DeepSeek
DeepSeek is a Chinese company involved in AI and LLMs. They have released several models, like DeepSeek-R1 and DeepSeek LLM.
Officially launched in 2023. The company introduced its advanced AI models, such as the DeepSeek LLM, and launched services like its AI chatbot around August 2023.
From their twitter on Jan 20 2025
- Performance on par with OpenAI-o1 ![📖]
- Fully open-source model & technical report ![🏆]
- MIT licensed: Distill & commercialize freely!
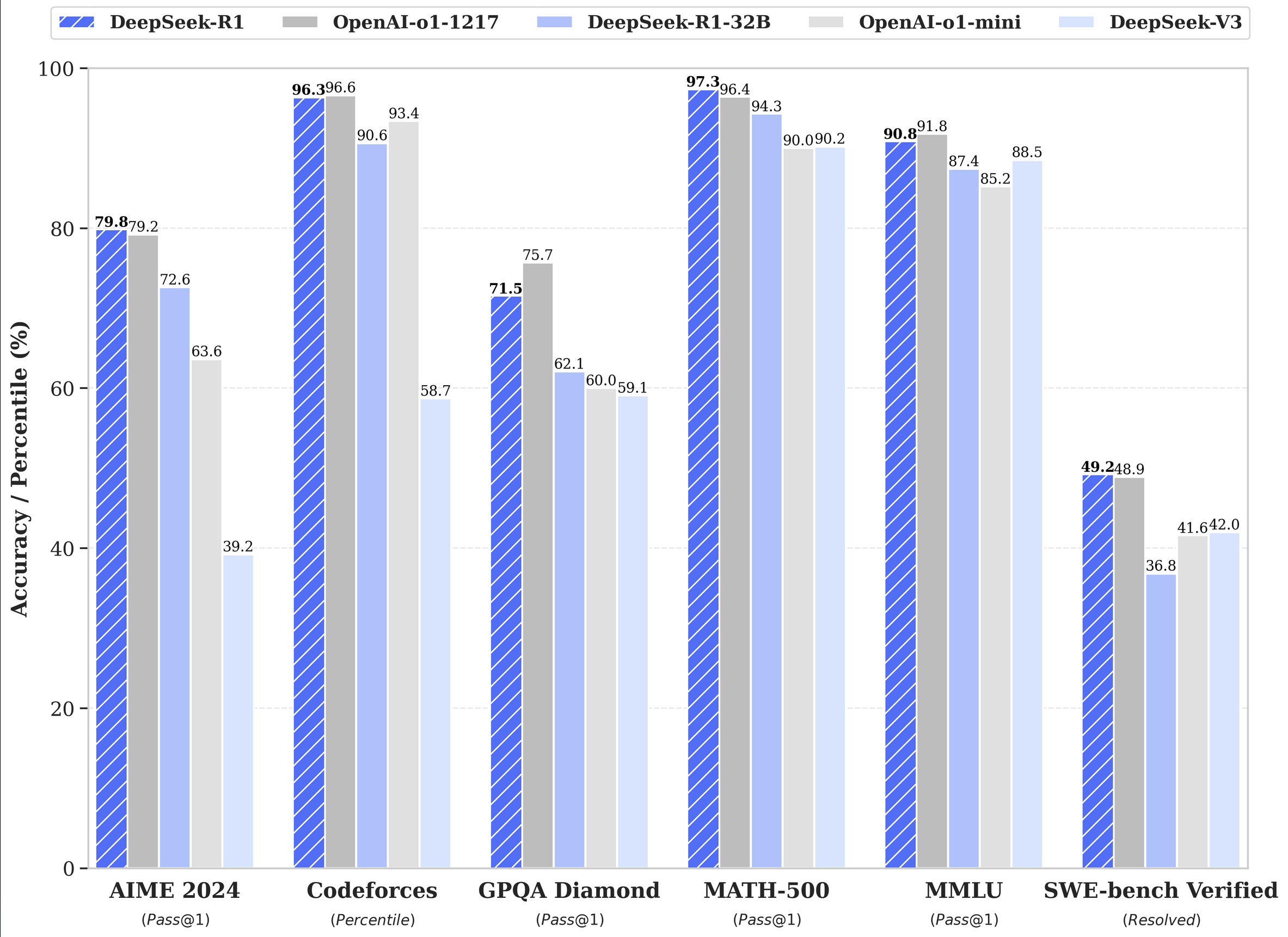
DeepSeek R1 benchmark shows that performs at a similar to open ai o1 model.
This AI model developed amidst U.S. sanctions on China for NVIDIA chips, which were intended to restrict the country’s ability to develop advanced AI is quite amazing.
How DeepSeek works
Paper: DeepSeek Technical Report
- Chain of Thoughts
- Prompt += “explain step by step”.
- We don’t give it the answer and in the same way reinforcement learning allows us to train a model by optimizing its policy AKA how the model behaves, does so to maximize the reward, and as it explores its environment through time and sees which policy maximizes the reward.
- Exactly how robots learn how to walk, and how Tesla’s self driving car learned how to drive through the city.
- Use chain of thought reasoning to force the model to self-reflect and evaluate to change its behaviour to get closer to a max reward. That way we can kind of give the model the right incentive using prompts and the model can re-evaluate answers respond how it answers questions and by increasing accuracy.
- Reinforcement Learning
- Uses Group relative policy optimization: use this equation to score how well it answered a question without having the correct answer.
- Don’t want to change the policy too much, to make sure model is stable enough. By clipping it we can achieve that in the equation. And also the minus term. But we still want to compare old answer to the new answer, then maximize the reward from the policy changes that are minimized.
- Model Distillation
- The idea: 671 B parameters, to make it more accessible, they used a larger LLM and then they use it to teach a smaller LLM how it reasons and answer questions. THat way the smaller LLM can perform on the same level as the bigger LLM but at a magnitude of a smaller parameter size like 7B parameter size.
- The researchers at DeepSeek distilled from their deepseek model into llama 3 as well as quem. The idea uses Chain of Thought reasoning in order to generate examples and it answers quesitons. The examples are given directly to the student (7B) as part of the prompt, then the student is supposed to answer the question in similar accuracy as the larger model.
- Makes the whole LLM ecosystem more accessible.
- Key insight: in the paper they found that student model during reinforcement training outperforms the teacher model, by a little bit. It does it with a small fraction of the memory and storage required to use it.
Try out DeepSeek
Ollama link for local use: https://ollama.com/library/deepseek-r1
Their API platform is currently down :(