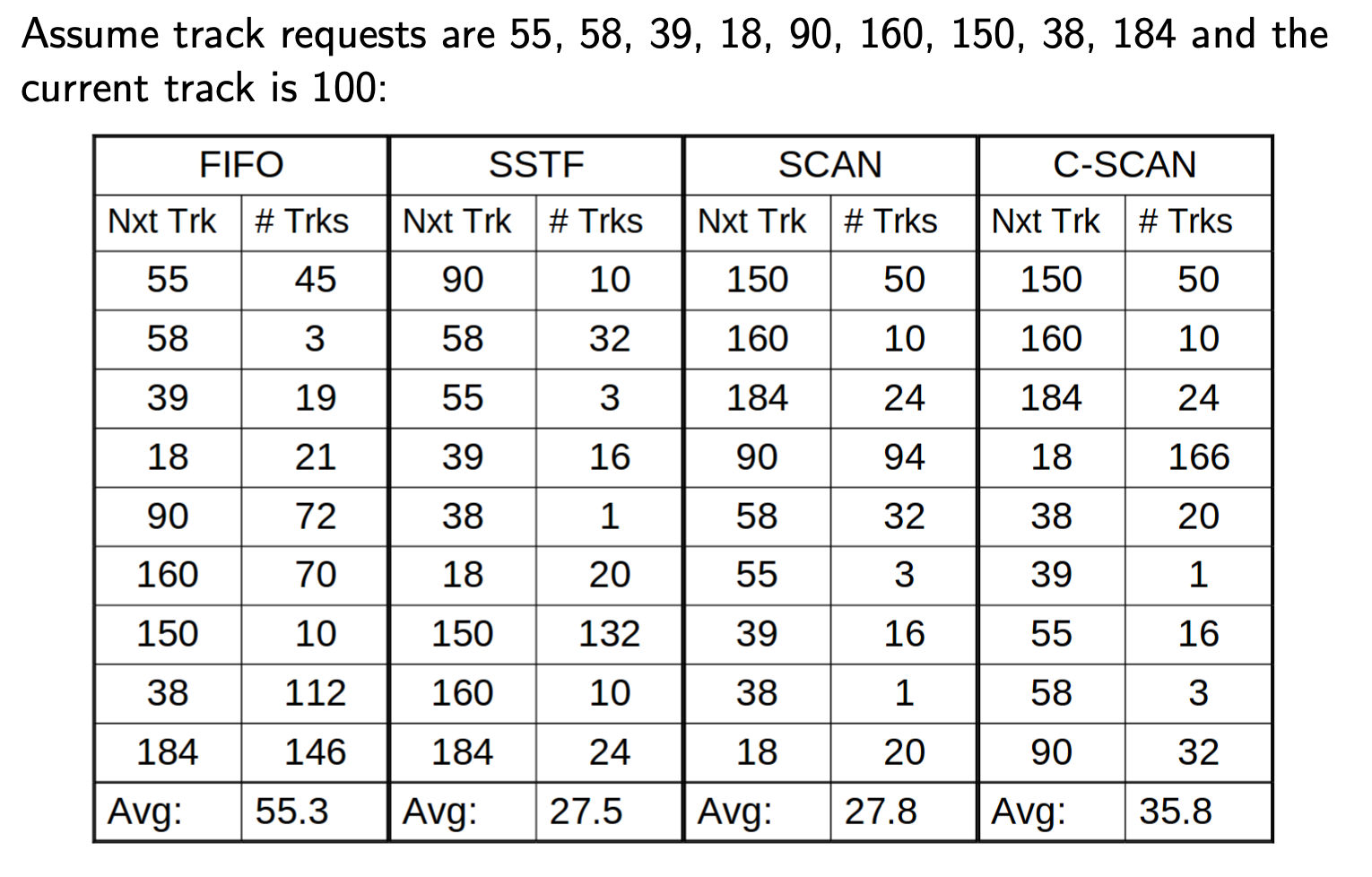
RAID (not on final)
Layer of indirection is the solution to all problems except performance
RAID 0
- Why is strip 0 and strip 1 on different physical hardrive?
- Principle of locality, you have a higher chance of reading strip 1 if you are reading strip 0.
- This way, you get to access both of them at the same time
- High data transfer capacity
- Lower reliability (Mean time to failure decrease due to several drives)
- Not true RAID
RAID 1 (mirrored)
- redundancy achieved by simple duplication of all data
- advantages:
- read requests can be serviced by either disk
- write requires both stripes be updated but it can be done in parallel
- recovery from single
- Downside:
RAID 2 (redundancy through Hamming code)
- Hamming distance? what is that. error correcting bits. to fix 2 transmission of datas????????????
RAID 3
RAID 4
RAID 5
- Is gonna distribute it, making the last one no longer a bottleneck.
RAID 6
- Support two hard-drive failures. We have 2 blocks to correct hard-drive failures.
Wed March 27
Disk Cache??? 11.7
Lecture 12 - Filesystems
File System
- Reasons to have a file system:
- Long-term storage
- Files are stored on disk or other secondary storage
- Sharable data between processes
- Files have names and can have associated access permissions
- Structured
- hierarchic relationships among files
- Long-term storage
Typical File Operations
- Create
- Delete
- Open
- Close
- Read
- Write
- (Seek) is the find??
File Terminology / Structure
4 terms use when discussing files:
- Field
- Basic element of data
- Contains a single value (student name)
- Characterized by its length and data type
- Record
- Collection of related fields
- Treated as a unit
- File
- Collection of similar records
- Treated as a single entity
- Have file names
- May restrict access
- Database
- Collection of related data
- Relationships exist among elements
Typical Record Operations
- Retrieve_All
- Retrieve_one
- Retrieve_Next
- Retrieve_Previous
- Insert_One
- Delete_One
- Update_One
- Retrieve_Few
File Management Systems
File Management Systems (FMS)
A set of system software that provides services to users & applications in the use files.
- Sole interface for the user & applications
- Management provided by the OS:
- Programmer does not need to develop file management software
Objective for a FMS
- Meet the data management needs and requirements of the user
- Guarantee that the data in the file are valid
- Reliability is a key thing!
- Optimize performance (user&system side)
- Provide I/O support for a variety of storage device types
- Minimize or eliminate the potential for lost or destroyed data
- Provide a standardized set of I/O interface routines
- Provide I/O support for multiple users
sticky bit you can set, with a shell. if you copy a shell like bas, and set a sticky bit. you can somehow access?? gain access
Minimal Set of Requirements
- Authorized users can create, delete, read, write and modify files
- Authorized users have controlled access to other users files
- Authorized users can control access permissions for own files
- Authorized users can restructure their files
- Authorized users can move data between files
- Authorized users can back up and recover their files in case of damage
- Authorized users can access their files by using symbolic names
Files System Software Architecture:
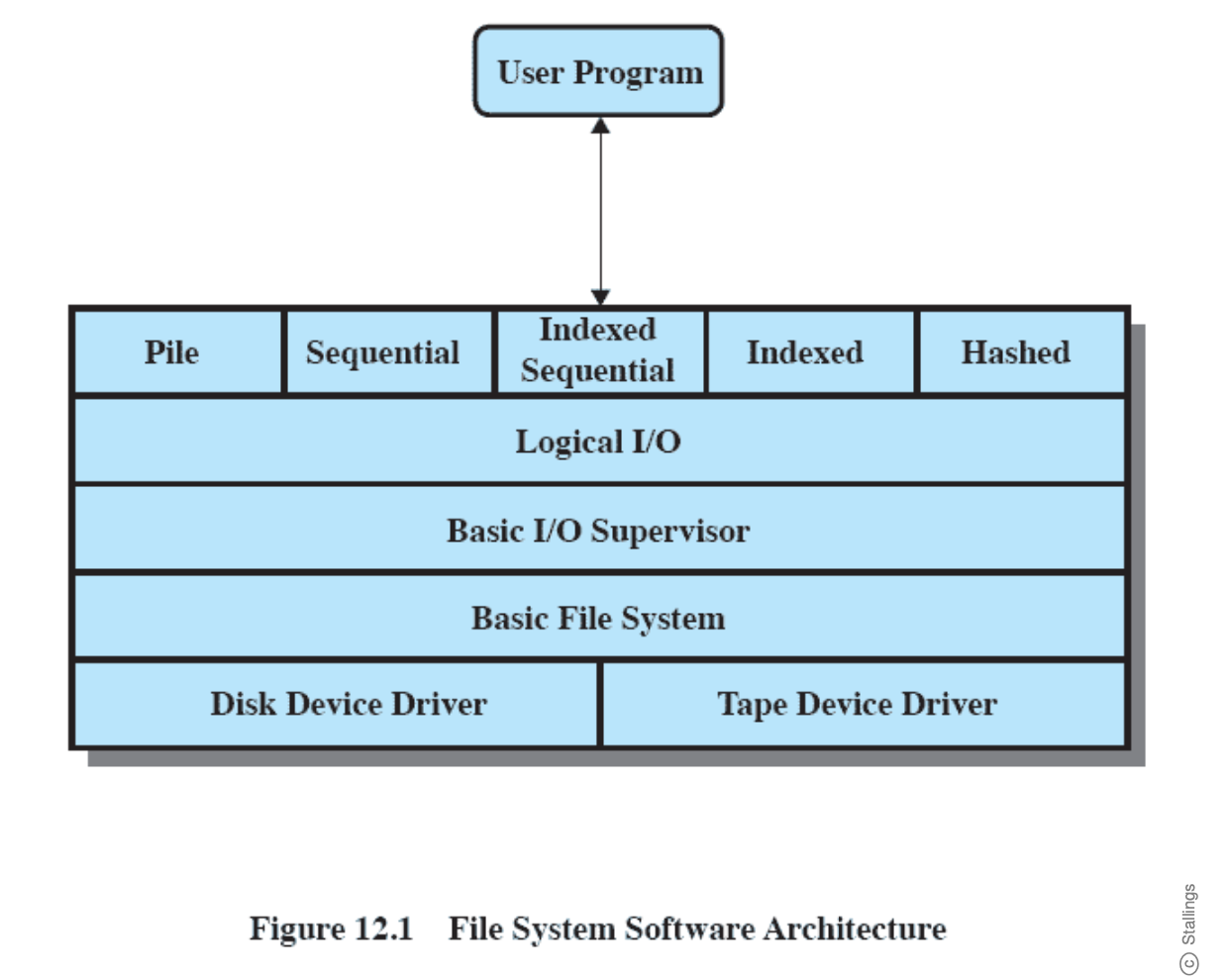
- We can see at lowest level, device drivers
Device Drivers
- Lowest level
- Communicates directly with peripheral devices
- Responsible for starting I/O operations on a device
- Processes the completion of an I/O request
- Considered to be part of the OS
Not going to go over how it is stored on various devices.
Prof just skips over all the slides until page 18...
Is it important????
Basic File System
- Also called ‘Physical I/O’
- Does not understand data, only handles it
- Deals with exchanging block of data
- Concerned with the placement of blocks
- Concerned with buffering blocks in main memory
- Considered to be part of the OS
Basic I/O Supervisor
- Maintains control structure for device I/O, scheduling, and file status
- Optimizes access to device I/O
- Manages I/O buffers
Logical I/O
- Enables users and applications to access records
- Provides general-purpose record I/O capability
- Maintains basic data about file
Access Method
- Level of file system closes to the user
- Provides interface between applications and the file systems and devices that hold the data
- Reflect different file structures
- Different ways to access and process data
- Can optimize access depending on the application needs:
- Sequential access (one after the other)
- Direct access (direct address)
- Indexed access (use an identifier)
Elements of File Management: (different way of viewing the functions of a file system)
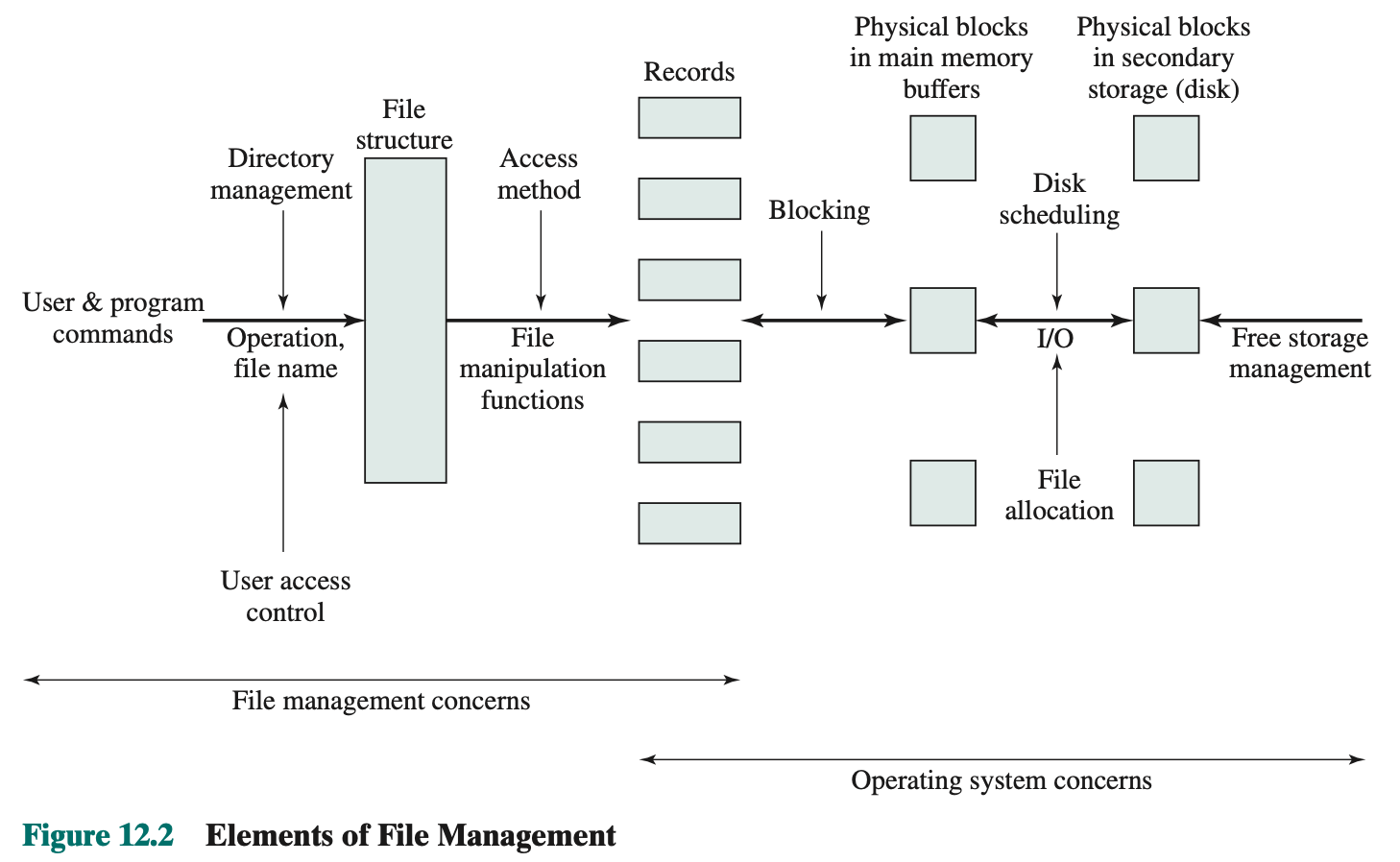
File Management Functions:
- Identify and locate a selected file
- Use a directory to describe the location of all files plus their attributes
- On a shared system, describe user access control
File Organization and Access
How to manage your files? File Organization
… logical structuring of records
- Criteria:
- Short access time
- Needed when accessing a single record
- Ease of update
- File on CD-ROM will not be updated, so this is not a concern. (sequential read access)
- Economy of storage
- Should be minimum redundancy in the data
- Redundancy can be used to speed access such as an index
- Simple maintenance
- fragmentation might occur
- Reliability
- file system that survives power outage
5 organizations:
- The pile
- The sequential file
- The indexed sequential file
- The indexed file
- The direct, or hashed, file
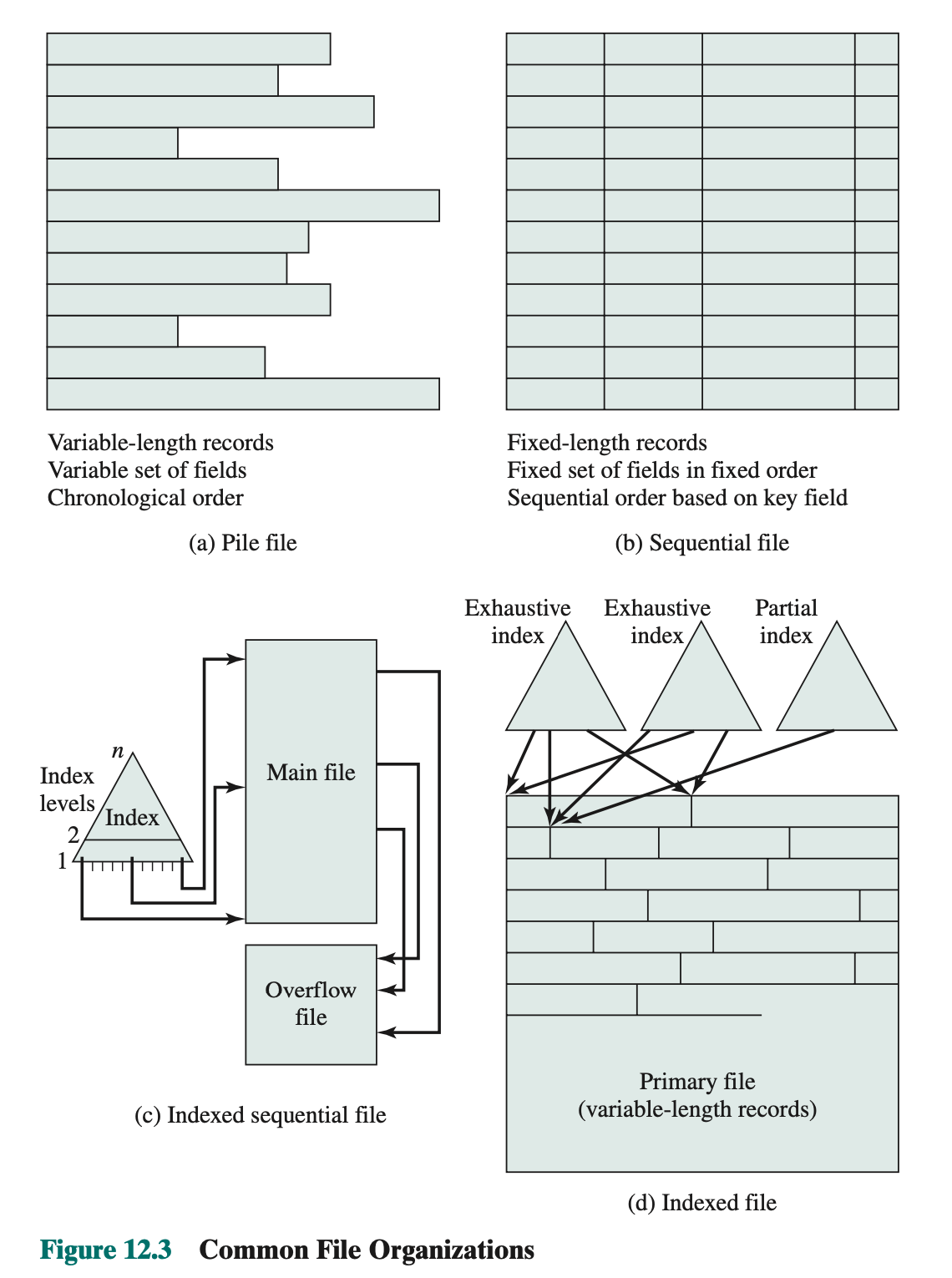
The Pile
- The pile
- Data is collected in the order they arrive
- Purpose is to accumulate a mass of data and save it
- Records may have different fields
- No structure
- Record access is exhaustive search
- Useful when data is only collected and stored prior to processing
- Advantages:
- Least complicated form of file organization
- Disadvantage:
- search, you need to search all of them
- if you delete, you’ll have a hole
The Sequential File

- The Sequential File
- Fixed format used for records
- Records are the same length
- All fields the same (order and length)
- Fields names and lengths are attributes of the file
- Records are stored in key sequence
- One field is the key file
- Uniquely identifies the record
- Records are stored in key sequence
- Search is inefficient (look through the whole file)
- Updates are a pain, because physical organization matches the logical organization
- Overflow pile, transaction log & periodic batch updates to the file that rearranges the file
- Or: different physical layout from logical layout
- Advantages:
- most common form of file structure
- fix format, easy to repair than the previous, easier to jump to one, for example jump 5 ahead because they all have the same size
- optimum for batch applications if they involve the processing of all the records
- Only one that is easily stored on tape or disk
- Disadvantages
- For interactive applications that involve queries and/or updates of individual records, it provides poor performance.
- Considerable processing and delay are encountered to access a record in a large sequential file.
- Additions to files ar ea problem
Indexed Sequential File
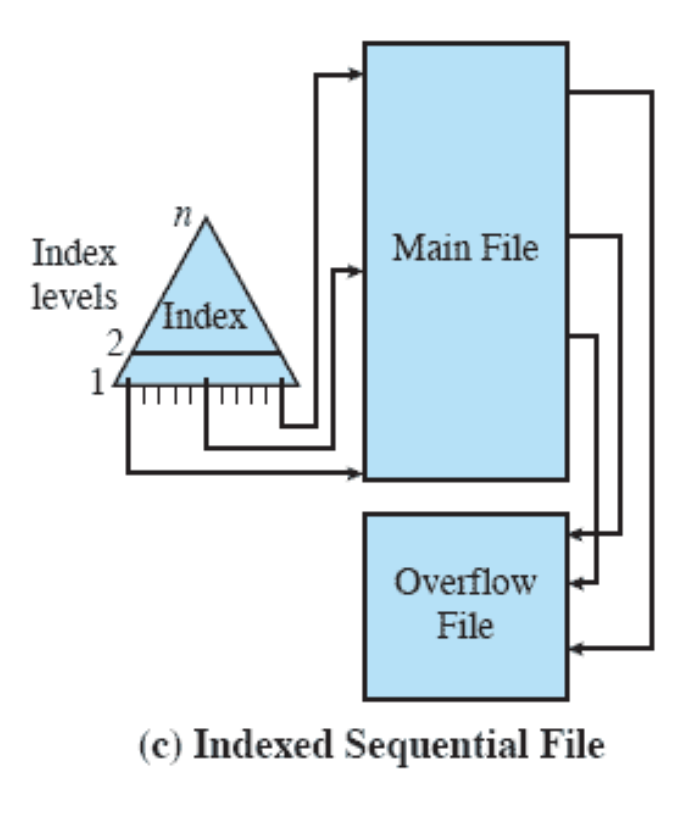
- Indexed Sequential File
- Index provides a lookup capability to quickly reach the vicinity of the desired record
- Contains a key field and a pointer to the main file
- Indexed is searched to find highest key value that is equal to or precedes the desired key value
- Search continues in the main file at the location indicated by the pointer
- Comparison of sequential and indexed sequential
- Example: a file contains 1 million records
- On average 500,000 accesses are required to find a record in a sequential file
- If an index contains 1000 entries, it will take on average 500 accesses to find the key, followed by 500 accesses in the main file. Now on average it is 1000 accesses
- New records are added to an overflow file
- Record in main file that precedes it is updated to contain a pointer to the new record
- Upon NULL pointer, continue in the main file
- The overflow is merged with the main file during a batch update
- Multiple levels of indexes for the same key field can be set up to increase efficiency
- Index provides a lookup capability to quickly reach the vicinity of the desired record
Main difference to indexed file: idea of a overflow. better to have index, and search through index, still have them in order. every single write operations will cause a reordering of all of them. At some point, the OS will merge everything written that overflowed into the overflow file, and merge it into the main file.
You can always rebuild the index for a particular file. You don’t want to keep the overflow file in the memory, if power goes out, you will loose all the transactions
If you don’t find it in the main fi.e, it will go search it in the overflow file.
Indexed File
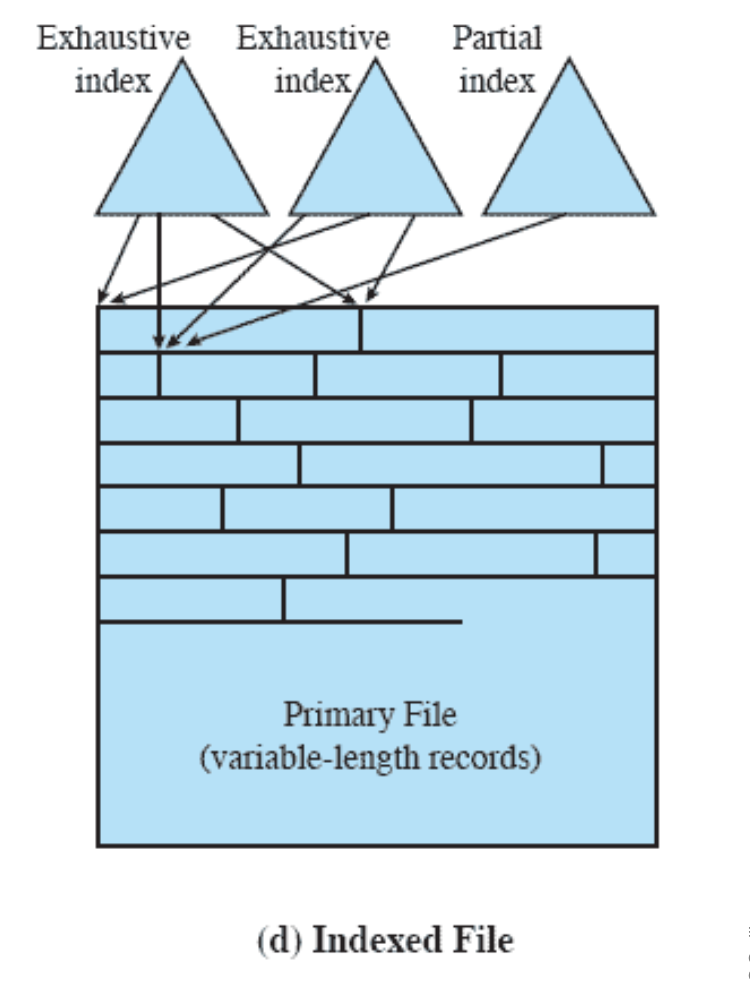
- Indexed File
- Uses multiple indexes for different key files
- May contain an exhaustive index that contains one entry for every record in the main file
- May contain a partial index
The Direct or Hashed File
- The Direct or Hashed File
- Directly access a block at known address
- Key field required for each record
[! Warning] Big-Oh won’t be asked on the exam. He will not ask question on b-trees and datastructures.
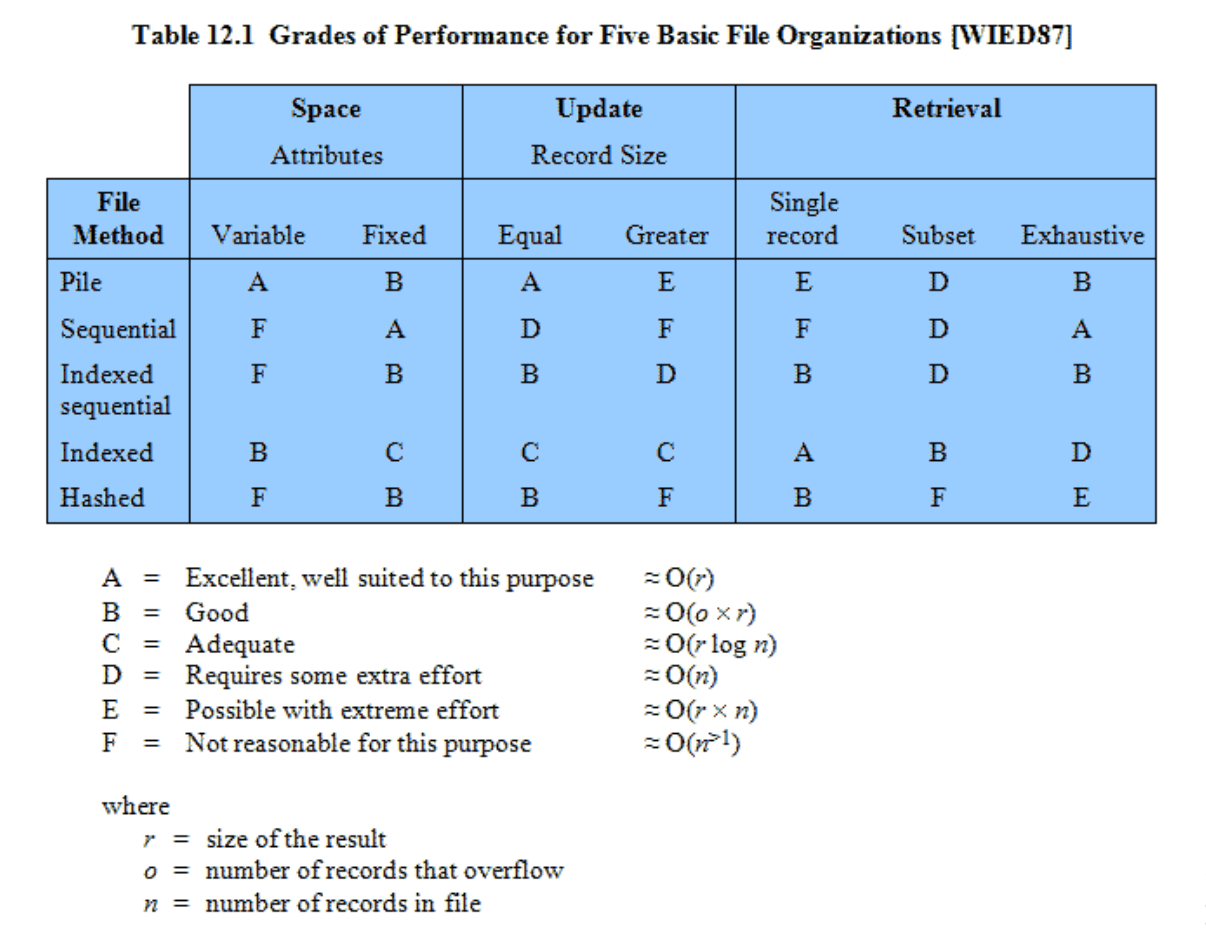
File Directories
File Directories
- Contains information about files
- Attributes
- Location
- Ownership
- Directory itself is a file usually accessed indirectly by the user
- Directories are by themselves files.
- Provides mapping between file names and the files themselves

Access Information is important. You can figure out if someone accessed your directories or files by looking up the access times or modified times.
ls -lu fooafter touching
Single List Directory
- Approach 1: single list
- List of entries, one for each file
- Sequential file with the name of the files serving as the key
- Provides no help in organizing the files
- Forces user to be careful not to use the same name for two different files
- Approach 2: one list per user
- One directory for each user and a master directory
- Master directory contains entry for each user
- Provides address and access control information
- Each user directory is a simple list of files for that user
- Still provides no help in structuring collections of files (unique naming, no group organization (project files, …))
- Approach 3: tree structure
- Master directory with user directories underneath it
- Each user directory may have subdirectories and files as entries
You can have complex trees, but it just comes down to hierarchical tree structures.
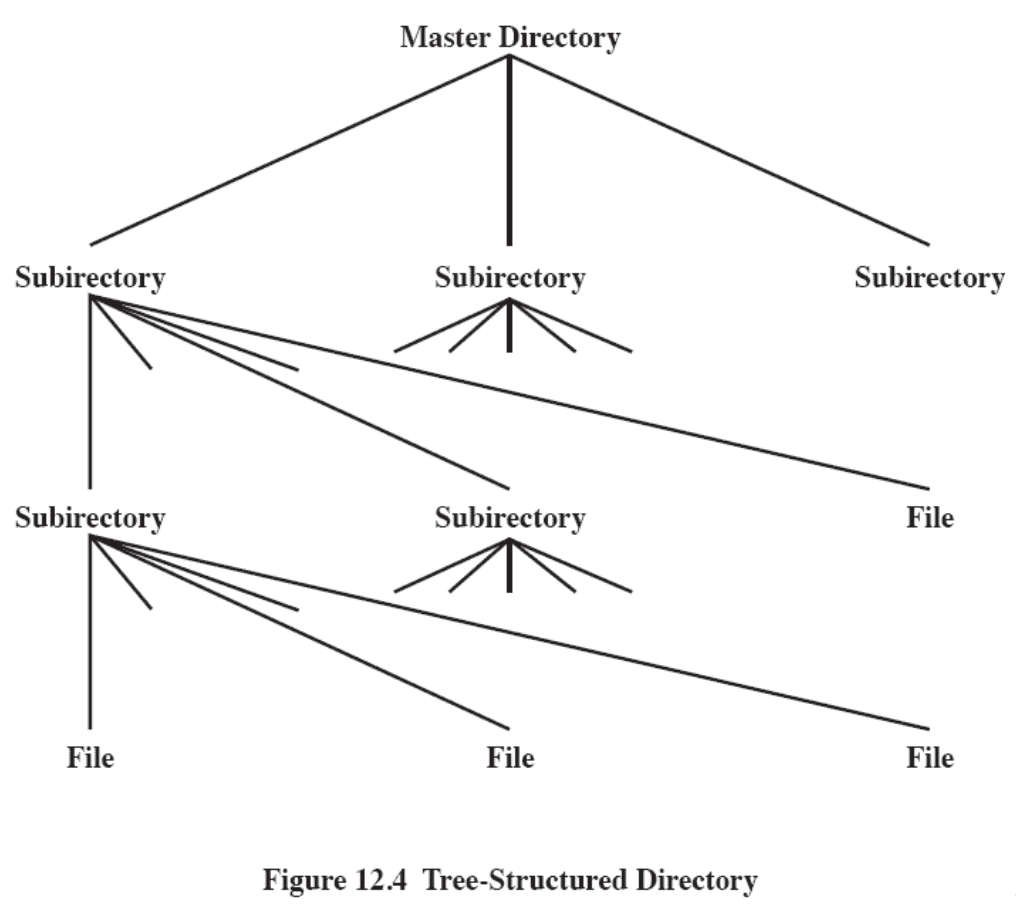
Example of Tree-Structured Directory:
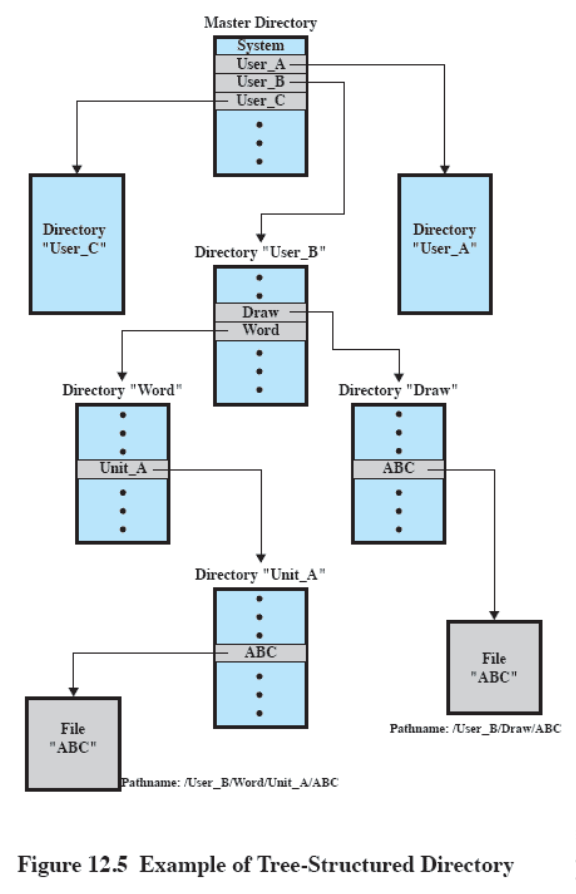
Hierarchical, or Tree-Structured Directory
- Files can be located by following a path from the root, or master directory down various branches
- This is the pathname for the file
- Can have several files with the same file name as long as they have unique path names
- Current directory is the working directory
- Files are referenced relative to the working directory
You can just mount files, sshfs. advantages of unified tree. you can just mount it. the processes don’t understand the differences.
File Sharing
File Sharing
- In multiuser system, allow files to be shared among users
- Two issues
- Access rights
- Management of simultaneous access
Access Rights
- None
- If you don’t have knowledge, doesn’t mean you don’t have execution permissions. You might just not have read access of the directory
- User may not know of the existence of the file
- User is not allowed to read the user directory that includes the file
- Knowledge
- User can only determine that the file exists and who its owner is
- Execution
- The user can load and execute a program but cannot copy it
- Reading
- The user can read the file for any purpose, including copying and execution
- Appending
- The user can add data to the file but cannot modify or delete any of the files’s contents
- Updating
- The user can modify, deleted, and add to the file’s data. This includes creating the file, rewriting it, and removing all or part of the data
- Changing protection
- User can change access rights granted to other users
- Deletion
- User can delete the file
- Owners
- Has all rights previously listed
- May grant rights to others using the following classes of users
- Specific user
- User groups
- All for public files
Simultaneous Access
- User may lock entire file when it is to be updated
- User may lock the individual records during the update
- Mutual exclusion and deadlock are issues for shared access
proc/lock lets you see which files are locked that you cannot see in your system
How to store data on I/O device?
Record Blocking
Record Blocking
- Organize records in blocks on the I/O device
- Design questions
- Variable or fixed block size”
- Fixed-length records, storing integral number in a block
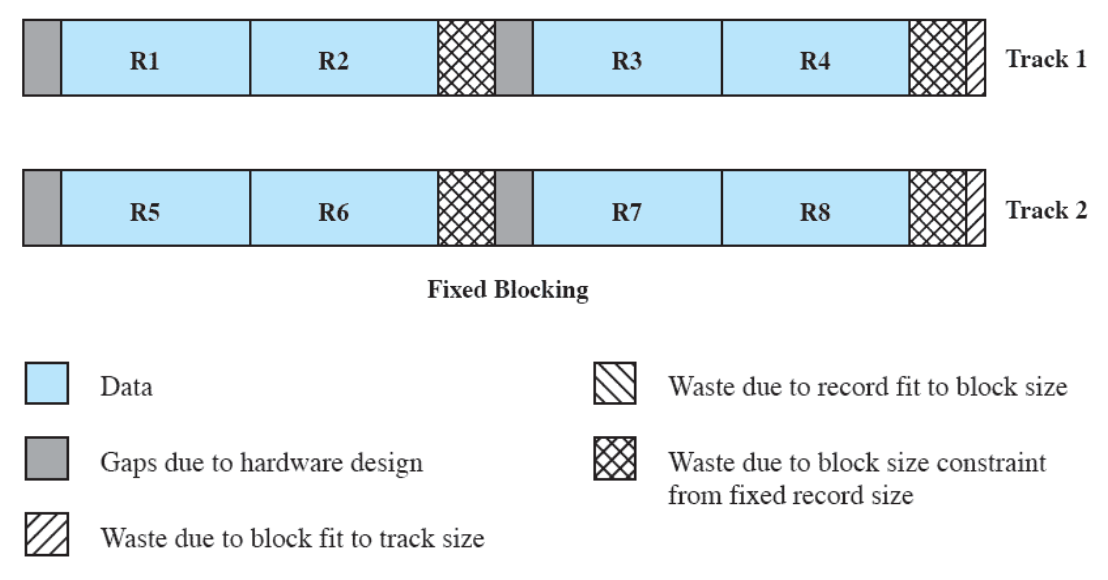
- Variable-length records, some records span two blocks with a continuation pointer
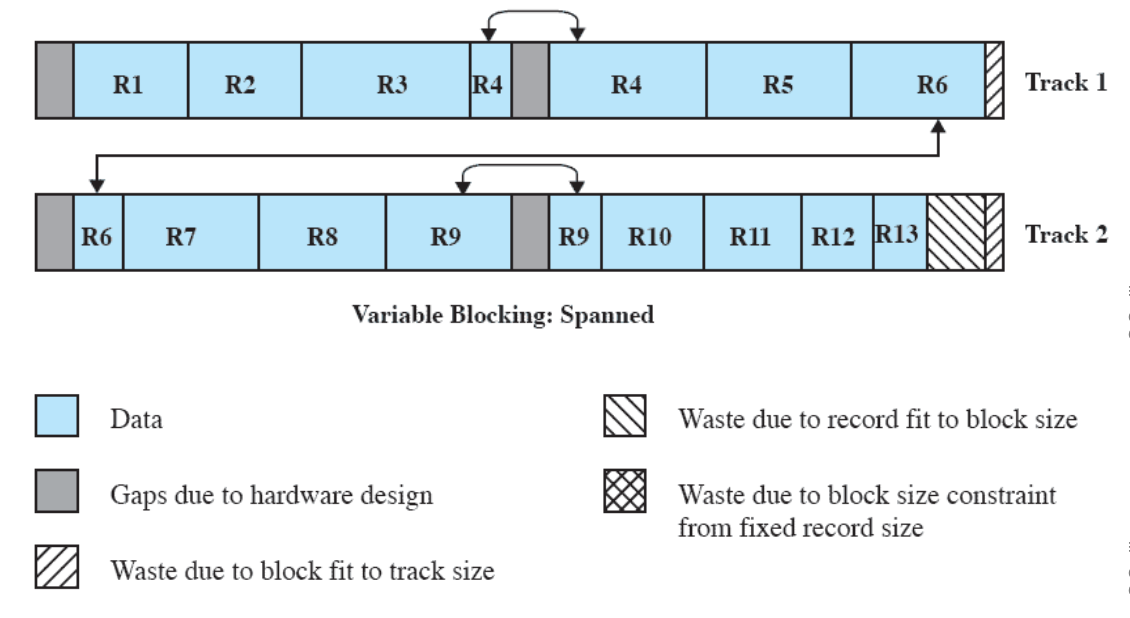
- Variable-length records, no spanning
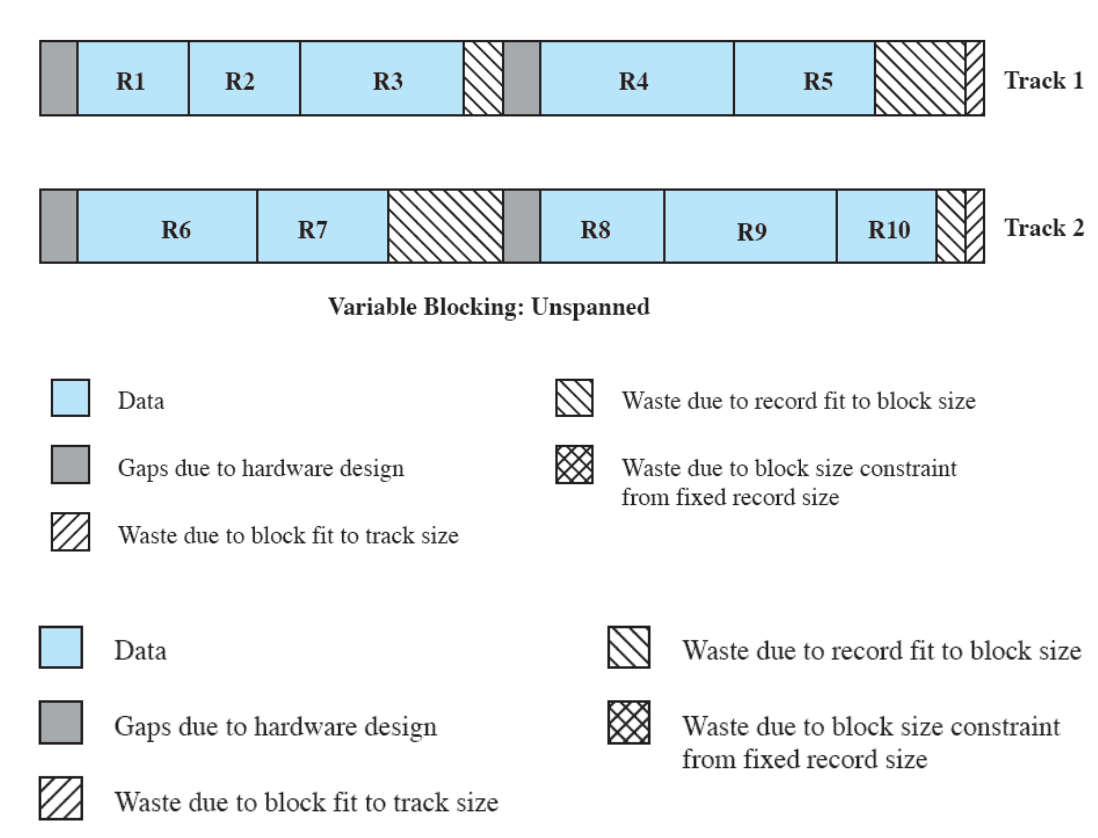
- Variable-length records, no spanning
With spanning, you’ll have two read and writes for the record
Monday April 1
Secondary Storage Management
- Space must be allocated to files
- Must keep track of the space available for allocation
Preallocation
- Need the maximum size for the file at the time of creation
- Difficult to reliably estimate the maximum potential size of the file
- Tend to overestimate file size as not to run out of space
Contiguous Allocation
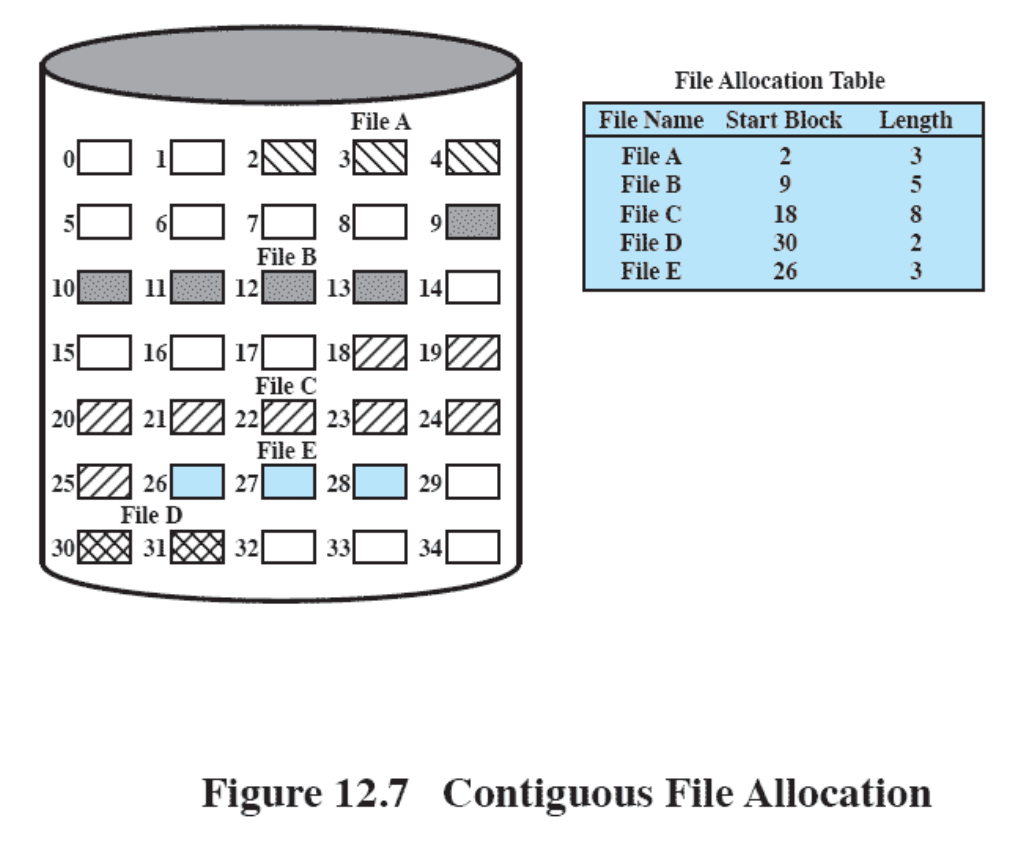
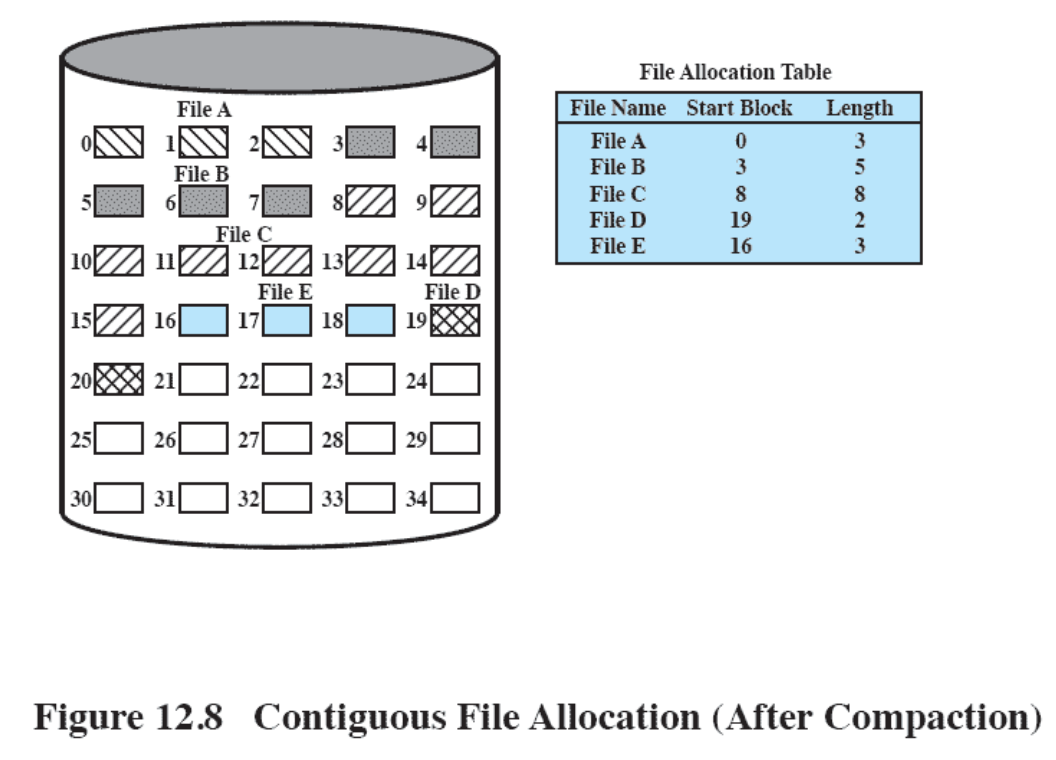
Chained Allocation
- Allocation on basis of individual block
- Each block contains a pointer to the next block in the chain
- Only single entry in the file allocation table
- Starting block and length of file
- Uses doubly linked list to implement it
- No external fragmentation
- Best for sequential files
- No accommodation of the principle of locality
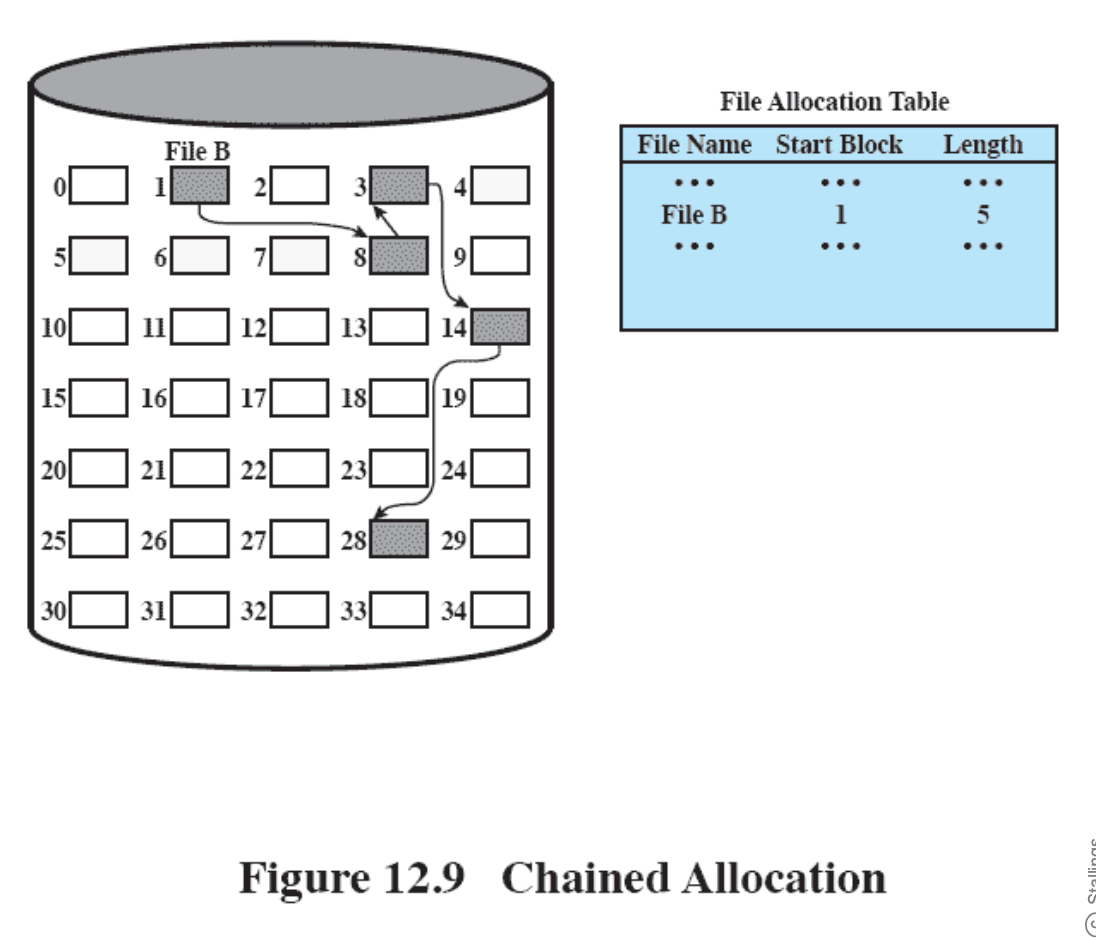
- Disadvantages:
- If one block breaks, there is no way to recover the whole file. We don’t know where the pointers points to anymore.
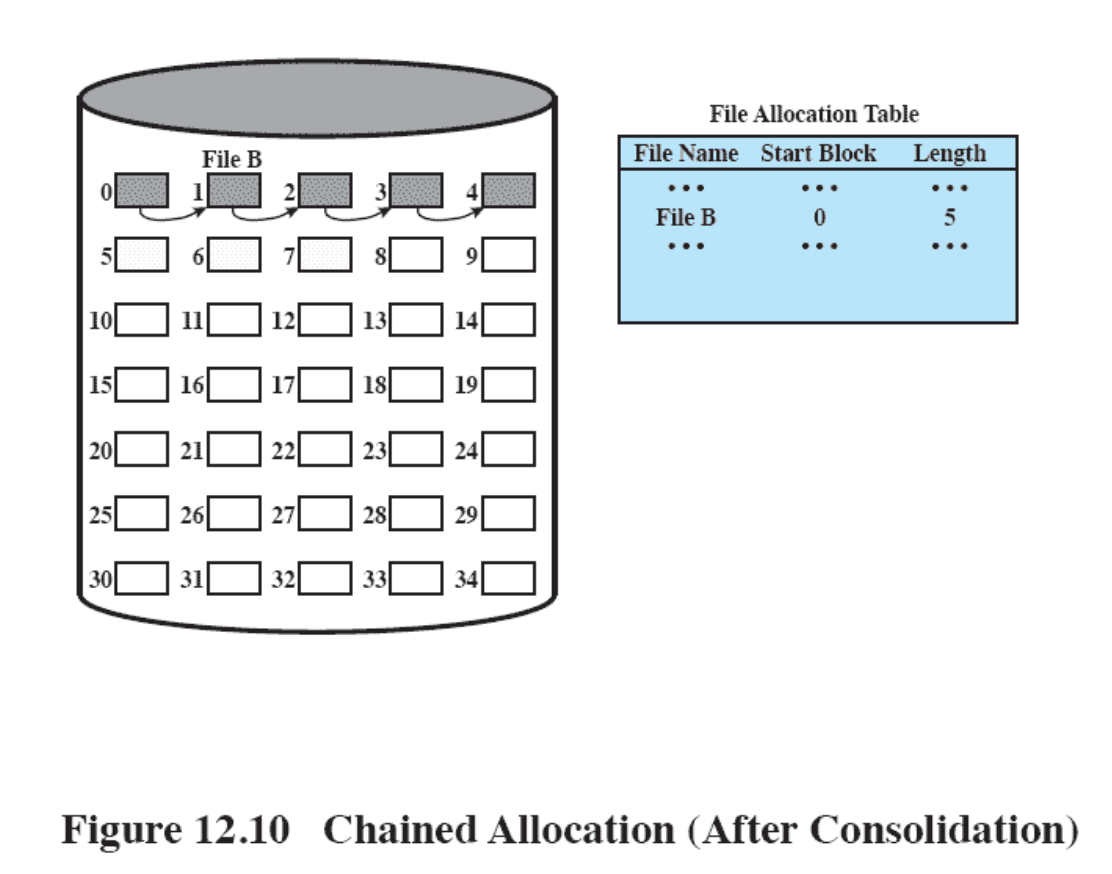
Indexed Allocation
- File allocation table contains a separate one-level index for each file
- The index has one entry for each portion allocated to the file
- The file allocation table contains block number for the index
Some sort of compaction. Just read the textbook I guess.
- You have an index block and tells you the length, where you are etc.
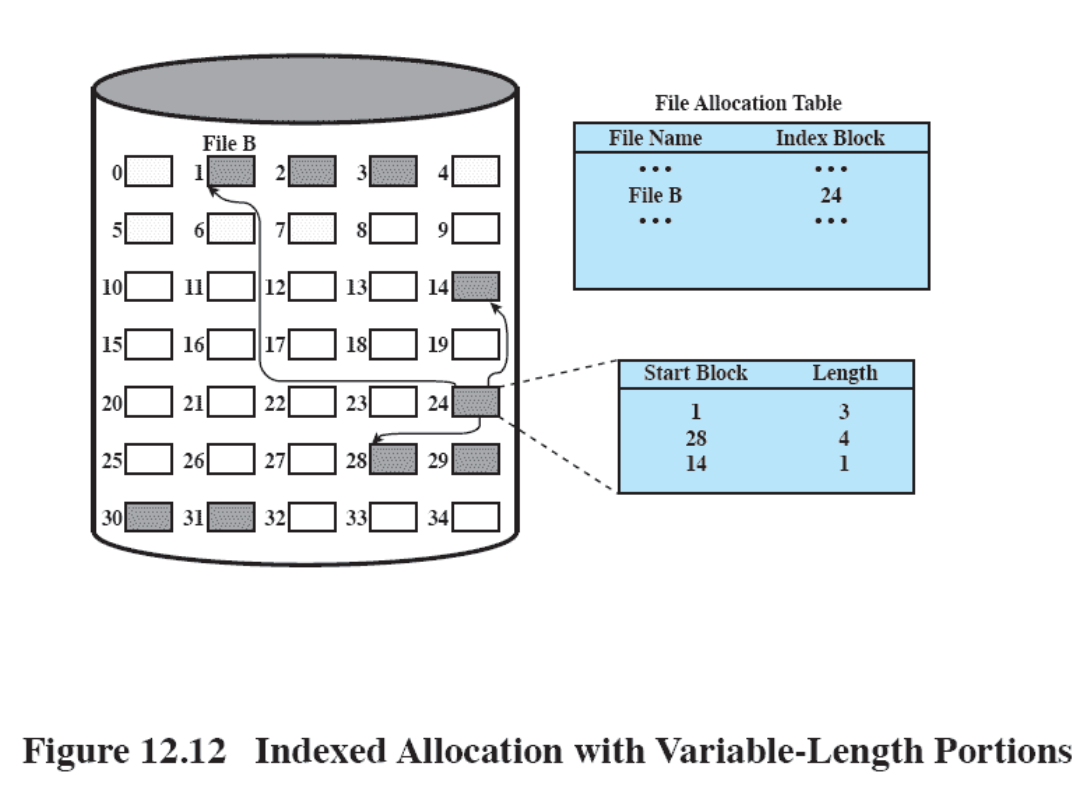
- Disadvantage:
- If you loose the long block (that first one there at 24 in the picture), you loose everything
Access Matrix (security topics)
- Don’t need those big matrixes.
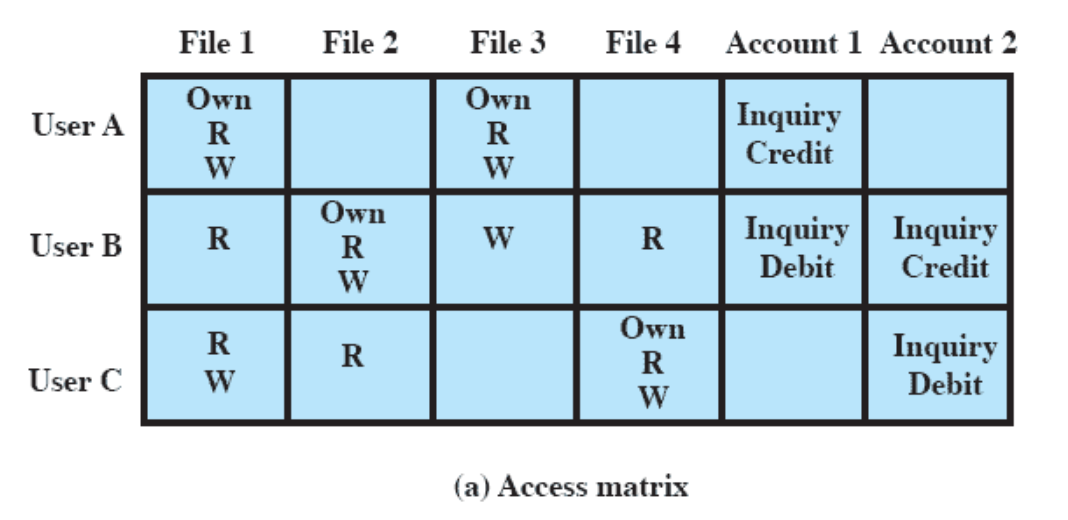
Access Control List
- Store all the info for every files as a list to note down who has access to a particular file.
- Portable (so prof says he would do it this way)
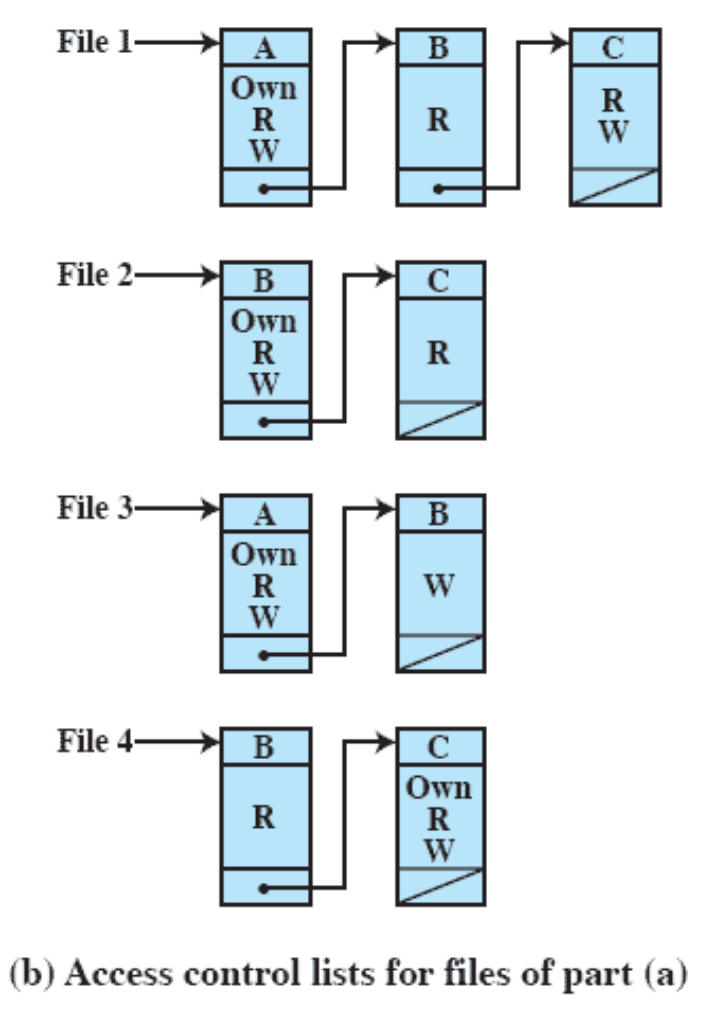
Capability Lists
- The opposite of the access control list, here we have a list for every user.
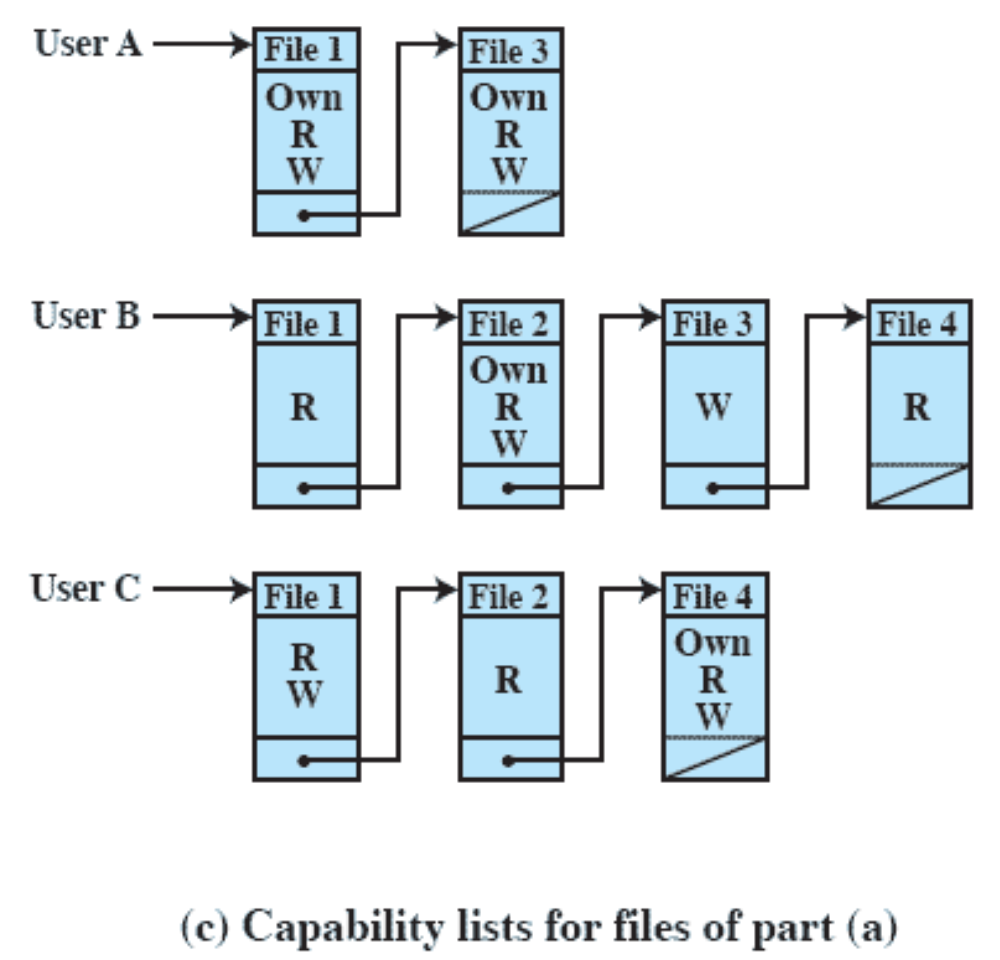
Proceeds to show us some demos:
- Dining philosophers demo showed already
- Busy waiting on the signals vs. non busy waiting
- Interrupt introduces latency in the system.
- dd: allows you to create files
- taskset: limit a process to use limited CPUs (cores), that way you can decrease the CPU used per instance.
On a single core, you will see a speedup if you have io-bound, because the system will be suspended. multiprogramming and multi
Do you achieve a speedup with i-o bound workload, with multiple threads? Depends on the threading mechanism. If you have user level thread, it won’t give you any advantages even on single core. System will get suspended whenever any threads makes an IO call. However, kernel threads, you can achieve a speedup.
The End.