Hashing
Hash functions accept a key and return an output unique only to that specific key.
- Know as hashing, which is the concept that an input and an output have a one-to-one correspondence to map information.
- Hash functions return a unique address in memory for that data.
A hash function takes a key value and calculates a valid bucket index.
We want to use hashing to get constant operation time . That is the main goal.
However, there might be Hash Collision.
Two disadvantages of direct addressing:
- It cannot be used if the keys are not integers
- It wastes space if is unknown or
Hashing idea: Map (arbitrary) keys to integers in range and the use direct addressing.
Details:
- Assumption: We know that all keys come from some universe .
- We design a hash function
- Store dictionary in hash table, i.e. an array of size of
- An item with key should ideally be stored in slot i.e. at
- Rehash takes time.
Hash Collision
When two pieces of data in a hash table share the same hash value.
Many key that goes into a hashing function can come out, that is map to the same integer.
- Example: if mod
Thus, we get collisions: that is when we want to insert into the table, but is already occupied.
We will look at strategies to resolve collisions!
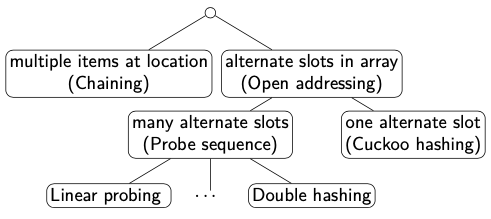
Chaining:
- Hashing with Chaining Open addressing:
- Probe Sequence
- Cuckoo Hashing
Complexity of open addressing strategies
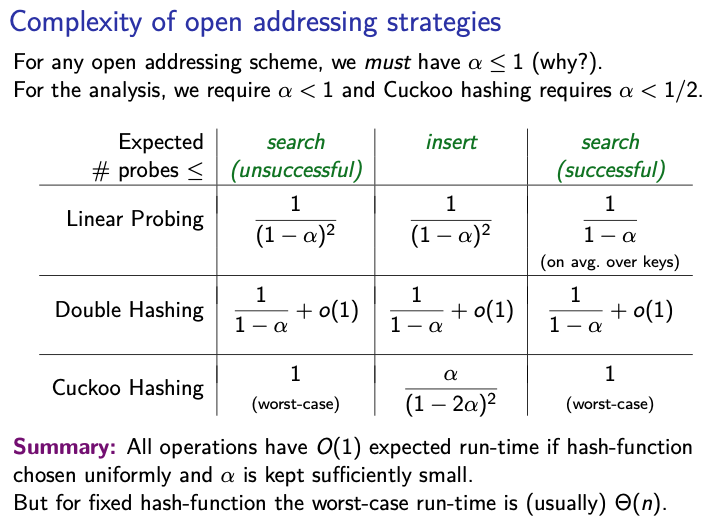 Really only need to remember Cuckoo Hashing search unsuccessful and successful .
All of them except for hashing with chaining depends on the load factor being less than 1.
So for example, if the is close to 1, then the search operation (using linear probing) does not have a constant average-case running time.
Really only need to remember Cuckoo Hashing search unsuccessful and successful .
All of them except for hashing with chaining depends on the load factor being less than 1.
So for example, if the is close to 1, then the search operation (using linear probing) does not have a constant average-case running time.
Hash Function Strategies

What is the desired property of a randomly chosen hash function ?
- for all keys and slots
- This means that it uniformly distributes the keys from the universe across all the slots in the hash table of size . In other words, for any key and any slot in the hash table, the probability is . The reason for this property is to achieve “uniform hashing assumption”. It means that each slot is equally likely to be chosen for any given key. This uniformity ensures that the elements are evenly spread throughout the hash table, minimizing the number of collisions. Crucial for achieving average-case time complexity for hash table operations like insertion and search.

Choose BST if we want guarantee, but Hash Tables cannot guarantee, but is faster usually in the worst-case for search and delete.

